笔记 - 数据读取:TFRecords 内部多线程读取文件 (一)
资料:
Tensorflow高效读取数据
tensorflow的数据输入
TensorFlow和Keras解决大数据量内存溢出问题
tensorflow的数据输入 - 屌都不会
TensorFlow高效读取数据的方法
Tensorflow TFRecords及多线程训练介绍 ——详细
Google Protocol Buffer 的使用和原理
《21个项目玩转深度学习:基于TensorFlow的实践详解》第2章 CIFAR10与ImageNet图像识别
tf.train.batch和tf.train.shuffle_batch的理解
tf.train.batch和tf.train.shuffle_batch理解以及遇到的问题
Tensorflow中关于FixedLengthRecordReader()的理解
实验:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
label_bytes = 1 # 2 for CIFAR-100
height = 32
width = 32
depth = 3
image_bytes = height * width * depth
data_dir = "C:/Users/Mcdonald/Documents/workplace/cifar-10-binary/cifar-10-batches-bin"
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i)
for i in xrange(1, 6)]
filename_queue = tf.train.string_input_producer(filenames)
reader = tf.FixedLengthRecordReader(record_bytes=3073)
key, value = reader.read(filename_queue)
record_bytes = tf.decode_raw(value, tf.uint8)
# The first bytes represent the label, which we convert from uint8->int32.
label = tf.cast(
tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
# The remaining bytes after the label represent the image, which we reshape
# from [depth * height * width] to [depth, height, width].
depth_major = tf.reshape(
tf.strided_slice(record_bytes, [label_bytes],
[label_bytes + image_bytes]),
[depth, height, width])
# Convert from [depth, height, width] to [height, width, depth].
uint8image = tf.transpose(depth_major, [1, 2, 0])
reshaped_image = tf.cast(uint8image, tf.float32)
reshaped_image.set_shape([height, width, 3])
label.set_shape([1])
images, label_batch = tf.train.shuffle_batch(
[reshaped_image, label],
batch_size=128,
num_threads=16,
capacity=20000 + 3 * 128,
min_after_dequeue=20000)
print("load data")
with tf.Session() as sess:
tf.train.start_queue_runners()
for epoch in range(0, 100):
print("Epoch:", epoch)
for i in range(0, 200):
print("Start Batch ", i)
print(key.eval())
print(images.eval())
print(label_batch.eval())
print("End Batch ", i)
Epoch: 0
Start Batch 0
b'workplace/cifar-10-binary/cifar-10-batches-bin\\data_batch_3.bin:24'
End Batch 0
.
.
.
Start Batch 104
b'workplace/cifar-10-binary/cifar-10-batches-bin\\data_batch_3.bin:9961'
End Batch 104
Start Batch 105
b'C:/Users/Mcdonald/Documents/workplace/cifar-10-binary/cifar-10-batches-bin\\data_batch_5.bin:4'
End Batch 105
.
.
.
Epoch: 1
Start Batch 32
b'workplace/cifar-10-binary/cifar-10-batches-bin\\data_batch_5.bin:9987'
End Batch 32
猜测与推理:
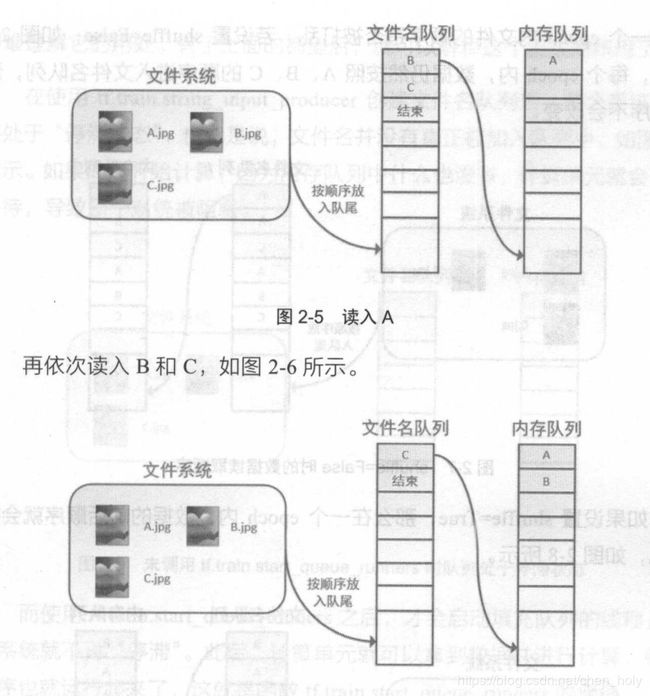
filename_queue 表示文件名队列
tf.train.shuffle_batch内还有一个 待处理对象 队列
images, label_batch = tf.train.shuffle_batch(
[reshaped_image, label],
batch_size=128,
num_threads=16,
capacity=20000 + 3 * 128, # 表示 待处理队列的容量 暂命名队列 a
min_after_dequeue=20000)
num_threads=16
表示每次生成batch的时候,开16个线程从队列 a 取数据,处理数据,最后拼接成batch_size的batch返回
--------------------------------------------------------------------
reader = tf.FixedLengthRecordReader(record_bytes=3073)
key, value = reader.read(filename_queue)
会先从filename_queue中加载一个文件,等这个文件的内容读完,
才会从filename_queue获取下一个文件的路径,加载第二个文件 -- 保证了数据的利用率
--------------------------------------------------------------------
capacity=20000 + 3 * 128,
TFRecords会保持队列a中有足够的数据 提供给线程处理生成batch数据
- 只适合数据集很大的情况
- eg:一个bin文件 有很多图片
思考:
- 1
bin:1328 表示什么 -- 读文件的起始位置