python之XlsxWriter
背景
最近工作中用到了写excel文件的功能, 发现了这个包.
记录下相关用法及注意事项.
环境
系统环境:
/ # python -V
Python 2.7.16
/ # pip list
...
XlsxWriter 1.1.9
...
API
由于excel操作非常复杂, 这个包的api也非常多. 下面就我用到的一些说说.
import xlsxwriter
# 创建工作薄
workbook = xlsxwriter.Workbook("config.xlsx")
# 设置整个工作薄的格式
workbook.formats[0].set_align('vcenter') # 单元格垂直居中
workbook.formats[0].set_text_wrap() # 自动换行
# 在工作薄中添加工作表
worksheet = workbook.add_worksheet("Sheet1")
# 创建一种样式, 后续可以应用于单元格等区域
FORMAT_DIFF_COLOR = workbook.add_format({
'font_color': 'red',
'text_wrap': 1,
})
# 在(0, 0)单元格(也就是A1)写入文字, 最后一个参数为样式, 可省略
worksheet.write_string(0, 0, "提示:", FORMAT_DIFF_COLOR)
# 其他操作 ...
# 关闭, 非常重要, 不可省略
workbook.close()
更多方法在官网查看
注意事项
worksheet有一大堆往单元格里写数据的方法,

write_rich_string()方法有些特别, 稍候说.
其他几个write_xxx()方法以write()方法为核心, 格式可总结为:
write_xxx(rowIndex, columnIndex, content[, format])
4个参数分别为, 第几行, 第几列, 要写入的内容, 此单元格的格式(可省略).
其中行和列从0开始算.
如在A1单元格写入红色的"hello"
worksheet.write(0, 0, "hello", workbook.add_format({
'font_color': 'red'
})
再来说说write_rich_string()方法, 这个方法是向单元格中写入富文本的, 比如一个格子里, 即有加粗的字, 又有红色的字, 并且交错的:
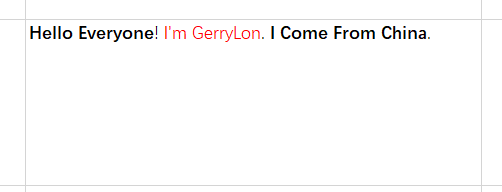
此时write_rich_string()就用上了, 其一般格式为:
write_rich_string(rowIndex, columnIndex[, format1], content1[, format2], content2[, format3, conetnt3...])
其中format1修饰的是content1, format2修饰的是content2, …
最少要5个参数(不然你用别的方法去吧!), 可以全部不用格式(此时全部会采用默认格式).
对上图中的格式, 就可以这样写:
worksheet.write_rich_string(0, 0,
fmt_bold, "Hello Everyone!",
fmt_red, " I'm GerryLon",
fmt_bold, " I Come From China.")
其中fmt_bold和fmt_red可以用workbook.add_format()方法来创建.
下面是我封装的write_rich_string()方法:
支持写多行, 每行中多个单词可以自定义格式
# arg_rich_strings可能的形式有:
# "str", [], {}, ["str"], [{}], [[{}, "str"], [{ct: xx, fmt: yy}, {}]], ...]
def write_rich_string(worksheet, row, column, arg_rich_strings):
args = [row, column]
n = len(arg_rich_strings)
if n == 0: # 如果为空, 这个单元格不写入东西
# print "empty arg_rich_strings in row:", row, "type(arg_rich_strings)", type(arg_rich_strings)
return
content_arr = []
if type(arg_rich_strings) == str:
content_arr = [[arg_rich_strings]]
elif type(arg_rich_strings) == dict:
content_arr = [[arg_rich_strings]]
elif type(arg_rich_strings) == list:
content_arr = arg_rich_strings
else:
print "unsupported type(arg_rich_strings)", type(arg_rich_strings)
return
all_lines = []
# 数据预处理. i为行号, words为一行单词
for i, words in enumerate(content_arr):
one_line = [] # 一行的内容
not_last_line = i < len(content_arr) - 1
if type(words) == str: # 某一行整体为字符串, 直接采用默认格式
one_line = [{
"ct": words,
}]
elif type(words) == dict: # 可能为: [{fmt:xx, ct:xx}]
one_line = [words]
elif type(words) == list: # 某一行为数组(多个单词)
tmp_words = []
for j, word in enumerate(words):
not_last_word = j < len(words) - 1
if type(word) == str: # 默认格式的单词
tmp_words.append({
"ct": word + (" " if not_last_word else ""),
})
elif type(word) == dict:
word["ct"] = word.get("ct", "") + (" " if not_last_word else "")
tmp_words.append(word) # 这个word应该是类似{fmt:xx, ct:xx}这样的
else:
print "unsupported word type:", type(word)
print "unsupported word type:", words
print "unsupported word type:", content_arr
return
one_line = tmp_words
# 行末尾加换行符
if not_last_line and len(one_line) > 0:
one_line.append({
"ct": "\n"
})
if len(one_line) > 0:
all_lines.append(one_line)
for line in all_lines:
for word in line:
fmt = word.get("fmt", None)
ct = word.get("ct", "")
if fmt:
args.append(fmt)
args.append(ct)
if len(all_lines) == 0:
print "empty all_lines,row:", row, "arg_rich_strings:", arg_rich_strings
return
# print "write in row:", row, "args:", args
n_args = len(args)
if n_args <= 4:
ret_code = worksheet.write(*args)
if ret_code != 0:
print "write not success, ret_code=", ret_code, "args=", args
return
ret_code = worksheet.write_rich_string(*args)
if ret_code != 0:
print "write_rich_string not success, ret_code=", ret_code, "args=", args
欢迎补充指正!