ELK 是一个非常强大的日志分析系统,由 Elasticsearch、Logstash 和 Kiabana这三个核心组件组成。具有分布式的部署、日志实时收集与分析、良好的可视化等特点。ELK 还具有很好扩展性,例如其 X-Pack 组件中的 Machine Learning 插件,可以根据历史数据自动建模。模拟数据的行为、趋势、周期等等,从而更快地发现问题、简化问题根源分析。
< 文章目录 >
一.各组件简介
1.ELK 系统结构
2.Logstash 组件
3.Elasticsearch 组件
4.Kibana 组件
二.Logstash 配置举例
1.Logstash 配置
2.自定义日志格式
3.GeoIP 插件
三.可视化展示
1.实例一(用户登录展示)
2.实例二(访问网站展示)
一.各组件简介
1.ELK 系统结构
Logstash 负责收集日志并发送给 Elasticsearch;Elasticsearch 可提供日志的搜索、分析和存储;Kibana 则可以实现数据可视化。

2.Logstash 组件
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库”(Elasticsearch) 中。

-
INPUT 采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
-
FILTERS 实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式。丰富的过滤器库可提供各种各样的功能,例如GEOIP,可提供IP对应的地理位置(经纬度)信息。再通过 Kibana 可以更直观的显示位置分布。图示如下:

-
OUTPUTS 选择存储库并导出
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
3.Elasticsearch 组件
Elasticsearch 是一个分布式的搜索和数据分析引擎。具有查询分析速度快、扩展性好等特点。支持 X-Pack 组件,提供的特性包括 security、monitoring、alerting、reporting、graph 关联分析和 machine learning。
4.Kibana 组件
Kibana 让您能够可视化 Elasticsearch 中的数据。
-
Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、环形图,等等。

-
可以实现地理空间数据的可视化
利用我们的 Elastic Maps Services 来实现地理空间数据的可视化,可在地图上实现自定义位置数据的可视化。

-
利用机器学习发现异常
根据历史真实的复杂的数据自动建模,可检测出各类异常。

二.Logstash 配置举例
由于使用经验较少,现把实际配置过程中遇到的一些问题做一个整理。
1.多配置文件启动
查看配置文件 /etc/logstash/logstash.yml中配置文件目录 path.config: /etc/logstash/conf.d
可在/etc/logstash/conf.d/目录下创建多个配置文件,用来区分针对不同主机(设备)的日志配置。例如:
squid.conf 和 sslvpn.conf两个配置文件。
########### squid.conf 配置文件 ##########
input {
file { path => "/var/log/nat_log/*.log" type => "squid" }
}
filter {
if [type] == "squid" {
grok {
match => ["message", "%{NUMBER:timestamp}\s+%{NUMBER:response_time} %{IP:src_ip} %{WORD:squid_request_status}/%{NUMBER:http_status_code} %{NUMBER:reply_size_include_header} %{WORD:http_method} %{WORD:http_protocol}://%{HOSTNAME:dst_host}%{NOTSPACE:request_url} %{NOTSPACE:user} %{WORD:squid}/(?:-|%{IP:dst_ip}) %{NOTSPACE:content_type}"]
}
geoip {
source => "dst_ip"
target => "geoip"
}
}
}
output {
if [type] == "squid" {
elasticsearch {
hosts => "172.28.33.38:9200"
index => "logstash-squid-%{+YYYY.MM.dd}"
}
}
}
(注意:定义input 模块中的 type => "squid" 主要用于区分输入源,已达到不同源日志处理的方式不同。如果不加以区分,则两个配置文件的输入源都将使用同一种处理方式。)
########## sslvpn.conf 配置文件 ##########
input {
beats { add_field => {"serverlogfield" => "sslvpn"} port => "5044" }
}
filter {
if [serverlogfield] == "sslvpn" {
grok {
patterns_dir => "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.0.2/patterns"
match => {
"message" => "%{CISCOTIMESTAMP} %{IP} %{SYSLOG5424SD}%{SYSLOG5424SD}%{URIHOST:sslvpnuser} from IP %{IP:sslvpnscrip}: access %{IP:sslvpndesip}"
}
}
}
}
output {
if [serverlogfield] == "sslvpn" {
elasticsearch {
hosts => "172.28.33.38:9200"
index => "sslvpn-%{+YYYY.MM.dd}"
}
}
}
配置输入源也要赋予 type 字段值,但由于接收发送到本机5044端口的日志 type 字段已经被赋予默认值。因此可以额外添加一个字段来区分输入源,如配置中的 add_field => {"serverlogfield" => "sslvpn"} ,以便于后面的 filter 和 output 处理。
2.自定义日志格式
由于各类设备的日志格式不同,用户需求的不同。我们可以利用grok插件来解析成我们想要的日志格式。
源日志为:
Oct 26 14:55:09 x.x.x.x [access resource][TCP]abc123 from IP x.x.x.x: access x.x.x.x:xxxx success
我们只想要提取用户 abc123 访问的时间,可以利用自带的正则表达式 %{URIHOST:sslvpnuser} 将 abc123
映射到 sslvpnuser 字段。grok 默认自带丰富的正则表达式,当然也支持自定义的正则表达式,可以声明正则表达式的目录 patterns_dir 。配置如下:
grok {
patterns_dir => "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.0.2/patterns"
match => {
"message" => "%{CISCOTIMESTAMP} %{IP} %{SYSLOG5424SD}%{SYSLOG5424SD}%{URIHOST:sslvpnuser} from IP %{IP:sslvpnscrip}: access %{IP:sslvpndesip}"
}
}
解析后的日志字段如下图:

可以看到提取成功,下一步即可更直观的展示用户 abc123 登陆访问的时间,后面会演示。
另外,Grok 官方提供两款工具 Grok Debugger 和 Grok Discover 可以帮助用户快速的匹配到恰当的正则表达式。
3.GeoIP 插件
GeoIP 插件可以根据数据库添加公网IP对应的地理位置,可以利用此功能来展示数据地理分布。配置如下:
geoip {
source => "dst_ip"
target => "geoip"
}
在 Kibana 进行可视化,Visualize > New > Tile map 将数据进行地理位置的可视化。

创建时提示如提示 "No Compatible Fields" 错误可参照本文章最后 引用 Kibana的图形化——Tile Map。
三.可视化展示
1.实例一(用户登录展示)
- 显示24小时内 sslvpn 用户登录信息。
如下图所示,用户 waibao2 在二十四小时内登录最多。

- 筛选用户 waibao2 的具体登录信息。
如下图所示,此用户在昨天进20点还在登录,今天凌晨03点就又开始工作了!大大的一个赞!另外还可以看到此用户主要访问三个 IP 地址。

2.实例二(访问网站展示)
- 显示4小时内 squid 代理访问网站展示。
如下图所示,squid 代理4小时内的访问量。可以看出访问的目的 IP 主要集中在北京,可以看到访问量前10的 URL、源、目的 IP,还可以看到 squid 代理服务器访问 TCP 状态占比。
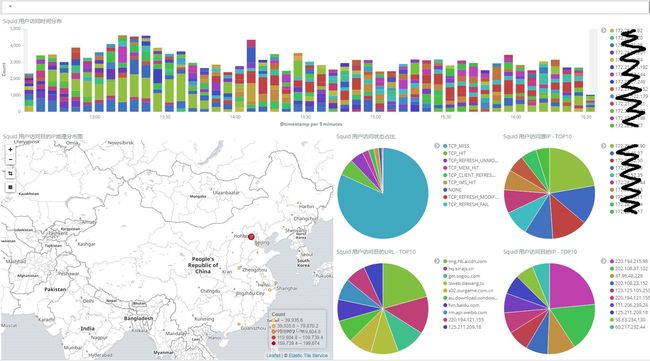
- 筛选访问最多的 URL 信息。
如下图所示,此 URL 服务器地理位置在郑州,还可以看出访问此 URL 的前10个源 IP 地址和访问时间。

引用
- 本文参考了互联网上的资料,如有不恰当之处请谅解。
1.ELK官网
2.How to Install Elastic Stack on CentOS 7
3.漫谈ELK在大数据运维中的应用
4.Kibana的图形化——Tile Map
5.ELK收集nginx日志并用高德地图展示出IP