区块链扩容方案之——Rapidchain
摘要
- 一、写在前面
- 二、Rapidchain所面临的挑战
- 三、Rapidchain协议介绍
- 1. 协议概述
- 2. 引导阶段——Decentralized Bootstrapping
- 1)选举节点组成根小组
- 2)根小组负责选择参考委员会成员。
- 3)参考委员会将所有节点的集合随机划分为各个分片委员会,随后进入第一个时代。
- 3. 共识阶段:
- 1)委员会内部共识——Intra-Committee Consensus
- 2)跨分片交易处理——Cross-Shard Transactions
- 3)委员会间路由协议——Inter-Committee Routing
- 4. 委员会重构——Committee Reconfiguration
- 1)验证新加入节点
- 2)生成新的时代随机源
- 3)使用可解决分区攻击的有限的布谷鸟原则(Bounded Cuckoo Rule)来重构委员会。
- 5. 节点存储空间问题——Node storage
- 四、性能评估
- 五、Rapidchain的优点与不足
- 1. 优点
- 2. 限制与不足
一、写在前面
今天为大家介绍一个叫做Rapidchain的区块链扩容方案,Rapidchain通过使用状态分片(state sharding)技术完成对区块链性能的近乎线性扩展,同时也很大程度的解决了区块链扩容所面临的巨额存储成本的问题。对于包括状态分片在内的几种分片技术的介绍可以参考我之前的博客。
码字不易,如果觉得对您有用,请点个赞赏或订阅,后续会不定期更新区块链相关的文章。对于区块链有什么问题或想法,欢迎留言,大家一起探讨学习。
二、Rapidchain所面临的挑战
我认为要想利用状态分片技术对区块链的性能进行扩展,下面的几个挑战是必须要面临并解决:
1)如何完成第一个时代每个分片委员会的配置工作。
2)选择什么样的委员会内部共识协议。
3)如何高效地处理跨分片交易。
4)以什么样的方式对节点的身份进行验证;以什么样的方式将新节点随机分配到委员会中。
5)为了避免Sybil攻击和分区攻击,要定期对各个委员会进行“洗牌”。选择什么样的协议能高效并随机地对委员会进行重新配置。
接下来我们带着这几个问题,一起来看看Rapidchain采用什么样的方式解决这些难题。
三、Rapidchain协议介绍
1. 协议概述
在Rapidchain系统中主要包含三个重要阶段,分别是Bootstrapping phase(引导启动阶段)、Consensus phase(共识阶段)和Reconfiguration phase(重构阶段)。如下图所示:

Bootstrapping阶段只会在在Rapidchain系统开始时运行一次,这个阶段是为了创建一个初始随机源,并随机选出一个特殊的委员会,叫做参考委员会(reference committee)。再由这个参考委员会的成员对节点进行随机分配,构成一个个分片委员会。
在Rapidchain中也同样的使用了时代(epoch)这个概念,但和以往的区块链系统不同的是,每一个时代的共识阶段又被分成了多个轮次(round),这意味着在每个时代,委员会成员可以在不进行委员会重构的情况下进行多个轮次的交易验证工作,不必在频繁的委员会重构上浪费时间。
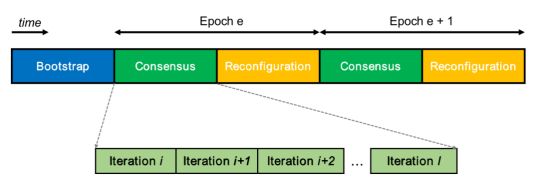
需要注意的是在共识阶段的每个轮次中,参考委员会每一个普通的分片委员一样,会进行交易的验证工作。
重构阶段,顾名思义,就是在每个时代结束前,验证并接收新加入的节点,通过一定的重构规则将新节点随机加入某个委员会。同时必须要保证每一个分片不会受到自适应对手控制。Rapidchain的重构方法会在后面的部分进行详细介绍。下面我将详细的介绍协议的每一个阶段:
2. 引导阶段——Decentralized Bootstrapping
1)选举节点组成根小组
Step1:每个初始的参与节点在本地使用硬编码参数和随机种子创建一个随机二分图G(L,R)。L为节点(Nodes),R为组(Groups)。R中的每一个节点的邻居们都是从L中随机独立且均匀选择出来的。这时候他们就从下图中的level0变到了level1。
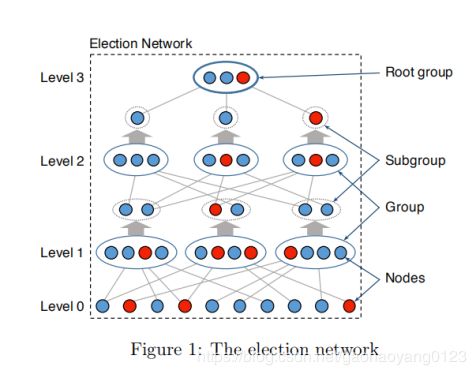
Step2:一旦形成初始组,每个小组内部运行DRG(分布式随机数生成算法)生成一个随机字符串s。然后每个节点把s和子集的ID进行一次哈希运算,哈希值落在某个区间内的节点广播宣称子集是被选中的节点,小组内的其他节点都对这些(ID, s)进行签名证明这些节点是被选中的节点。随后这些选中的节点把自己的身份(包含刚才提到的证明)广播到整个网络中。
Step3:网络中重复多次Step1和Step2,直到最终选出一定数量大小的根小组(root group),如上图所示。
2)根小组负责选择参考委员会成员。
3)参考委员会将所有节点的集合随机划分为各个分片委员会,随后进入第一个时代。
3. 共识阶段:
1)委员会内部共识——Intra-Committee Consensus
在共识阶段的每个轮次(round)中,首先Step1,每个委员会使用时代随机源(epoch randomness)选出一个领导者(leader);然后Step2,领导收集来自客户端的交易并打包成区块Bi;Step3,领导者使用IDA-Gossip协议将块Bi广播,并创建一个包含merkle tree和轮次数的区块头Hi;Step4,委员会成员针对区块头Hi启动共识协议。
注:IDA-Gossip protocol,即information dispersal algorithm gossip protocol。IDA是一种信息分散算法,由于篇幅问题,这里不做详细解释,大家知道通过这个协议可以更快速传播大型消息并可以快速验证消息是否正确就可以了。
在最后一步的Step4中,委员会成员按照下图中的三个步骤针对区块头Hi达成共识:
① 领导为区块头Hi加上一个propose标签,并通过八卦网络广播Hi。
② 各个节点收到区块头Hi后,每个节点对收到的Hi进行回应,并为Hi加上一个回应标签(echo tag),同样通过八卦网络广播出去。
③ 如果节点收到了不同版本的区块头,这就意味着领导者是恶意的,节点可以通过广播一个待定标签(pending tag)来拒绝这个区块;反之,如果节点只收到一个Hi,并且收到了多于mf+1个回应标签(echo tag),这就意味着委员会对区块Bi达成了共识。一旦委员会内部达成了共识,每个收到至少mf+1个回应标签(echo tag)的节点再次广播这个区块头并加上一个接收标签(accept tag)和一个证明。

注释:m是委员会节点数量,f是委员会内恶意节点比例,则每个委员会内的恶意节点数最多有mf个,当节点收到至少mf+1个回应标签就意味着至少有一个诚实节点检查并接受了领导者创建的区块。原理等同于PBFT的f+1。
2)跨分片交易处理——Cross-Shard Transactions
如何安全快速地处理跨分片交易一直以来是状态分片所面临的最大难题。对存储状态进行分片就意味着系统中的每个节点都只存储部分账本而非完整的账本。Rapidchain的设计是基于UTXO模型的,当一笔跨分片交易发生时,系统会根据该交易的输出(output)哈希,把交易分配到对应的委员会,而接收这笔交易的委员会就称为输出委员会(output committee)。同时,这笔交易可能同时拥有多个输入,并且每一个输入都来自于不同的分片,这笔交易的输入所在的委员会被称为输入委员会(input committee)。
当客户端提交一笔交易,且系统把这笔交易分配到对应的输出委员会,这笔交易可能包含多个输入,且输入存储在其他的委员会中。为了验证交易的有效性,输出委员会的验证节点必须能够验证每一个输入的有效性。那么如何去验证来自其他分片的输入是否有效呢?OmniLedger和Rapidchain提供了两种完全不同的思路。
在OmniLedger的解决方案中,客户端首先向输入委员会提出请求,希望每一个输入委员会为自己的资产提供证明(proof-of-acceptance)。各个输入委员会检查相应的UTXO,如果UTXO无误,锁定相应的UTXO并把资产证明反馈给客户端;如果UTXO有误,委员会向客户端返回一条拒绝消息(proof-of-reject)。客户端收集所有输入委员会的资产证明后提交给输出委员会。输出委员会验证通过后,客户端发出“unlock to commit”解锁提交指令,完成交易。
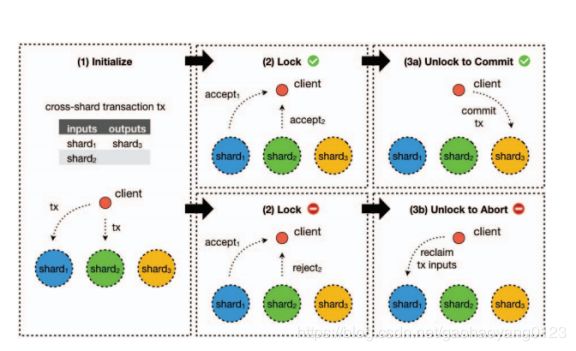
OmniLedger这种处理跨分片交易的方式保证了交易处理的原子性,但是也存在以下几个显在的缺陷:
首先,客户端需要广播交易到整个网络,并且对于每一笔交易都需要至少一个证明被生成并提交,这导致整个网络需要大量的通讯开销。
另一个问题是,系统太过于依赖客户端,违背了轻客户端原则。这样也要求客户端必须了解整个网络结构。
Rapidchain针对上面的几点缺陷进行了改善,首先客户端不再需要向每个输入委员会请求资产证明。客户端也不需要了解整个网络,他们只需要把交易发送到任意委员会,然后交易会通过委员会间路由协议(inter-committee routing protocol)被路由到输出委员会。
交易的处理流程我将通过下面的例子进行介绍:
我们假设有一笔交易tx,这笔交易存在两个输入In1和In2和一个输出Out,且这两个输入和输出分别属于不同的分片委员会Shard1,2,3。那么输出委员会的Leader会创建三笔新的交易,分别如下:
① Tx1把来自Shard1的Input转化成Shard3的Output。(相当于把Shard1里面的相应的钱转移到Shard3中)
② Tx2把来自Shard2的Input转化成Shard3的Output。(相当于把Shard2里面的相应的钱转移到Shard3中)
③ 通过以上两笔交易,现在所有的Input和Output都属于同一个分片了,接下来就创建一个交易Tx3,输入是Tx1和Tx2的输出,输出同原交易相同。
输出委员会的Leader会通过委员会间路由协议把Tx1和Tx2分别发送给Shard1和Shard2。然后Shard1和Shard2的Leader会分别验证相应交易的有效性,如果有效,他们会分别把交易加入到本分片的账本中,并向Shard3做出回复。Shard3收到了所有输入委员会的回复后会把Tx3加入到自己的账本中。
注:分片间的确认请求可以进行批量处理。在每一轮中输出委员会可以把属于同一个输入委员会的UTXO交易组合,一次性地批量发送给输入委员会。这样输入委员会也同样可以批量验证UTXO交易地有效性,并统一向输出委员会做出反馈,这样可以大大地减少委员会间地通讯复杂度。
3)委员会间路由协议——Inter-Committee Routing
RapidChain需要一种路由方案,使客户端和委员会Leader能够快速找到他们应该发送交易的委员会。传统的解决方案有下面两种:
① 让每个节点存储所有委员会成员的网络信息。这样每个节点都可以快速定位到任何成员的IP并进行通讯。显然这样做的扩展性很弱,每个节点都要连接大量的节点,很难应用到数千个节点网络中。
② 另一个解决方案是让参考委员会来负责交易路由。每个用户或委员会Leader通过参考委员会来获取网络信息,通过参考委员会来路由交易。但是这会导致参考委员会的工作过于繁重,需要处理大量的通讯,存在单一分片过热的风险。
最终,Rapidchain的路由协议借鉴了Kademlia路由算法的设计思路。简单来说就是每个节点存储同委员会成员全部节点的路由信息,同时只存储属于距离自己所在委员会最近的log(n)个委员会内的log log(n)个节点的信息。
注:这句话有点绕,换句话来解释是,每个节点挑log(n)个距离自己所在委员会最近的委员会,然后再从每个委员会中挑loglog(n)个节点,只存储这些节点的信息,而不是网络中的所有节点。
对于委员会间的消息,每一个发送者只发送给他所知道的目标委员会的节点。然后收到消息的节点再用上文提到的IDA-gossip协议发送给所在委员会的其他成员。而对于客户端用户,他们只需要把交易提交给任意委员会,然后委员会之间再通过Kademlia路由协议把交易转发给目标委员会。
4. 委员会重构——Committee Reconfiguration
1)验证新加入节点
在每个时代结束前,参考委员会都会生成一个时代随机源(epoch randomness)用于下个时代。在每一个时代,委员会节点进行交易验证的同时,想要加入网络中其他节点们正在本地寻找着PoW解决方案,而这个PoW解决方案必须依赖于上一个时代的随机源。要求节点寻找PoW拼图是为了抵御Sybil attach,即女巫攻击。而PoW解决方案必须依赖于epoch randomness是为了避免节点的解决方案是提前计算好的。
当时代进行到委员会重构阶段,所有希望加入委员会的新节点把自己找到的解决方案提交给参考委员会,参考委员会负责验证PoW solution的正确性。如何正确参考委员会的Leader会把新节点按照有边界的布谷鸟原则随机分配到各个委员会中。
2)生成新的时代随机源
在每个时期的重构阶段,参考委员会的成员还会运行DRG protocol(distribute random generation protocol)针对一个无偏差随机值达成共识。随后这个随机源会被包含到一个参考区块中(reference block)发送给网络中的每一个成员。而Rapidchain选择用费尔德曼的可验证秘密共享协议来生成这个随机源。
注:费尔德曼的可验证秘密共享协议即verifiable secret sharing(VSS)of Feldman protocol,原理可以参考维基百科,由于篇幅问题就不做扩展了。https://en.wikipedia.org/wiki/Verifiable_secret_sharing
生成随机源的步骤概括如下:
Step1:每个参考委员会节点选取一个素数阶Pi
Step2:每个节点VSS-share他们选择的数字给委员会的所有其他成员。
Step3:每个节点j将会收到m个来自于其他节点的分享,分别为P1j, P2j, P3j,…Pmj。
Step4:最后通过求和运算,然后再用拉格朗日插值技术重建结果得到epoch randomness。
3)使用可解决分区攻击的有限的布谷鸟原则(Bounded Cuckoo Rule)来重构委员会。
在分片区块链系统中,分片容易收到分区攻击,即单一分片内,离线或者恶意节点超过了可承受比例,或者导致协议无法正常进行,严重的还有可能在该分片账本上记录错误的信息。所以为了避免这种分区攻击的发生,我们必须定期对各个委员会进行洗牌。
我在以前的文章中介绍过Elastico的方案,Elastico的委员会重构方式是把委员会节点全部打散,重新选举所有委员会。但是这种方式有两个致命缺点:
① 重新选举所有委员会开销很大,需要花费很长的时间,导致分片系统性能得不到大幅度提升。
② 如果节点总是被全部打乱,很难为每个委员会位置一个独立的账本。由于状态分片的初衷就是把账本在分片中分别存储从而降低存储空间。但是显然全部打乱重新分配的方式无法达到预期效果。
所以,我们明白,在状态分片系统中,不能把系统中全部节点打乱并重新配置所有委员会,只能对委员会进行微调。我们需要找到一个协议,既能把新节点随机加入到委员会中,同时也可以抵抗自适应对手的分区攻击。Rapidchain的解决方案十分出色,它在布谷鸟原则(Cuckoo rule)的基础上进行更改,创造出有限的(Bounded)布谷鸟原则来解决上面提到的挑战。
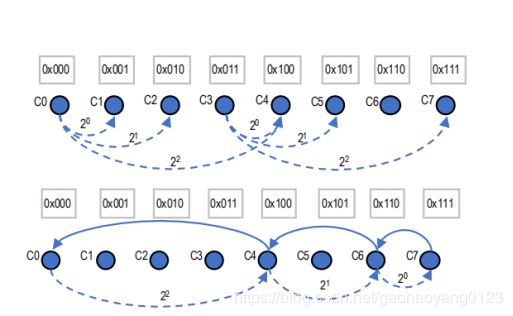
① 布谷鸟原则(Cuckoo Rule)
布谷鸟原则的原理很简单,首先把每一个节点随机地摆放在[0,1]区间内,然后把这个区间分成k个区域,每个区域中的一组节点就组成了一个个委员会。当一个新的节点加入时,他被随机放在一个位置,则同区域内就会有固定数量的节点被移动到其他不同的随机区域。演示参考下面动图:

② 有限布谷鸟原则(Bounded Cuckoo Rule)
每个时代,参考委员会都会把委员会分成两类,分别是活跃成员占大多数的活跃委员会,和不活跃成员占大多数的消极委员会。
当新节点加入时,参考委员会把节点随机加入到某个活跃委员会中,并把该委员会中的固定数量节点随机加入到不同的消极委员会中。演示参考下面动图:
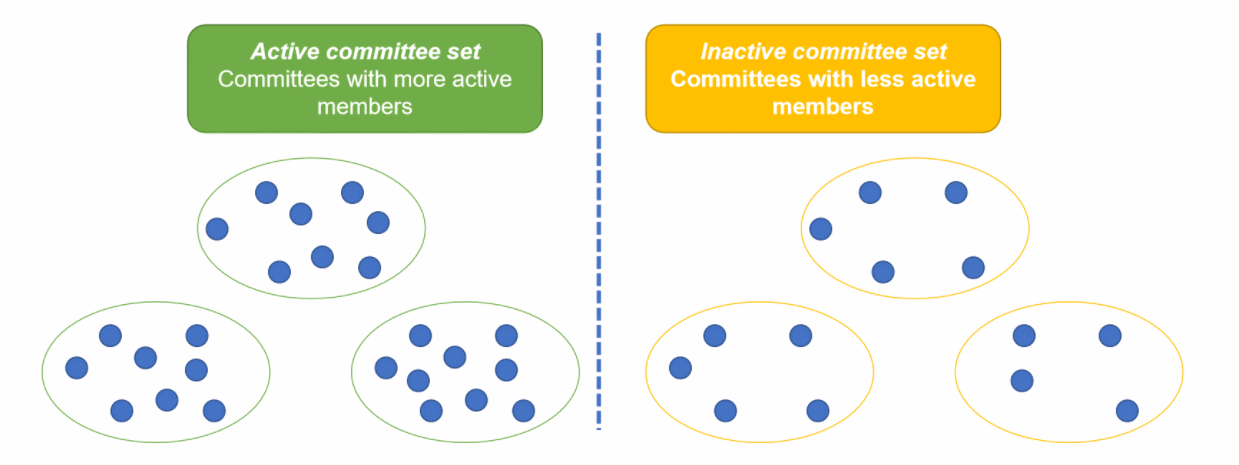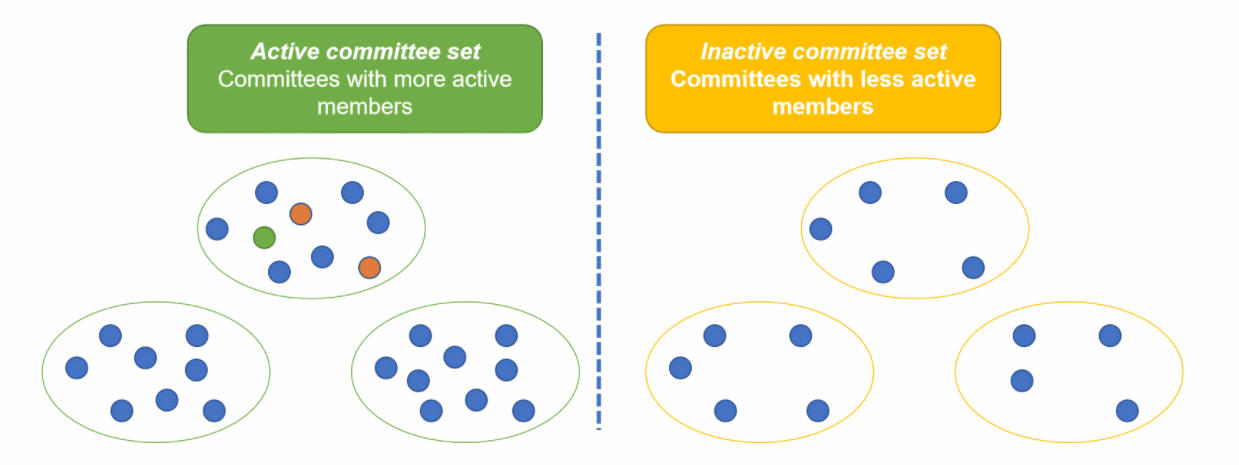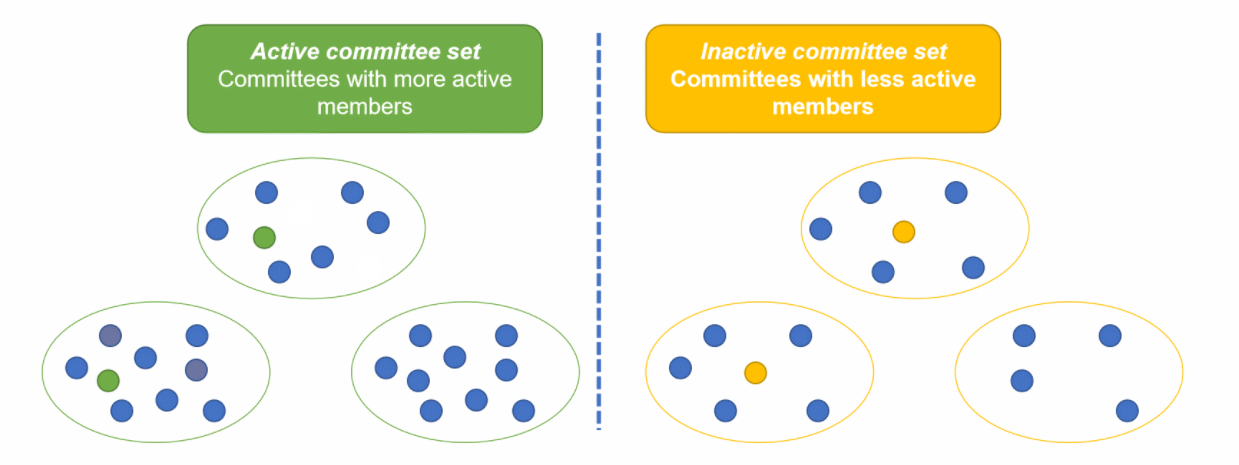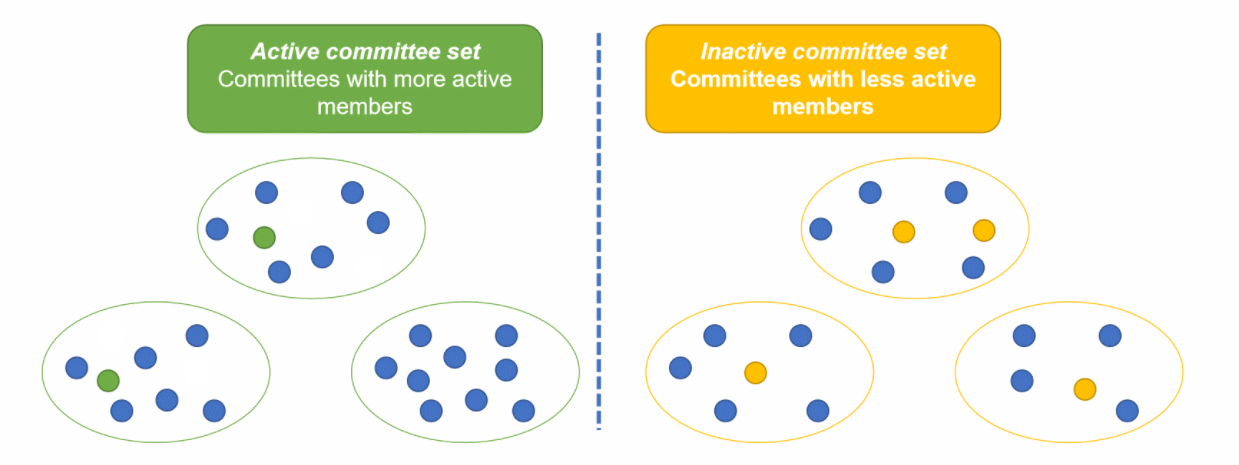
5. 节点存储空间问题——Node storage
节点存储空间不需要过多的赘述,Rapidchain使用的是状态分片的思想,所以系统中每一个节点只需要存储自己所在分片的所有区块和UTXO信息即可,理论上对存储空间完成了线性扩展,把存储空间降低到原来的1/k,k是分片的数量。
但是个人认为实际上无法达到这样的理想状态,因为我们从前面介绍的跨分片交易特性中得知,一笔跨分片交易有可能最终被拆分成三笔甚至更多笔交易存储在不同分片中,所以个人认为对存储空间的扩展效果不大。
当然这也是UTXO模型的特性导致,如果系统使用基于账户的模型,且用户只能在一个分片中有账户,这样就可以大幅地降低各个分片地存储空间消耗了,所以个人认为相比UTXO模型,基于账户地模型更加适合状态分片系统。
四、性能评估
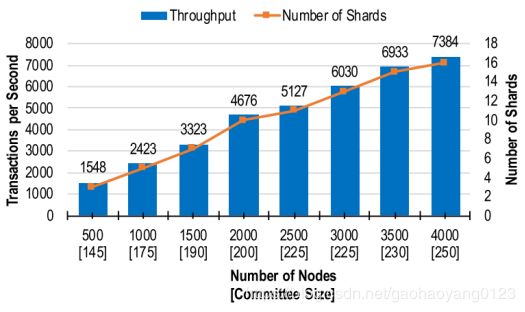
对于性能的评估我就直接上图了,简单地对目前主流的几种方案进行对比。
对于区块链扩容来说最看重的两个参数莫过于吞吐量和延迟,理论上当节点数达到4000,16个委员会的情况下,吞吐量可以达到7384tps,从图中可以看出几乎实现了对吞吐量的线性扩展,即吞吐量随着委员会数量的增加线性增加。针对延迟,分别对交易确认延迟和用户感知延迟进行了测试。同样4000节点的情况下,交易确认延迟达到8.84秒,是现有分片系统中最低值,达到了秒级水平。但是用户感知延迟则相对高了很多,大约70秒,它意味着从用户发送交易到网络中直到交易得到确认为止这段时间,受到多方面因素影响,包括网络延迟、路由延迟、交易队列等待等诸多因素。但是70秒依然是目前所有方案中的最佳。

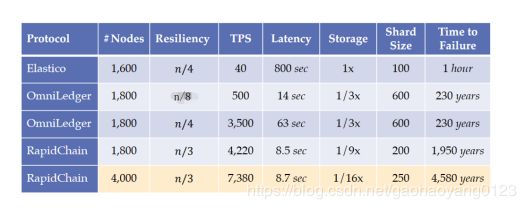
我们把Rapidchain的性能和Elastico、OmniLedger做一个简单的比较。显然,无论是可容纳节点数,委员会内可容纳恶意节点比例,还是吞吐量、延迟和存储性能都是远远优于其他的分片系统的。还有对于系统安全最重要的参数,就是系统失败时间,这方面Rapidchain也远优于二者,这意味着Rapidchain可以持续安全运行下去,系统健壮性更好。
五、Rapidchain的优点与不足
1. 优点
-
Rapidchain的优点有很多,首先它在很多方面为状态分片系统提供了创新的思路,它的这设计思路和系统架构有很大的参考价值。例如跨分片交易的处理方式、分片接路由协议、委员会重构方案、每个时代多轮次协议等。
-
对各方面性能都有着显著的提升,把系统可容忍恶意节点比例提高到1/3,吞吐量提高到高达7380tps,交易确认延迟降低到秒级,系统健壮性显著提升。
2. 限制与不足
-
同步网络假设,在现实的异步网络中是否能保持高性能存疑。
-
对于跨分片交易的处理可能存在安全隐患。我们试想一下,如果用户大量发送虚假交易,即交易输入分片中的input不足。输出分片需要把各个输入分片中的资产转移到自己所在分片中后在对交易进行验证处理,这样系统会陷入不断地分片间资产转移中,无法完成正常的交易验证。
-
针对每个轮次领导者如何随机选举,Rapidchain没有做出具体说明。只是说明利用epoch randomness随机选举。但是如果单纯利用时代随机源进行选举,那么每个轮次选出的领导者应该是同一个节点,所以需要辅助以其他的方式来保证每个轮次可以有不同的节点被选出。
-
委员会内部共识本质上来讲还是基于PBFT的共识协议,所以通讯开销依然很高,个人觉得需要对委员会内部共识进行优化,例如使用通讯复杂度更低的FBFT、SBFT等,使用BLS签名替代传统的签名方式。
-
VSS方法可能存在潜在的不安全因素:恶意节点可能会向不同节点发送不一致的共享。
-
系统依赖于PoW工作量证明,虽然验证节点共识和新节点寻找PoW拼图并行进行,但是依然是对电力的一种浪费。完全可以利用PoS股权质押加上VRF的方式来抵御sybil攻击。
-
委员会进行重组时,新加入的节点和改变了委员会的节点需要花费很多的时间来下载新分片的全部区块,更新自己本地的UTXO数据,这可能需要花费大量的时间,系统有可能因此不得不停机等待。所以我认为可能需要类似OmniLedger的pruning(修剪)技术,各个分片在重组前针对一个状态区块达成共识,状态区块中储存UTXO信息,并把状态区块连接到区块链上。这样上面的这些节点可以优先更新状态区块完成交易验证,而不是必须下载所有区块来构建本地的UTXO。
参考资料
Rapidchain 白皮书:https://eprint.iacr.org/2018/460.pdf
网络、交易、状态分片对比:https://blog.csdn.net/gaohaoyang0123/article/details/96743105
区块链扩容方案之——ELASTICO:https://blog.csdn.net/gaohaoyang0123/article/details/97626420
码字不易,如果觉得文章对你有帮助,请点个赞赏表示对本人的支持,谢谢!
后续会不定期更新区块链相关文章,感兴趣的朋友可以订阅。