代码详解:用Keras和OpenBCI,连接机器和大脑!
全文共12179字,预计学习时长25分钟或更长

Neuralink公司及其创始人埃隆·马斯克打算构建可充当大脑第三层的脑机接口,由此来实现人与AI的融合共生。
那么利用现有科技能否做到这一点呢?
从某种意义上来说,其实可以。

背景介绍
脑机接口(BCI)泛指在大脑神经系统与电子设备间建立直接联系的任一系统。有些电子设备可经手术植入大脑,也有的在外部即可发挥作用。比如用户控制执行器或键盘、设备向用户发送感官数据、涉及感官数据及运动控制的双向通信(即假肢接收到设备用于控制运动的输入后,会输出对于压力或温度的感测数据)都是应用脑机接口的典型范例。
神经假体如被截肢者所需的假肢、失聪者所需的人工耳蜗,以及用于癫痫患者发作时的深层脑刺激历来是BCI研究的出发点。已有数百万人这类设备中获益,由此可见脑机接口之妙。不过,该项技术的应用远不止于此,即使是在神经假体这个领域,用途就已多种多样。除去上述应用,脑机接口还可用来增强人体原有能力,打造出一个个“超人”。未来,假肢或许看起来、摸起来都与常人肢体无异,实际上却更加结实、灵活,说不定比“原装”肢体还要好用。人造眼是脑机接口的又一项应用,分辨力比人眼要高,可放大或缩小,还能看到紫外线或红外线。
脑机接口在认知形成与技能培养方面的应用则更为有趣。最近有研究表明,刺激大脑某些部位有利于记忆的形成与提取,还有实验已成功给动物植入记忆。这一应用或许能让人快速学会一门乐器,或者,还可将传感器和多种神经刺激器结合,开发出一种“算法处理单元”,大脑中与数学或逻辑推理有关的区域被激活时,该算法就能检测到,然后与之交流以强化此能力。
推广在BCI认知强化方面的应用正是埃隆·马斯克与Neuralink公司所追求的目标。马斯克和许多AI专家认为,较之AI,人类智慧无法更上一层楼主要是因为人脑带宽有限:计算机与AI运行的速度越来越快,处理及生成知识的能力也越来越强,可人脑的限制却让人类无法大步向前。人主要依靠感官和语言理解能力来获取信息,通过人眼和视觉皮层来浏览、解析某句话,而同样的时间,计算机就能扫描完数千页文本。可想而知,不消几十年,AI或许就能用于专门的神经形态硬件,可精准观测世界运作,并能在短短几分钟内解析数百万份文档,做出人类无法明白的决断。在一个日益依赖AI进行决策的时代,人们会发现自己在商业、科学和政治领域的决策中早已无足轻重。人脑还没那么高级,玩不了含有万亿棋子的象棋游戏,也理解不了提前数百万步制定的计划。正是出于对超智能计算机的担忧,Neuralink、Kernel和其他相关机构开始了当前的工作。
大部分BCI前沿研究都试图将信息带宽最大化,植入性方法便是其中的典型技术,即直接将电极植入大脑或神经。不过,非植入性技术特别是脑电图(EEG)和肌电图(EMG)更为常用,而且往往能取得巨大成功,具体操作就是将电极放在头部表面(EEG)或肌肉上方的皮肤(EMG)上,测量其下方的累积电活动。该数据的粒度很小,远小于达到BCI研究终极目标所需的精度及带宽。尽管如此,EEG或EMG的BCI仍实现了巨大突破,如用思想控制无人机、玩电子游戏以及操控键盘等,这对未来的研究也有一定启发性。此外,Cognixion和Neurable等多家公司正在探索基于EEG的BCI在现实中的应用,并已获得可观的资金及支持,许多激动人心的项目都在筹划中。

概述
在此项目中,我们在神经系统和外部AI代理之间建立了直接联系。代理可自由选择,只要能有API即可,像Google Assistan、Siri、Alexa和Watson这些都可以考虑。也可以选择Dictionary或YouTube之类,不过使用这些只能根据内容进行查询工作,不能实现一般性请求。
就本项目目标而言,选用Google Search这个软件,因为它最灵活,设置起来也最容易。完成这些后,很多术语你只需一想,不必输入,即可在谷歌上查询。
我们采用的这一技术会利用大脑在默读中产生的神经信号。这个信号就是你在品读、思考时大脑的“内部独白”。也许你在默读时会发现,有时下巴和舌头会轻微动动,幅度很小,你甚至都察觉不到。在有关SAT、MCAT、GRE或其他标准化考试的应试技巧里,你可能也见过类似概念。考试时尽量不要默读,否则会影响你的阅读速度。
不妨充分利用默读这一特性,因为即使你不打算出声,大脑也会根据你所想的词向喉部发送相应信号。将电级置于喉咙和下颌神经上方的脸部区域,就能记录与特定词相对应的信号,再以此训练深度学习模型去识别不同词语。也就是说,在你想某个词语时,只要你一想,别人就能知道你在想什么。
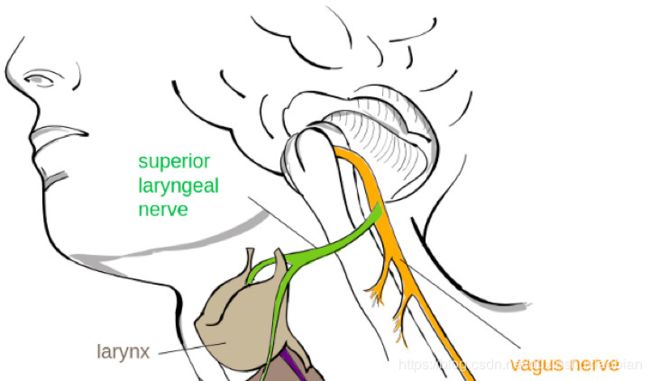
脑和喉神经
这一技术有其局限性,并非完美无暇,尚不能解决实际问题。不过早在两年前,麻省理工媒体实验室就首次将其应用于实际,如今该技术已成功用于某些设备,使用这些设备,用户只需动动脑就可算数、打电话、订比萨,甚至在下围棋时,也能得到帮助。

麻省理工学院媒体实验室的AlterEgo耳机

装备及材料
OpenBCI Ganglion板是一个必备的硬件。当然还有很多其他硬件可选,不过OpenBCI背后有着庞大的开发者群体。买下来大约得200美元,但一想到它的用途,你就会觉得物超所值。

OpenBCI板和电极
除了Open BIC板,还需要电极和电线。花50美元买上一套金杯电极和电极胶就可以了。
或者也可以花465美元买上一全套OpenBCI入门工具,里面包含开发板和多种干电极以及电极头带。确实贵了点,其实金杯电极完全够用。不过要想试验BCI的用途,比如VR(即将推出Unity VR教程!),使用头带和干电极体验会更好。
Open BCI还有8通道和16通道电路板,可以提供高质量的数据,但其实4通道的Ganglion对本项目来说就够用了。

配置
查看Linux系统是否有Python 3.4或更高的版本。打开终端,输入以下指令:
python3 --version
如果没有Python,或者版本低于3.4,则输入:
$ sudo apt-get update
$ sudo apt-get install python3.6
现在,下载或复制pyOpenBCI目录(https://github.com/OpenBCI/pyOpenBCI)。
更改目录至存储库,然后运行以下指令来安装必备软件包:
$ pip install numpy pyserial bitstring xmltodict requests bluepy
现在就能安装 pyOpenBCI了
$ pip install pyOpenBCI
要查看某些操作,可将目录更改为pyOpenBCI / Examples,然后找到print_raw_example.py。自行选用代码编辑器将其打开,再对第7行进行如下操作:
board = OpenBCICyton(daisy = False)
应改为:
board = OpenBCIGanglion(mac=’*’)
这样,pyOpenBCI就可以根据我们所用的电路板调度相应模块。
现在,打开电路板的电源。
在终端的Examples 目录中键入以下指令:
$ sudo python print_raw_example
好啦!!现在,你的终端应该全都是来自开发板的原始输入数据流。
记录信号
获取原始信号后,就可以开始设计构建数据管道了。首先,须将原始数据转换为LSL流。LSL即实验室流传输层,是由加州大学圣地亚哥分校Swartz计算神经科学中心为方便记录实时数据流而开发的协议。LSL会将EEG数据流式传输至本地主机,其他应用程序或脚本遍可在此提取这些数据。
修改pyOpenBCI / Examples中的lsl_example.py文件,可以删掉不需要的AUX流,再添上一个标记流:
from pyOpenBCI import OpenBCIGanglion
from pylsl import StreamInfo, StreamOutlet, ContinuousResolver
import numpy as np
import random
import time
SCALE_FACTOR_EEG = ((4500000)/24/(2**23-1))/1.5 #uV/count
print("Creating LSL stream for EEG. \nName: OpenBCIEEG\nID: OpenBCItestEEG\n")
info_eeg = StreamInfo('OpenBCIEEG', 'EEG', 4, 250, 'float32', 'OpenBCItestEEG')
outlet_eeg = StreamOutlet(info_eeg)
info = StreamInfo('MyMarkerStream', 'Markers', 1, 0, 'string', 'myuidw43536')
# next make an outlet
outlet = StreamOutlet(info)
markernames = ['Marker']
def lsl_streamers(sample):
outlet_eeg.push_sample(np.array(sample.channels_data)*SCALE_FACTOR_EEG)
outlet.push_sample([markernames[0])
print(np.array(sample.channels_data)*SCALE_FACTOR_EEG)
board = OpenBCIGanglion(mac='E0:40:DA:FF:A2:F7')
board.start_stream(lsl_streamers)
现在,须定义一个实验装置来按要求形式记录存储数据,以备进一步使用。最终目标是生成EEG时间序列数据集,数据集内要有多个间隔,每个间隔对应着单个词语的默读。要实现这一目标,可以开始记录一段时间,记录有N个间隔,每个间隔持续T秒,间隔内的全部样本均用间隔索引和让用户默读的特定单词进行加注。
neurotech-berkeley的lsl-record.py文件是个很不错的起点。根据定义的装置来修改文件:
import numpy as np
import pandas as pd
import random
from time import time, strftime, gmtime
from optparse import OptionParser
from pylsl import StreamInlet, resolve_byprop
from sklearn.linear_model import LinearRegression
default_fname = ("data/data_%s.csv" % strftime("%Y-%m-%d-%H.%M.%S", gmtime()))
parser = OptionParser()
parser.add_option("-d", "--duration",
dest="duration", type='int', default=200,
help="duration of the recording in seconds.")
parser.add_option("-f", "--filename",
dest="filename", type='str', default=default_fname,
help="Name of the recording file.")
# dejitter timestamps
dejitter = False
(options, args) = parser.parse_args()
print("looking for an EEG stream...")
streams = resolve_byprop('type', 'EEG', timeout=2)
if len(streams) == 0:
raise(RuntimeError, "Cant find EEG stream")
print("Start aquiring data")
inlet = StreamInlet(streams[0], max_chunklen=12)
eeg_time_correction = inlet.time_correction()
print("looking for a Markers stream...")
marker_streams = resolve_byprop('type', 'Markers', timeout=2)
if marker_streams:
inlet_marker = StreamInlet(marker_streams[0])
marker_time_correction = inlet_marker.time_correction()
else:
inlet_marker = False
print("Cant find Markers stream")
info = inlet.info()
description = info.desc()
freq = info.nominal_srate()
Nchan = info.channel_count()
ch = description.child('channels').first_child()
ch_names = [ch.child_value('label')]
for i in range(1, Nchan):
ch = ch.next_sibling()
ch_names.append(ch.child_value('label'))
# Word Capturing
currentWord = 1
currentTerm = "GAS STATION"
t_word = time() + 1 * 2
words = []
terms = []
termBank = ["GAS STATION", "COFFEE", "PIZZA"]
res = []
timestamps = []
markers = []
t_init = time()
print('Start recording at time t=%.3f' % t_init)
print(currentTerm)
while (time() - t_init) < options.duration:
# Check for new word
if time() >= t_word:
currentTerm = random.choice(termBank)
print("\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n" + str(currentWord) +": " +currentTerm)
currentWord += 1
t_word = time() + 1 * 2
try:
data, timestamp = inlet.pull_chunk(timeout=1.0, max_samples=12)
if timestamp:
res.append(data)
timestamps.extend(timestamp)
words.extend([currentWord] * len(timestamp))
terms.extend([currentTerm] * len(timestamp))
if inlet_marker:
marker, timestamp = inlet_marker.pull_sample(timeout=0.0)
if timestamp:
markers.append([marker, timestamp])
except KeyboardInterrupt:
break
res = np.concatenate(res, axis=0)
timestamps = np.array(timestamps)
if dejitter:
y = timestamps
X = np.atleast_2d(np.arange(0, len(y))).T
lr = LinearRegression()
lr.fit(X, y)
timestamps = lr.predict(X)
res = np.c_[timestamps, words, terms, res]
data = pd.DataFrame(data=res, columns=['timestamps'] + ['words'] + ['terms'] + ch_names)
data['Marker'] = 0
# process markers:
for marker in markers:
# find index of margers
ix = np.argmin(np.abs(marker[1] - timestamps))
val = timestamps[ix]
data.loc[ix, 'Marker'] = marker[0][0]
data.to_csv(options.filename, float_format='%.3f', index=False)
print('Done !')
可对termBank(第64行)进行调整,试试多种情况下不同的单词组合。还可以在每个片段前调整默认的持续时间(第12行)。
好好体验一番吧!将电极插入电路板:

左边4个通道进入EEG,右边2个通道接地
将它们按以下方式粘到脸上:

找个安静的地方,坐下来,在独立的终端输入以下几行:
// Terminal 1: converts raw data to LSL and streams it
$ sudo python lsl_example// Terminal 2: reads LSL data stream and executes experiment
$ sudo python lsl_record
注意:以sudo运行,让脚本来检测电路板的MAC地址
这样就可以记录一段特定时间了。术语库每隔2秒会随机出现一个词语,你需要默读一下。录制期间也许会感觉不适,感到困,因此最好分多次录制,每次录一小段时间,中间进行适当休息。此外,录制期间如果干扰频现(例如装置突然移动或默读时读错),该装置可能会严重影响到数据质量。
你可以设计、采用更为灵活的装置,在上面添加一个按键,检测到干扰时就能删除当前及前面间隔。或者还可以分多次录制,最后再把数据合并到一起,以此避免干扰过多。有干扰在所难免,也不必太挑剔,因为随着样本数量的增加,模型的适应性会增强。
为获得最佳结果,词库中的每个词语都至少要有1000个高质量的样本。
处理信号
收集到足够的数据,再处理一下即可应用于机器学习。
将数据适当组合、预处理成以下格式:
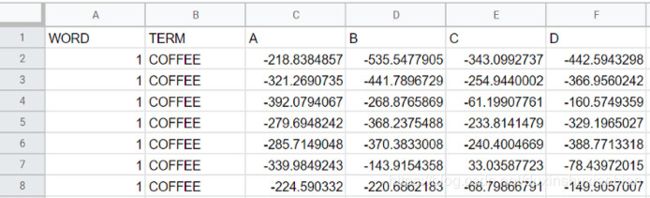
数据表示例
• 词语即从1到NumIntervals的索引,是SessionDuration / 2在所有片段上的总和
• 术语对应每个间隔显示的词语
• [A,B,C,D]为EEG通道
• 每个词语、术语组合约对应800行数据
使用numpy将CSV文件导入python。所有数据应该载入到脚本的NumLines x 6 ndarray中。
第一步要对数据进行过滤,以消除在所需频率范围外的噪音。可用的EEG频率对应以下频段:
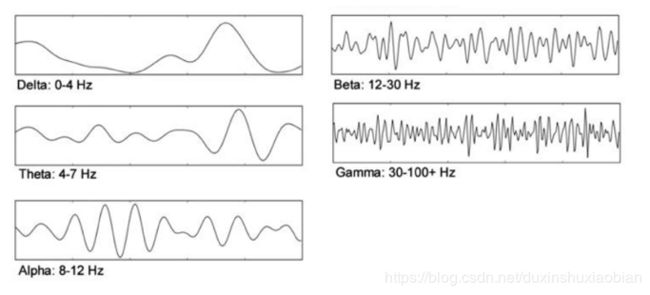
脑电波频率
看上去对4 Hz至100 Hz间的频率进行过滤还算合理,但或许过滤效果并不好,因为电网频率为60 Hz(不同国家这一数值可能不同),肯定会成为主要噪声源。所以为得到最佳结果,应在4 Hz至50 Hz之间进行过滤。
可以使用Scipy的Butterworth滤波器来选择要保留的频率范围。用以下代码定义过滤器:
from scipy.signal import butter, lfilter def butter_bandpass(lowcut, highcut, fs, order=5): nyq = 0.5 * fs low = lowcut / nyq high = highcut / nyq b, a = butter(order, [low, high], btype='band') return b, a def butter_bandpass_filter(data, lowcut, highcut, fs, order=5): b, a = butter_bandpass(lowcut, highcut, fs, order=order) y = lfilter(b, a, data) return y
然后,生成一个时间戳列(合并多个数据集后,原来的时间戳已失效),再将过滤器应用于各个通道:
# Remove Noise nsamples = my_data[:, 1].shape[0] T = nsamples/400 t = np.linspace(0, T, nsamples, endpoint=False) fs = 400.0 lowcut = 4.0 highcut = 50.0 my_data[:, 2] = butter_bandpass_filter(my_data[:, 2], lowcut, highcut, fs, order=6) my_data[:, 3] = butter_bandpass_filter(my_data[:, 3], lowcut, highcut, fs, order=6) my_data[:, 4] = butter_bandpass_filter(my_data[:, 4], lowcut, highcut, fs, order=6) my_data[:, 5] = butter_bandpass_filter(my_data[:, 5], lowcut, highcut, fs, order=6)
过滤后,利用以下代码将数据重构为尺寸为IntervalLength x ChannelCount x IntervalCount的三维ndarrray数组。
# Separate words
lineIndex = 0
currentWord = 2
imageLength = 110
currentImage = np.zeros(4)
imageDimensions = (imageLength, 4)
imageDirectory = np.zeros(imageDimensions)
answerDirectory = np.zeros(1)
while lineIndex < my_data.shape[0]:
currentLine = np.array(my_data[lineIndex])
if int(currentLine[0]) == currentWord:
currentImage = np.vstack((currentImage, currentLine[2:]))
else:
currentImageTrimmed = np.delete(currentImage, 0, 0)
currentImageTrimmed = np.vsplit(currentImageTrimmed, ([imageLength]))[0]
if currentImageTrimmed.shape[0] < imageLength:
print("ERROR: Invalid Image at currentWord = " + str(currentWord))
exit(1)
imageDirectory = np.dstack((imageDirectory, currentImageTrimmed))
answerDirectory = np.vstack((answerDirectory, currentLine[1]))
print(str(imageDirectory.shape) + "\n")
currentImage = np.zeros(4)
currentWord = currentLine[0]
lineIndex += 1
imageDirectory = np.transpose(imageDirectory, (2, 0, 1))
imageDirectory = np.delete(imageDirectory, 0, 0)
answerDirectory = np.delete(answerDirectory, 0, 0)
answerDirectory = np_utils.to_categorical(answerDirectory)
利用上述代码,就可以将时间序列数据转换为图像数据。也许你从未听说过这个,大可将每2秒的间隔视为一幅图像,每个像素对应在特定(channelNumber,lineNumber)坐标处获取的信号值。换句话说,有一组IntervalCount图像,每个图像的大小都是IntervalLength x CannelCount。

EEG间隔的前120个数据点
贾斯汀·阿尔维在一个类似项目中演示了这一强大技术,着实令人惊叹,有了它,时间序列数据就相当于图像数据,然后就可以利用计算机视觉和卷积神经网络(CNN)的强大功能对其进行处理。甚至还能通过绘制图像来形象化对某个词的默读。
另外,使用CNNs就能避开傅立叶变换,因为在数学上,时间序列数据上的卷积与过滤变换后的数据是等同的。
现在即可准备构建CNN。由于只有1个颜色维度,就可以使用输入尺寸为IntervalLength和ChannelCount的一维 CNN。你也可以试试不同的超参数及架构。这里选用了一个卷积层、两个完全连接的层和两个池化层。
# Split to Training and Testing Set X_train, X_test, y_train, y_test = train_test_split(imageDirectory, answerDirectory, test_size=0.3) # Build Model model = Sequential() model.add(Conv1D(40, 10, strides=2, padding='same', activation='relu', input_shape=(imageLength, 4))) model.add(Dropout(0.2)) model.add(MaxPooling1D(3)) model.add(GlobalAveragePooling1D()) model.add(Dense(50, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(2, activation='softmax')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Train Model model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=100, epochs=300)
有关一维CNN的详细分析以及如何将其应用于时间序列数据,请参阅Nils Ackermann的这篇文章:https://blog.goodaudience.com/introduction-to-1d-convolutional-neural-networks-in-keras-for-time-sequences-3a7ff801a2cf
现在有了模型,就能将EEG数据的间隔与词库中的特定词语进行匹配。
下面来看看效果如何。将模型应用于测试数据,再将预测结果与实际结果进行比较。
# Test Model
y_predicted = model.predict(X_test)
在术语库选取两个词语,准确率能达到90%。果然,随着词语数量增加,准确率会有所下降,三个词语准确率为86%,四个词语则为81%。

两个单词类别的真值图示例。左侧为实际结果,右测为预测结果。
在不影响准确率的情况下,可通过创建带有多词查询的分层“术语树”来丰富术语库。然后,可在“术语树”上进行深度优先搜索——仅将单词的每一层与同一子树同一层中的其他单词进行比较——以实现最佳匹配。
谷歌搜索
现在,通过BCI进行谷歌搜索的工具都已齐全。接下来定义对某一单词的默读与相应搜索之间的映射,并进行适当调用:
# Query Google import webbrowser qID = 9 # Choose a sample to query with baseString = "https://www.google.com/search?query=" queryString = "" if classPredictions[qID] == 0: queryString = "directions+to+Starbucks+near+me" elif classPredictions[qID] == 1: queryString = "directions+to+gas+station+near+me" urlString = baseString + queryString webbrowser.open(urlString, new=2)
接着......
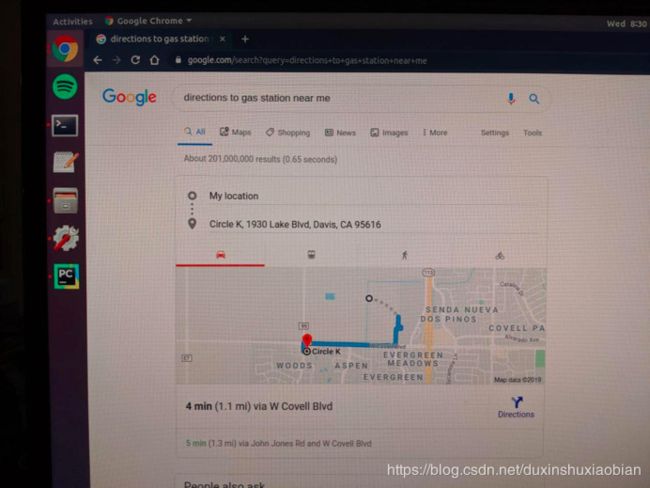
要使得大脑的思考与实际查询同步进行,需修改lsl_record.py脚本并将其作为一个模块进行导入。然后,用它来读取LSL流,以对用户间隔为2秒的输入作出反应。
好啦!现在你不用读出来,也不用手动输入,就可以用Google搜索词语了。

结语
对于只有三、四个单词的术语库,实在没什么可操作的(除非能创建出前文提到的术语树)。这些步骤都完成后,利用该装置找出通往最近加油站的路线还是要比手动谷歌搜索复杂些。不过,该技术的未来发展及影响力才是重点。其实,这一装置的改良与普通版,与MIT团队目前用于导航、Web查询、文本消息传递、智能家居管理或许多例行任务的装置差别不大。但一旦将其与日益精进且能够分析各种情况的AI助手相结合,它能做的就远不止于此了。
放眼全球各大公司和高校实验室的前沿研究,基于EEG的BCI应用只能算是冰山一角。利用心灵感应实现通信、超人智能、更多感官,仿真体验、人类意识的数字化以及与人工智能的融合都值得我们去思索。这些情况一旦成为现实,不仅会重新定义人与技术的关系:还将重新定义人。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)