爬虫代理设置之urllib
一 安装CCProxy软件
1 下载地址:
https://ccproxy.en.softonic.com/
2 下载后文件
ccproxysetup.exe
3 简单设置

二 代理设置方法
1 代码
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy = '127.0.0.1:808'
# 参数是字典,键名是协议类型,健值是代理
proxy_handler = ProxyHandler({
'http': 'http://' + proxy,
'https': 'https://' + proxy
})
# Opener已经设置好代理了
opener = build_opener(proxy_handler)
try:
response = opener.open('http://httpbin.org/get')
# 运行结果是一个JSON
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)2 结果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/9_1.py
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.6"
},
"origin": "1.86.246.32",
"url": "http://httpbin.org/get"
}3 说明
运行结果中origin,表明了客户端的IP,此处的IP确实未代理的IP,并不是真实的IP。这样我们就成功设置好代理,并可以隐藏了真实的IP了。
三 代理设置用户名和密码
1 设置代理的用户名和密码
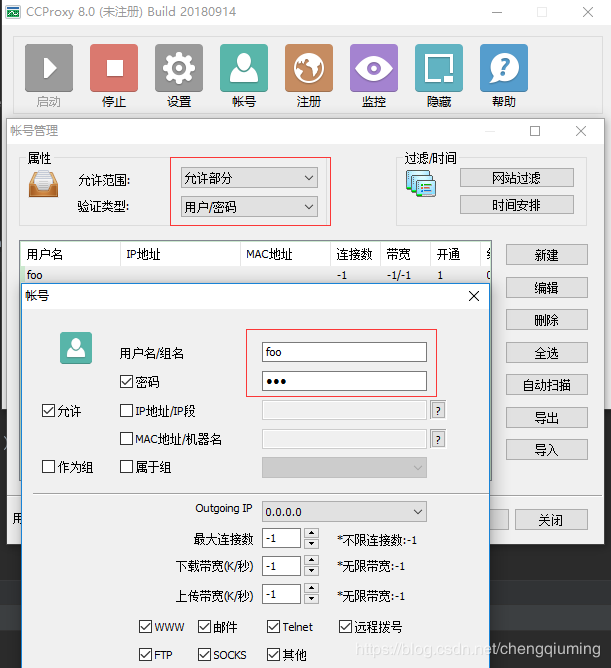
2 代码
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
# 加入代理认证的用户名和密码
proxy = 'foo:[email protected]:808'
proxy_handler = ProxyHandler({
'http': 'http://' + proxy,
'https': 'https://' + proxy
})
opener = build_opener(proxy_handler)
try:
response = opener.open('http://httpbin.org/get')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)3 运行结果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/9_1.py
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.6"
},
"origin": "1.86.246.32",
"url": "http://httpbin.org/get"
}四 代理是SOCKS5类型
1 安装
E:\WebSpider>pip install Pysocks2 代理软件设置
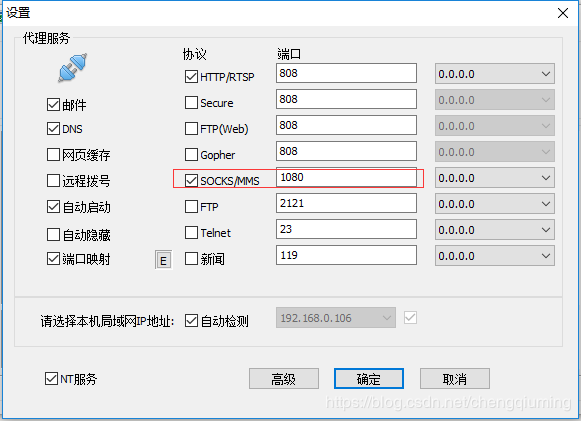
3 代码
import socks
import socket
from urllib import request
from urllib.error import URLError
socks.set_default_proxy(socks.SOCKS5, '127.0.0.1', 1080)
socket.socket = socks.socksocket
try:
response = request.urlopen('http://httpbin.org/get')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)4 结果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/9_1.py
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.6"
},
"origin": "1.86.246.32",
"url": "http://httpbin.org/get"
}