RAM: Recurrent Models of Visual Attention 学习笔记
- 论文解析
- Torch代码
- Glimpse Network
- hidden layer
- locator
- attention network
- Agent
- parameter setting
- TF实践
论文解析
看了论文【1】和博客【9】【10】,我对RAM进行总结。要看懂这篇论文,需要强化学习中的policy-based learning和RNN的相关知识。如果对policy gradient,policy function等等概念不清楚的话,看论文就只能从字面上理解。对RL,RNN方面的介绍,可以看我之前的博客以及博客里面推荐的论文看看。其实这个RAM真的是属于很简单的模型,里面用到的RNN居然还是SimpleRNN,我在看Torch源码的时候,发现这个RNN连hidden layer都没有(但是在Torch的源码里面索引的论文是有一个hidden layer的,当然可能是我看源码的时候看错了,非常有可能,看我的这篇博客:RNN以及Torch中的实现)RL采用的是Policy-based model,论文是九几年的,果然很有年代感。在对policy-based model这里可以看我的博客policy gradient 推导,不看这些推导根本不知道为什么要加入baseline,以及更新的时候为啥使用的是gradient ascent的方法。另外我会解释一下代码中的minibatch,momentum,step,dropout,normalization这些概念,毕竟调参优化需要了解。
RAM model讲得是视觉的注意力机制,说人识别一个东西的时候,如果比较大的话,是由局部构造出整体的概念。人的视觉注意力在选择局部区域的时候,是有一种很好的机制的,会往需要更少的步数和更能判断这个事物的方向进行的,我们把这个过程叫做Attention。由此,我们把这个机制引入AI领域。使用RNN这种可以进行sequential decision的模型引入,然后因为在选择action部分不可导,因为找到目标函数无法进行求导,只能进采样模拟期望,所以引入了reinforcment leanrning来得到policy进而选择action。先说一下recurrent attention model如何实现,然后再说一下可以运用在哪些地方,以及相比别的现有的方法有什么优势。
首先介绍RAM的大致的架构:
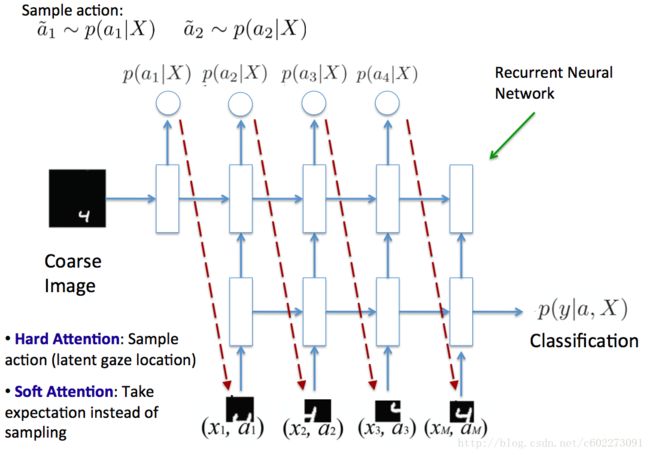
首先输入时一副完整的图片,一开始是没有action的,所以随机挑选一个patch,然后送入了RNN网络中,由RNN产生的输出作为action,这个action可以是hard attention,就是根据概率a~P(a|X)进行采样,或者是直接由概率最大的P(a|X)执行。有了action以后就可以从图片中选择某个位置的sub image送到RNN中作为input,另外一方面的input来自于上一个的hidden layer的输出。通过同样的网络经过T step之后,就进行classification,这里得到了最终的reward,(把calssification是否判断正确作为reward)就可以进行BPTT,同时也可以根据policy gradient的方法更新policy function。可以发现这个网络算是比较简单,也只有一个hidden layer,我觉得应该是加入了RL之后比较难训练。
接下来进一步解释网络,因为具体的网络输入输出是啥,维度多少,具体操作都没有说清楚。根据论文中的图来解释:
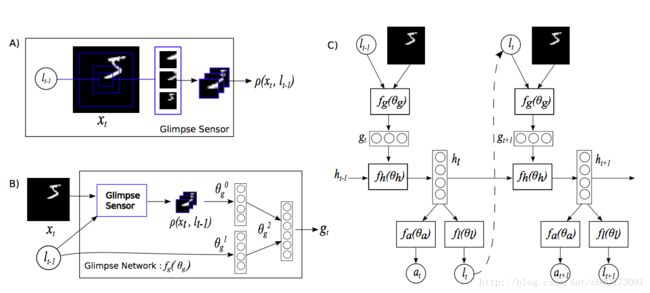
- 图A:此部分称之为Glimpse Sensor,也就是感应器,其实就是给定一个图片的location(坐标,这个坐标为中心),采集一副大的图片的子图,因为使用的MNIST的图片,所以只有一个通道,黑白。另外,采集图片的尺寸不一样,有的图片采集的scale更大,从A中来看是采集了三个size的图片,然后进行sub-smapling获得同意尺寸的图片8x8(在Torch代码中,这个下采样图片个数变成了2)所以输入的locator(定位器) lt+1 和整副图片 xt ,得到了进行采样之后的n个子图片表达 p(xt,lt−1)
- 图B:总的输出是 gt ,由两部分的feature进行连接得到。其中 θ0g 是由图A中的p通过一个linear regression得到, θ1g 是由locator通过linear regression得到。
- 图C:这里面有一个RNN,图B得到的 gt 通过了linear regression,ReLU得到,然后 gt 通过linear regression得到 fh (RNN中的hidden layer,可以用于下一次的输入以及当前的输出),然后将 ht 通过locator的网络,用于计算下一个输入的locator(具体操作看下一个section)。在这个网络里面,和普通RNN会有些不同,普通的RNN是不会把输出 lt−1 和hidden layer同时保留进行计算的,一般是保留一个。这里要注意的就是 lt−1 这部分的权值更新是没有监督学习的,只是根据reward进行gradient ascent。就是让这部分的权重更新的方向是更加接近positive reward。如果是negative reward就远离。
所以总结一下,在这个网络里面,有Sensor( gt ),Locator( lt ),Calssification,RNN这些component。在具体到数字维度的网络结构会在下面的section解释。
网络结构清楚以后接下来就是如何训练了。因为在这里引入了思想是RL的想法,这里的优化目标变成了最大化reward,也就是:

加入log,同样成立:M就是进行M次的采样,这就是RL中的MC估计return value。
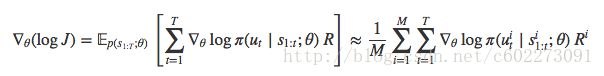
在这个网络中,采用了RNN模型,其实只有在时刻T才有reward,所以直接变成了可以发现这里的 Ri 与t没有关系。另外,这里的policy π 已经有了policy function,可以进行显性gradient ascent。看第一幅图,在时刻T的时候,agent知道了classification的正确与否,然后就得到了reward,通过这个进行BPTT,同时也就更新了policy function的weight。这里有M次的采样,其实是这样的,把这个网络的权值一样的拷贝M次,计算出来的权值再取均值进行gradient update。因为这M次的起始位置都是不一样的,或者是采取action的时候采取了sampling的方法。导致policy不是确定的,但是从代码来看,应该是起始位置不同的,通过多次采样来获取期望。
在计算梯度的时候,RL中需要加入baseline,为什么加入baseline呢?因为原函数的variance特别大,而且我们想要看到的是在某个状态下,采取的action是否得当,没有baseline去掉state value的话,就无法判断出一个action的好坏,选取action更多与state value有关。而且state value都是正的,求导的时候都是正的或者是0,这样的话policy function无法对negative reward进反应。所以加入了baseline以后,可以对不好的action也可以进行反馈。一般来说,baseline采用的就是state value。这里的reward R其实是action value。
如果还想再深入理解算法,如何优化,看Deep Mind的另外一篇文章,发在Nature上,同一个东西拆成两部分来。
Torch代码
在RAM中,整个代码将结构表示如下:【12】
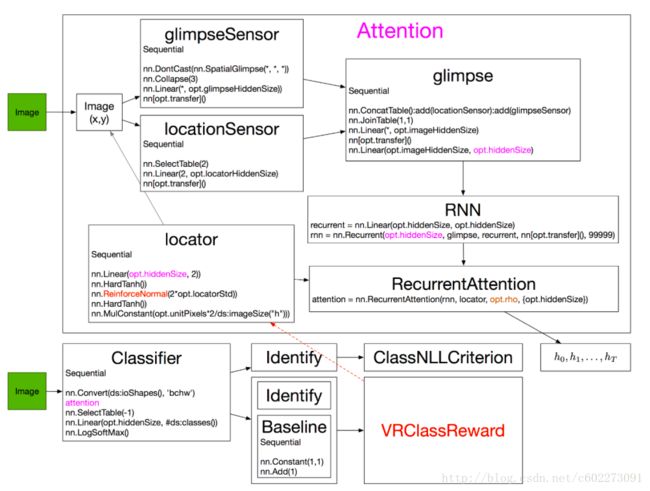
在代码解释上,我发现【11】解释得不错,这里主要是索引了他的。
Glimpse Network:
输入:图像I和观察位置L
输出:进行采样的图片

这部分代码我看了解释才知道,有两部分组成,存进了table里面。
左边的location进行linear regression:
locationSensor:add(nn.SelectTable(2)) --选择两个输入中的第二个,位置l
locationSensor:add(nn.Linear(2, opt.locatorHiddenSize)) --Torch中的Linear指全连层
locationSensor:add(nn[opt.transfer]()) --opt.transfer定义一种非线性运算,本文中是ReLU右边提取的是对图片进行处理的feature:
glimpseSensor:add(nn.SpatialGlimpse(opt.glimpsePatchSize, opt.glimpseDepth, opt.glimpseScale):float()) --SpatialGlimpse提取小块金字塔
glimpseSensor:add(nn.Collapse(3)) --压缩第三维
glimpseSensor:add(nn.Linear(ds:imageSize('c')*(opt.glimpsePatchSize^2)*opt.glimpseDepth, opt.glimpseHiddenSize))
glimpseSensor:add(nn[opt.transfer]())接着两个合并连在一起:
glimpse:add(nn.ConcatTable():add(locationSensor):add(glimpseSensor))
glimpse:add(nn.JoinTable(1,1)) --把串接数据合并成一个Tensor
glimpse:add(nn.Linear(opt.glimpseHiddenSize+opt.locatorHiddenSize, opt.imageHiddenSize))
glimpse:add(nn[opt.transfer]())
glimpse:add(nn.Linear(opt.imageHiddenSize, opt.hiddenSize)) --从imageHiddenSize到hiddenSize的全连层这里的Table我看了很久才知道:
Torch的基础数据是Tensor,而lua中用Table实现类似数组的功能。nn库中专门有一系列Table层,用于处理涉及这两者的运算。例如:
ConcatTable - 把若干个输出Tensor放置在一个Table中。
SelectTable - 从输入的Table中选择一个Tensor。
JoinTable - 把输入Table中的所有Tensor合并成一个Tensor。hidden layer
这部分的处理就是RNN中hidden layer的处理:
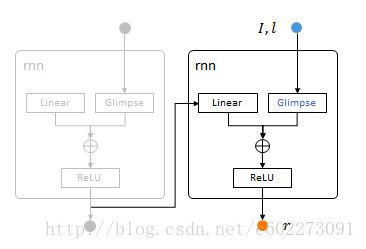
recurrent = nn.Linear(opt.hiddenSize, opt.hiddenSize)
rnn = nn.Recurrent(opt.hiddenSize, glimpse, recurrent, nn[opt.transfer](), 99999)这里的Recurrent就是SimpleRNN,直接把输出作为了输出作为下一个输入的一部分。这里的Recurrent第一个参数就是输出的hidden layer的size,第二个glimpse就是对输入的处理。第三个参数就是对输出进行处理送到下一层作为输入的时候的操作(linear regression),第四个参数是RNN中的Step的设置。
locator
将上面的RNN的输出作为locator的输入,计算出下一个获取图片的位置。
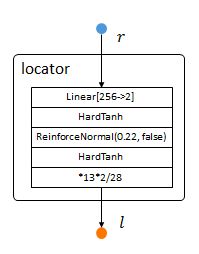
locator:add(nn.Linear(opt.hiddenSize, 2))
locator:add(nn.HardTanh()) -- bounds mean between -1 and 1
locator:add(nn.ReinforceNormal(2*opt.locatorStd, opt.stochastic)) -- sample from normal, uses REINFORCE learning rule
locator:add(nn.HardTanh()) -- bounds sample between -1 and 1
locator:add(nn.MulConstant(opt.unitPixels*2/ds:imageSize("h"))) --对位置l做了归一化:相对图像中心的最大偏移为unitPixel。ReinforceNormal层在训练状态下,会以前一层输入为均值,以第一个参数(2*opt.locatorStd)为方差,产生符合高斯分布采样结果;
在训练状态下,如果第二个参数(opt.stochastic)为真,则以相同方式采样,否则直接传递前一层结果。
简单来说,Reinforce层的作用是:在训练时,围绕当前策略(前层输出),探索一些新策略(高斯采样)。具体怎么训练在下篇再说。
attention network
最后是整个大的网络,因为locator的输出还需要连接到输入,以及定义一个大的RNN类型的网络。
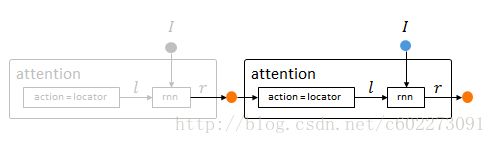
attention = nn.RecurrentAttention(rnn, locator, opt.rho, {opt.hiddenSize})Agent
到目前为止,已经把attention model给建好了,但是发现还没有加入reward部分,reward部分是由Agent定义的,Agent的定义如下:

在前面attention网络的基础上,只对系统循环变量做简单非线性变换,即得到图像属于各类字符的概率p。agent:add(attention)
agent:add(nn.SelectTable(-1))
agent:add(nn.Linear(opt.hiddenSize, #ds:classes()))
agent:add(nn.LogSoftMax()) -- 这里输出分类结果由于系统中存在强化学习层ReinforceNormal,所以需要一个baseline变量b。这里利用ConcatTable把b和分类结果合并到一个Table里输出。
seq:add(nn.Constant(1,1))
seq:add(nn.Add(1))
concat = nn.ConcatTable():add(nn.Identity()):add(seq)
concat2 = nn.ConcatTable():add(nn.Identity()):add(concat)
agent:add(concat2)整个系有两组输出:分类结果p,以及分类结果+baseline对{p,b}。
parameter setting
其实代码的话就基本上都是可以看懂的,更难的我也看过。但是我对Torch这些操作还是觉得很迷,让我这样写,我觉得很困难,试错成本非常大。
现在说到参数设置:
xp = dp.Experiment{
model = agent, -- nn.Sequential, 待优化模型
optimizer = train, -- dp.Optimizer,训练
validator = valid, -- dp.Evaluator,验证
tester = tester, -- dp.Evaluator,测试
observer = { -- 设定log
ad,
dp.FileLogger(), -- 这部分用于打印结果,debug用
dp.EarlyStopper{
max_epochs = opt.maxTries,
error_report={'validator','feedback','confusion','accuracy'},
maximize = true
}
},
random_seed = os.time(),
max_epoch = opt.maxEpoch -- 最大迭代次数
}train = dp.Optimizer{
loss=..., epoch_callback=..., callback = ..., feedback - ...,sampler = ..., progress = ...
}这里定义了loss:有ParallelCriterion来定义这个操作。神tm并列loss,这个库我觉得写得太抽象,太烂了,所以不要用Torch,用TF或者Keras,PyTorch都没有这么抽象。
loss = nn.ParallelCriterion(true)
:add(nn.ModuleCriterion(nn.ClassNLLCriterion(), nil,nn.Convert())) -- 监督学习:negative log-likelihood
:add(nn.ModuleCriterion(nn.VRClassReward(agent, opt.rewardScale), nil, nn.Convert())) -- 增强学习:得分最高类与标定相同反馈1,否则反馈-1epoch_callback函数设定每个epoch结束时执行的动作,一般用来调整opt中的学习率。这个在训练中叫做:momentum。另外minibatch的意思就是对同一个网络参数用不同的sample进行训练以后,去平均的weight update。
epoch_callback = function(model, report) -- called every epoch
if report.epoch > 0 then
opt.learningRate = opt.learningRate + opt.decayFactor
opt.learningRate = math.max(opt.minLR, opt.learningRate)
if not opt.silent then
print("learningRate", opt.learningRate)
end
end
endcallback是核心函数,更新模型参数:
callback = function(model, report)
if opt.cutoffNorm > 0 then
local norm = model:gradParamClip(opt.cutoffNorm) -- dpnn扩展,约束梯度,有益于RNN
opt.meanNorm = opt.meanNorm and (opt.meanNorm*0.9 + norm*0.1) or norm;
if opt.lastEpoch < report.epoch and not opt.silent then
print("mean gradParam norm", opt.meanNorm)
end
end
model:updateGradParameters(opt.momentum) -- dpnn扩展,根据momentum更新梯度
model:updateParameters(opt.learningRate) -- 根据学习率更新参数
model:maxParamNorm(opt.maxOutNorm) -- dpnn扩展,约束参数范围
model:zeroGradParameters() -- 梯度置零
endsampler决定如何采样,mini-batch gradient的size。
sampler = dp.ShuffleSampler{
epoch_size = opt.trainEpochSize, batch_size = opt.batchSize
}valid是一个dp.Evaluator类成员变量,同样继承自dp.propogator。只需要指明feedback,sampler,progress这三个参数即可。
valid = dp.Evaluator{
feedback = dp.Confusion{output_module=nn.SelectTable(1)},
sampler = dp.Sampler{epoch_size = opt.validEpochSize, batch_size = opt.batchSize},
progress = opt.progress
}最后运行:
xp:run(ds)看完代码之后,就知道其中的网络结构了,可以转成TF。这里我要对Torch继续吐槽,隐藏细节太多了,这个库不好用。另外,Torch在模型转换器ONNX【14】【15】【16】【17】【18】【19】里面支持最烂的。放弃吧~
TF实践
TF的实现里面,我看到了星最多的就是【3】的实现。那就看这份代码就好了,我觉得这个代码写的就清楚很多,结构比较清晰。Torch那个确实不适合一点点看懂,抽象程度太高了。
Useful Links:
1. 论文: https://arxiv.org/pdf/1406.6247.pdf
2. Torch实现的解释: http://torch.ch/blog/2015/09/21/rmva.html#rmva.ref
3. RAM的TF实现1: https://github.com/zhongwen/RAM
4. RAM的TF实现2:https://github.com/hehefan/Recurrent-Attention-Model
5. MULTIPLE OBJECT RECOGNITION WITH VISUAL ATTENTION: https://arxiv.org/pdf/1412.7755.pdf
6. RAM的TF实现3: https://github.com/jtkim-kaist/ram_modified
7. RAM的TF实现4: https://github.com/seann999/tensorflow_mnist_ram
8. RAM的TF实现5: https://github.com/qingzew/tensorflow-ram
9. RAM的博客: http://blog.csdn.net/baidu_17806763/article/details/59595848
10. RAM的解析: http://www.cnblogs.com/wangxiaocvpr/p/5537454.html
11. RAM中代码中了解算法: http://blog.csdn.net/shenxiaolu1984/article/details/51582185
12. Attention Model介绍很不错的博客: http://www.cosmosshadow.com/ml/神经网络/2016/03/08/Attention.html#_label2_3
13. Mastering the game of Go with deep neural networks and tree search: https://www.nature.com/articles/nature16961
14. ONNX: http://onnx.ai/getting-started
15. ONNX: https://github.com/onnx
16. Converter: https://github.com/ysh329/deep-learning-model-convertor
17. Torch Converter: https://github.com/Teaonly/trans-torch
18. ONNX Start: http://onnx.ai/getting-started
19. ONNX TF: https://github.com/onnx/onnx-tensorflow