企查查天眼查企业电话工商信息经营状况知识产权公司背景等Python爬虫采集获取
第一篇:企查查搜索列表基本信息(天眼查类似)
目标:批量抓取企查查上企业的任何信息,包括企业名称、电话、地址、邮箱、工商信息、股东信息、对外投资、动产抵押、税务评级、知识产权(商标信息、专利信息、软件著作权、网站备案)等等,可根据省份城市、行业分类、手机号码、纳税登记、融资信息等条件进行筛选。
环境:Windows 7 + Python3.6 + Pycharm2019
爬虫步骤:链接分析、请求链接、数据获取、数据存储。
1、链接分析
分析工具:Chrome Network分析工具
企查查链接:https://www.qcc.com/
企查查搜索列表链接分析
未登录搜索结果,电话显示不全,点击更多邮箱显示需要登录:
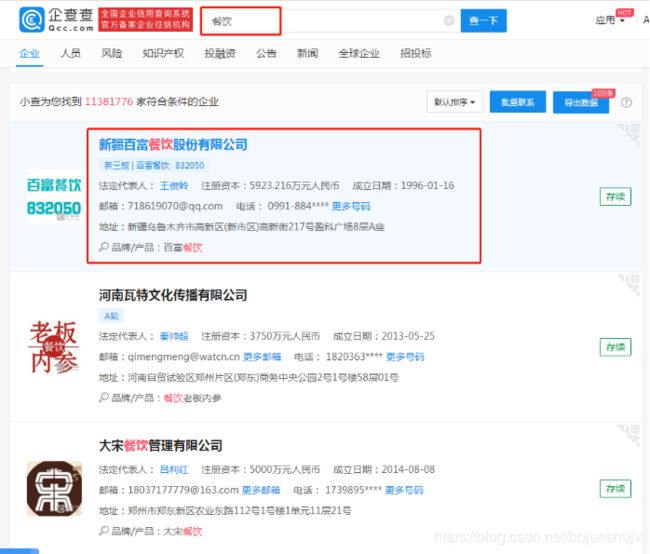
使用手机验证码登陆后搜索结果为:
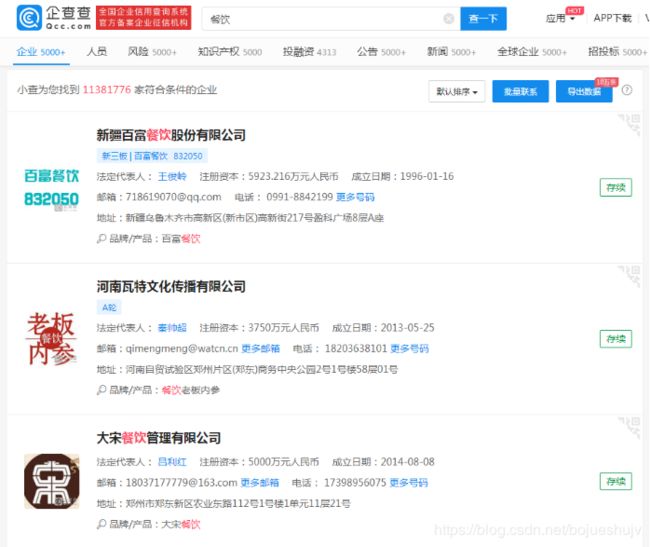
从结果可以看出,登录后可以看到一个电话,可以点击更多邮箱获取更多的邮箱,但是点击更多号码显示需要购买VIP才能获取更多。
不管是要获取多少个电话,首要的问题是先解决登录问题。
有两种方式可以解决登录问题:
- selenium库 + chrome插件模拟登录,不过现在selenium可以被大多数网站识别为机器操作。
- pyautogui模拟鼠标键盘操作,完全屏蔽网站的识别,验证滑块也都非常简单。不过程序运行中人为操作鼠标和键盘可能会影响运行结果。
批量获取时需要有大量已登录好的cookie,才能快速获取数据。
搜索链接如下所示,第一次搜索时没有页面参数:
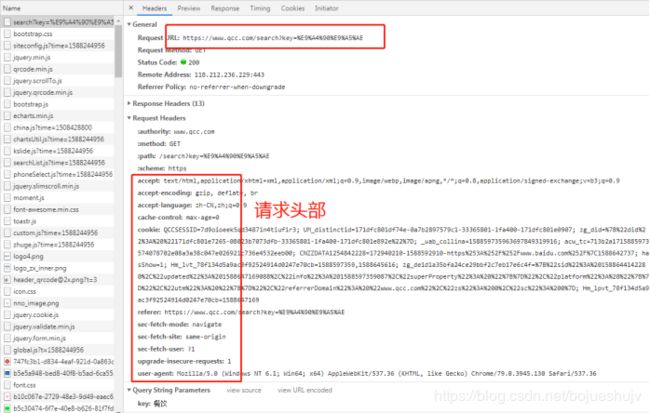
https://www.qcc.com/search?key=%E9%A4%90%E9%A5%AE,其中,%E9%A4%90%E9%A5%AE为餐饮的编码。
企查查第二页搜索时,p为页数参数:
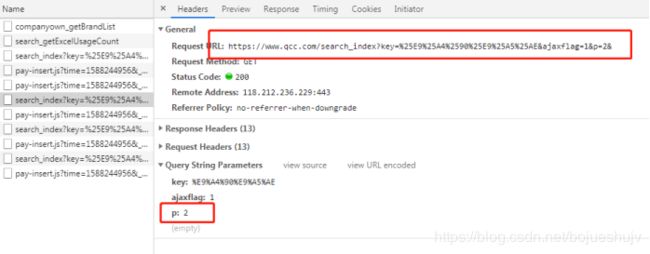
# 首页链接
self.search_url = 'https://www.qichacha.com/search?key=' + keyword
# 分页搜索链接
self.search_page_url = self.search_url + '&ajaxflag=1&p=%s&' % page_num
2、请求链接
请求企查查搜索列表时请求头部需要带上相应的参数,如上上图中所示。
企查查搜索列表首页的请求代码如下所示,由于整体代码篇幅较长,展示部分代码仅供参考:
class QiChaChaSearch:
"""企查查搜索获取每个关键词的第一个结果
"""
def __init__(self, filename='./data/search_1.xlsx', dowhat='search_link'):
keyword = ''
page_num = 0
# 首页链接
self.search_url = 'https://www.qichacha.com/search?key=' + keyword
# 分页搜索链接
self.search_page_url = self.search_url + '&ajaxflag=1&p=%s&' % page_num
# cookies加载
self.cookies_filename = 'qichacha_cookies.json'
self.cookie_handler = CookieHandler(cookies_filename=self.cookies_filename)
# 头部user_agent加载
self.user_agent = UserAgent(filename='user_agents.txt')
self.get_queue = Queue() # 信用代码队列
self.company_url_save_queue = Queue() # 搜索结果保存队列
start = datetime.now()
filename = './data/公众号/信用代码.xlsx'
self.search_load_gongzhonghao_code(filename)
end = datetime.now()
print(end - start)
self.get_data_all = self.get_queue.qsize()
print('待获取数据:', self.get_data_all)
if self.get_data_all == 0:
return
# 代理
self.all_proxy = AllProxy(pool_type='only_new')
thread_list = []
for i in range(120):
t_nolonger = threading.Thread(target=self.search_company_link_thread, args=('new', ))
thread_list.append(t_nolonger)
# 保存数据
for i in range(1):
t_save = threading.Thread(target=self.search_company_link_save_thread, args=(i,))
thread_list.append(t_save)
for t in thread_list:
t.setDaemon(True) # 把子线程设置为守护线程,该线程不重要主线程结束,子线程结束
t.start()
def parse_qichacha_url(self, url, ip_port, proxies):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Upgrade-Insecure-Requests': '1',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'referer': 'https://www.qcc.com/search?key=91653123MA7AA7JQ6Y'
}
status_code = 202
# for i in range(3):
try_cnt = 0
while try_cnt < 3:
try:
try_cnt += 1
cookies = self.cookie_handler.get_cookie_dict()
headers ['User-Agent'] = self.user_agent.get_random_user_agent()
res = requests.get(url, headers=amazon_headers, timeout=30, proxies=proxies, cookies=cookies, verify=False)
if res.status_code == 200:
# 出现机器识别
# print(res.text)
if 'index_verify' in res.text:
print('index_verify')
# timesss = str(random.randint(0, 10000000)) + '.html'
# print(timesss, url)
# with open(timesss, 'w', encoding='utf-8') as f:
# f.write(res.text)
break
elif '会员登录 - 企查查' in res.text:
print('会员登录')
continue
else:
return res.text
elif res.status_code in [429, 403, 503, 500]:
print(" XXXXX status_code: %s" % res.status_code)
break
except Exception as err:
print(" XXXXX Exception", err)
break
return None
def search_get_company_url(self, ip_port, proxies, url_list: list, proxy_type):
url = 'https://www.qichacha.com/search?key=' + str(url_list[1])
while True:
try:
# if True:
# ip_port, proxies = self.get_proxy_from_pool()
html_str = self.parse_qichacha_url(url, ip_port, proxies)
# print(html_str)
if html_str is not None:
html = etree.HTML(html_str)
if html is not None:
tmp = html.xpath('//tbody[@id="search-result"]//tr[1]/td[3]/a/@href')
counts_str = str(tmp[0].strip()) if len(tmp) else ''
if counts_str != '':
temp = html.xpath('//tbody[@id="search-result"]//tr[1]/td[3]/a//text()')
name_str = ''
for e_ in temp:
name_str += e_.strip()
self.company_url_save_queue.put([url_list[0], url_list[1], counts_str, name_str])
print('----')
break
else:
count = html.xpath('//span[@id="countOld"]/span[@class="text-danger"]/text()')
if len(count):
counts_str = count[0].strip()
print('符合条件的企业', counts_str)
self.company_url_save_queue.put([url_list[0], url_list[1], counts_str])
break
if proxy_type == 'pool':
ip_port, proxies = self.get_proxy_from_pool()
else:
ip_port, proxies = self.get_new_proxy()
except Exception as err:
print('get_data_by_url:', err)
LOGGER.exception(err)
pass
# 返回可用的代理
return ip_port, proxies
def search_company_link_thread(self, proxy_type='pool'):
if proxy_type == 'pool':
ip_port, proxies = self.get_proxy_from_pool()
else:
ip_port, proxies = self.get_new_proxy()
while True:
url_list = None
try:
url_list = self.get_queue.get()
self.get_queue.task_done()
ip_port, proxies = self.search_get_company_url(ip_port, proxies, url_list, proxy_type)
# time.sleep(random.randint(1, 3))
time.sleep(random.randint(2, 5))
except Exception as err:
print('search_company_link_thread:', err, url_list)
def search_company_link_save_thread(self, index=0):
file_path = './data/公众号/'
file_num = 1
basic_filename = file_path + 'url' + str(index) + '_' + str(file_num) + '.xlsx'
wb_basic = Workbook()
ws_basic = wb_basic.active
file_num += 1
all_cnt = 0
old_cnt = 0
while True:
try:
# if True:
time.sleep(10)
try:
while True:
data_save = self.company_url_save_queue.get_nowait()
self.company_url_save_queue.task_done()
ws_basic.append(data_save)
all_cnt += 1
except:
pass
if all_cnt != old_cnt:
wb_basic.save(basic_filename)
print('%s 总数%s 待抓取%s 速率%s 剩余ip%s' % (index, all_cnt, self.get_queue.qsize(), (all_cnt - old_cnt)/10, self.all_proxy.get_new_proxy_queue.qsize()))
old_cnt = all_cnt
except Exception as err:
print('search_company_link_save_thread:', err)
3、数据获取
企查查搜索列表请求到的是网页数据,使用lxml.etree解析之后,搜索的数据都是在xpath:’//tbody[@id=“search-result”]'的元素里面,逐一获取即可。上面代码中只获取了搜索结果的链接,是为了直接进入详情页以获取更多的数据。
前面的企查查搜索查询是没有使用任何条件筛选的,实际根据不同的任务需求,可以增加条件筛选的功能。

常用的条件筛选有省份城市、行业分类、手机号码、纳税登记、融资信息等等。
4、数据存储
可根据需要保存到mongoDB数据库,或者MySQL数据库,也可直接保存为表格文件。