python爬虫.基础笔记
以下内容为个人笔记,记录内容有所简略
参考资料python3爬虫系列教学
爬虫思路
爬虫的思路就是:
1、获取url(网址)
2、发出请求,获得响应
3、提取数据
4、保存数据
对于网址(url),可以视之为所要访问资源的路径,客户端申请,等待响应就可以获得需要的资源。
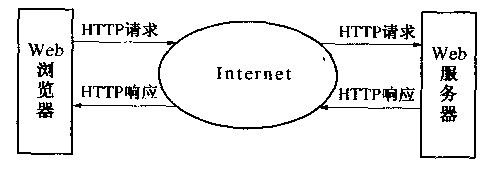
对于请求与响应,要明白信息都是存在服务器中的,浏览器只是发出请求然后老老实实的等待回应,爬虫就是用python代码而非浏览器发出申请,然后等待回应,回应是网页的源代码。有时服务器察觉到是爬虫发出的申请会拒绝,这时候我们要把自己包装成浏览器的亚子。
爬虫无非是要收集数据,但我们的到的响应往往是这个鬼样子。并不是所有的信息都是我们需要的。
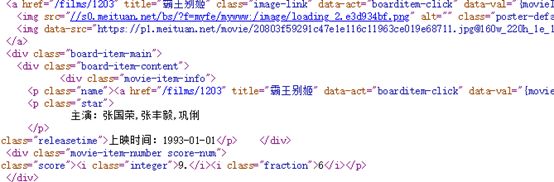
我们只需要我们想要的信息,像这样

甚至我们想顺便把它好好整理出来,像这样
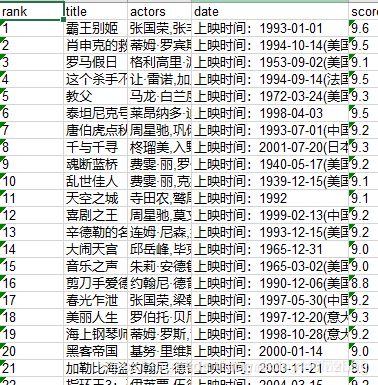
后面两张图就是数据筛选和保存的结果。
数据的保存就是将提取的信息保存到Excel或数据库中,方便查看和分析。
由于数据保存这一步需要写的代码几乎是固定不变的,没什么技术含量,也不需要刻意去记,每次使用复制粘贴就可以。
综上,爬虫的过程,先构造你要访问的网址,向服务器发出申请(这一步比较固定),然后从回应中筛选你要的信息(这一步变数大),然后将筛选的数据保存(这一步也比较固定)。
所以爬虫的关键在于数据提取,数据提取的方法有许多,比如正则表达式,还有beautifusoup库。正则表达式是比较常用的方法,它是根据网页的源代码来提取数据的,不需要考虑网页的结构。
定义函数
设计黑箱,方便代码观看设计。
如发送请求就可以写一个函数:
def get_page(url):#定义一个发送请求的函数,起名为get_page()。
try: #try和except 是为了保证程序能够一直运行下去的。
r=requests.get(url,headers=headers) #通过requests库的get函数向服务器发送请求。
r.raise_for_status() #根据服务器返回的状态码来判断是否请求成功,若成功就返回函数运行结果,若失败跳到except那行,执行except下面的语句。
r.encoding=r.apparent_encoding #防止乱码
return r.text #返回服务器给出响应的文本信息
except Exception as e: #若try里面的内容执行成功,这行代码就会被跳过。
print(e) #将运行失败的原因打印出来
# 如果我们请求的网页数据是动态生成的,那么return后面的r.text需要改成r.json()
有时候也会设计用yield的函数
正则表达式
用简洁的方式表示一组字符串
此外我们需要re模块
re模块中有一个findall函数,当其传入一个正则表达式的参数时,就可以变成一个筛选我们想要数据的“网”
import re
data='a1b88888a2b000000a3b00323'
result1=re.findall('a(.*?)b',data,re.S)
#提取a、b之间的数字
result2=re.findall('b(.*?)a2',data,re.S)
#提取数字88888
#运行结果:
result1=['1','2','3']
result2=['88888']
第一个参数中“(.*?)”代替我们要提取信息的位置。
第二个参数是提取的对象。
第三个参数的作用是告诉函数可以跨行匹配,把\n当字符,否则函数只会在一行内进行匹配。
同样这种方式也可以提取两个元素:
import re
data='a1b1c---a2b2c---a3b3c---' #提取a、b、c之间的数字
result=re.findall('a(.*?)b(.*?)c',data)
print(result)
#结果
[('1', '1'), ('2', '2'), ('3', '3')]
此外用于筛选夹取(.*?)的信息也可以更加多元:
Str=“
<p class="name"><a href="/films/1215919" title="印度合伙人" data-act="boarditem-click" data-val="{movieId:1215919}">印度合伙人</a></p>
<p class="name"><a href="/films/123" title="龙猫" data-act="boarditem-click" data-val="{movieId:123}">龙猫</a></p>”
Data=re.findall(‘<p class="name"><a .*?>(.*?) </a></p>’,str,re.S)
print(Data)
#运行结果
['印度合伙人',‘龙猫’]
第一个参数中未加()的.*?表示标志信息任意,不录取。
实际操作中,我们爬取的就是网页的源码,在网页页面右键即可查看源码。