第十一章 pandas官方文档0.22中文教程---Tutorials(有关cookbook),个人渣翻译
#####chapter 4 分组/聚合是我最喜欢的关于pandas的东西,我一直在用它。你应该读读这个
好吧!我们回到我们的自行车路径数据集。我住在蒙特利尔,我很好奇,我们是不是更像是一个通勤城市,还是一个有趣的城市——人们在周末或工作日更喜欢骑车吗?
在dataframe中添加一个“工作日”列。
首先,我们需要加载数据。我们这样做过
bikes = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')
bikes['Berri 1'].plot()
接下来,我们来看看Berri自行车道。Berri是蒙特利尔的一条街,有一条很重要的自行车道。我现在主要是在去图书馆的路上用它,但有时我在老蒙特利尔工作时也会用它。
所以我们要创建一个dataframe只有Berri 自行车道。
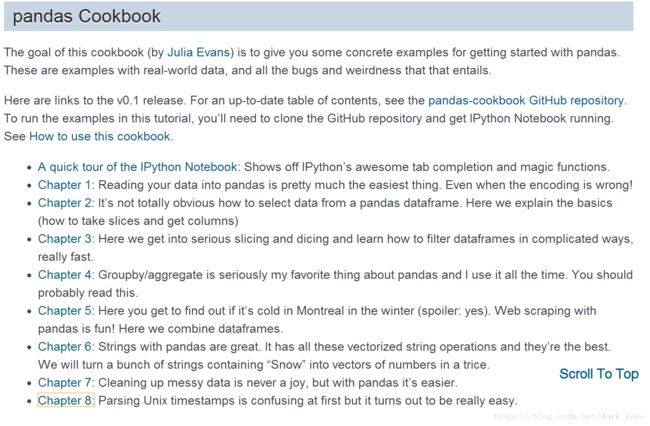
berri_bikes = bikes[['Berri 1']]
berri_bikes[:5]
接下来,我们需要添加一个“工作日”列。首先,我们可以从索引中得到工作日。我们还没有讨论索引,但是索引是在“Date”下面的dataframe上的左边。基本上就是一年中的所有日子
berri_bikes.index

你可以看到实际上有些日子不见了——实际上一年只有310天。谁知道这是为什么。
pandas有很多非常棒的时间序列功能,所以如果我们想让每一行都有一个自然月的时间表现,我们可以这样做
berri_bikes.index.day

不过,我们实际上想要的是工作日
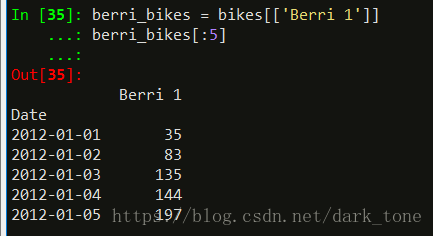
berri_bikes.index.weekday
按照一周7天的方式表现,0是星期天。
现在我们知道了如何得到工作日,我们可以将它添加到dataframe中的一个列中:
berri_bikes['weekday'] = berri_bikes.index.weekday
berri_bikes[:5]
运行语句得了个警告:

(这个警告没怎么搞懂,我用.loc的方式也一样出现。)
在平日里把骑自行车的人加起来
结果真的很简单!
Dataframs有一个类似于SQL groupby的.groupby()方法,如果您熟悉它的话。我现在不打算解释更多,如果你想知道更多,看详细文档更好。
在本例中,berri_bikes.groupby(‘weekday’).aggregate(sum)表示“在工作日将行分组,然后将所有的值添加到同一个工作日”。
weekday_counts = berri_bikes.groupby('weekday').aggregate(sum)
weekday_counts


(berri_bikes本身是310行,2列的dataFrame,利用groupby直接就分组了)
很难记住0 1 2 3 4 5 6代表的意思,我们可以把它固定下来,然后呈现出来。
weekday_counts.index = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_counts

最后画出来:
weekday_counts.plot(kind='bar')

#####chapter 5
在这里你可以了解到蒙特利尔的冬天是否寒冷(剧透:是的)。用pandas抓取网页很有趣!在这里我们把dataframes结合起来。
到本章结束时,我们将下载2012年加拿大所有的天气数据,并将其保存到CSV中。
我们会一次下载一个月,然后把所有的月份结合在一起。
它包括2012年的每小时温度!
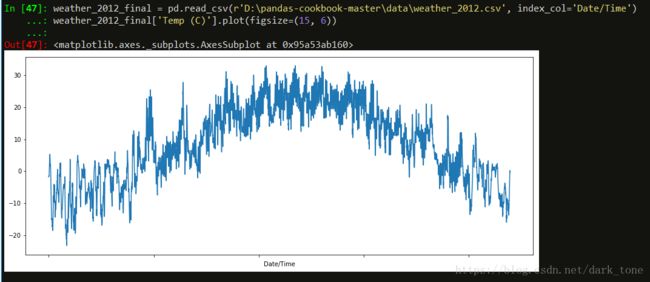
weather_2012_final = pd.read_csv('../data/weather_2012.csv', index_col='Date/Time')
weather_2012_final['Temp (C)'].plot(figsize=(15, 6))
在玩自行车数据的时候,我希望温度和降水数据能在下雨的时候发现像骑自行车这样的人。所以我去了加拿大历史天气数据的网站,并找到了如何自动获得它。
这里我们将获得2012年3月的数据,并进行清理。
这里有一个URL模板,可以用来在蒙特利尔获取数据。
url_template = "http://climate.weather.gc.ca/climateData/bulkdata_e.html?format=csv&stationID=5415&Year={year}&Month={month}&timeframe=1&submit=Download+Data"
为了获得2013年3月的数据,我们需要将其格式化为一个month=3,year=2012。
url = url_template.format(month=3, year=2012)
weather_mar2012 = pd.read_csv(url, skiprows=16, index_col='Date/Time', parse_dates=True, encoding='latin1')
超级棒!我们可以像以前一样使用相同的read_csv函数,然后给它一个URL作为文件名。太棒了。
在CSV的顶部有16行元数据,但是pandas知道CSVs很奇怪,所以有一个skiprows选项。我们再次解析日期,并将“日期/时间”设置为索引列。结果就是dataframe。
(个人执行这些语句,出错,)
(没有数据,剩下的工作都没办法完成。)
#####chapter 6
pandas自带字符串处理。它有所有这些矢量化的字符串操作,它们是最好的。我们将把一串包含“snow”的字符串转换成数字的向量
我们之前看到pandas很擅长处理日期。它也令人惊奇的在字符串处理!我们将从第5章的天气数据回来。
weather_2012 = pd.read_csv('../data/weather_2012.csv', parse_dates=True, index_col='Date/Time')
weather_2012[:5]

你会看到“天气”栏目里有一个关于每小时天气的文字描述。如果文本描述包含“Snow”,我们会假设它在下雪。
pandas提供了矢量化的字符串函数,使其易于操作包含文本的列。文档中有一些很好的例子。
weather_description = weather_2012['Weather']
is_snowing = weather_description.str.contains('Snow')
这给了我们一个二元向量,这有点难看,所以我们把它画出来
(原作者的意思是数据没有图像清楚)
# Not super useful
is_snowing[:5]

# More useful!
is_snowing.plot()
(画不出来,报错)
(明明is_snowing有数据啊,no numeric data to plot,难道bool值不能画?)
(把bool 值临时修改成float数据,果然能画了)
is_snowing.astype(float).plot()

如果我们想要每个月的平均温度,我们可以使用像这样的resample()方法:
weather_2012['Temp (C)'].resample('M', how=np.median).plot(kind='bar')
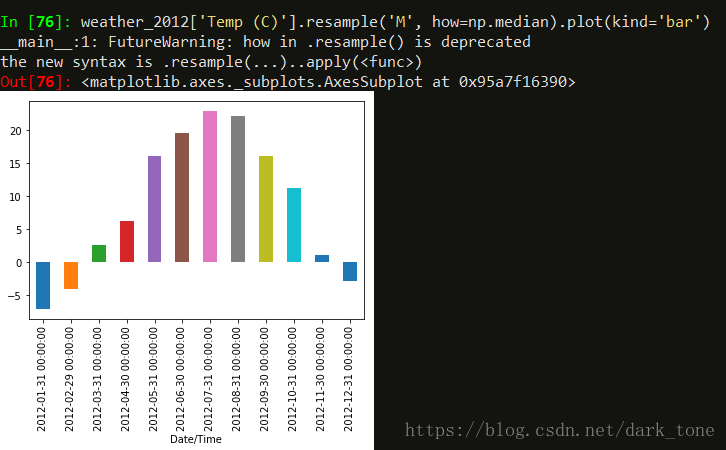
不出所料,7月和8月是最热的。
所以我们可以把snow看成是一堆1和0而不是Trues和Falses:
is_snowing.astype(float)[:10]
(转换类型是临时,is_snowing本身type并没有变)
然后使用resample来查找每个月下雪的时间百分比。
is_snowing.astype(float).resample('M', how=np.mean)
is_snowing.astype(float).resample('M', how=np.mean).plot(kind='bar')

现在我们知道!2012年12月是下雪最多的一个月。另外,这张图显示了我的感觉——11月开始下雪,然后慢慢变细,需要很长时间才能停下来,最后一场雪通常在4月或5月。
我们还可以将这两个统计数据(温度和降雪)合并到一个dataframe中,并将它们组合在一起:
temperature = weather_2012['Temp (C)'].resample('M', how=np.median)
is_snowing = weather_2012['Weather'].str.contains('Snow')
snowiness = is_snowing.astype(float).resample('M', how=np.mean)
# 新数据的列名
temperature.name = "Temperature"
snowiness.name = "Snowiness"
我们将再次使用concat将两个统计数据合并到一个dataframe中
stats = pd.concat([temperature, snowiness], axis=1)
stats

同样画出来:
stats.plot(kind='bar')

嗯,那不是很好,因为比例是错的。我们可以通过在两个不同的图上画出来做得更好:
stats.plot(kind='bar', subplots=True, figsize=(15, 10))

#####chapter 7
清理凌乱的数据从来都不是一件乐事,但对pandas来说,这更容易。
杂乱数据的一个主要问题是:你如何知道它是否凌乱?
我们将在这里再次使用NYC 311服务请求数据集,因为它很大而且有点笨拙。
requests = pd.read_csv('../data/311-service-requests.csv')
我们来看看这里的一些列。我已经知道邮政编码有一些问题,让我们先看一下。
为了了解列是否存在问题,我通常使用.unique()来查看它的所有值。如果它是一个数字列,那么我将绘制一个直方图来获得分布的感觉。
当我们看到“Incident Zip”中唯一的值时,很快就会发现这是一团乱子。
requests['Incident Zip'].unique()
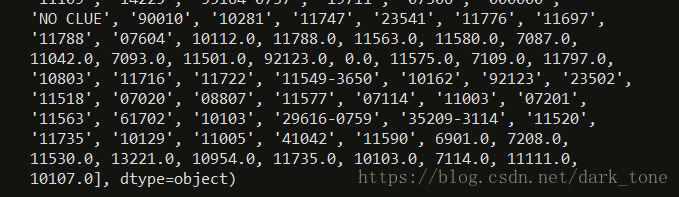
其中一些问题:
①有些值被解析为字符串,有些则作为浮点数
②有nan值
③有些邮政编码是29616-0759或者83
④这里有一些pandas不认识的N/A值,比如 ‘N/A’ and ‘NO CLUE’
我们能做什么
①把 ‘N/A’ 和 ‘NO CLUE’ 归纳成正常的nan值
②看看83的情况,然后决定怎么做
③处理所有字符串
修复nan值和string/float混淆
我们可以将na_values选项传递给pd.read_csv来清理一下。我们还可以指定Incident Zip 的类型是字符串,而不是浮点类型。
na_values = ['NO CLUE', 'N/A', '0']
requests = pd.read_csv('../data/311-service-requests.csv', na_values=na_values, dtype={'Incident Zip': str})
(通过读取文件的过程中,清理不要的值,改变值的类型)
#清理完成后再看看
requests['Incident Zip'].unique()

(完成了第一步清理)
#第二步清理
rows_with_dashes = requests['Incident Zip'].str.contains('-').fillna(False)
len(requests[rows_with_dashes])
把Incident Zip中含有‘-’的值,填充成False。
(requests[rows_with_dashes]这种写法没见过,)
我以为这些都是丢失的数据,原来是这样删除的
requests['Incident Zip'][rows_with_dashes] = np.nan
但后来我的朋友Dave指出9位邮政编码是正常的。让我们看看所有超过5位数字的邮政编码,确保它们正常,然后截断它们。
long_zip_codes = requests['Incident Zip'].str.len() > 5
requests['Incident Zip'][long_zip_codes].unique()
这些看起来都可以截断。
requests['Incident Zip'] = requests['Incident Zip'].str.slice(0, 5)
早些时候我认为00083是一个坏的邮政编码,但结果是中央公园的邮政编码00083!显示了我所知道的。不过,我仍然担心00000的邮政编码:让我们看看。
requests[requests['Incident Zip'] == '00000']
zero_zips = requests['Incident Zip'] == '00000'
requests['Incident Zip'][zero_zips] = np.nan
很棒,让我们现在看一看:
unique_zips = requests['Incident Zip'].unique()
unique_zips.sort()
unique_zips
(运行出错,这几步没看懂,先标记)
#####chapter 8 解析unix的时间戳
我暂时不用unix系统,pass