python实现爬取猫眼并初步分析数据
本文通过爬取猫眼top100,利用Request请求库和4种内容提取方法:正则表达式、lxml+xpath、Beatutifulsoup+css选择器、Beatutifulsoup+find_all爬取网页内容,熟悉常用的这些提取方法。
爬取目标
- 从网页中提取出top100电影的电影名称、封面图片、排名、评分、演员、上映国家/地区、评分等信息,并保存为csv文本文件。
- 根据爬取结果,进行简单的可视化分析。
需要用到的库
import requests
import re
import time
import csv
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
from lxml import etree如何爬取数据
利用requests来爬取网页,实现代码如下!
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
try:
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
return None下面介绍四种解析方式!
正则表达式提取
正则表达式的用法参看https://www.runoob.com/python/python-reg-expressions.html
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?).*?star">(.*?)'
'.*?releasetime">(.*?)(.*?).*?fraction">(.*?).*? ', re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index': item[0],
'thumb': get_thumb(item[1]),
'name': item[2],
'star': item[3].strip()[3:],
# 'time': item[4].strip()[5:],
# 用函数分别提取time里的日期和地区
'time': get_release_time(item[4].strip()[5:]),
'area': get_release_area(item[4].strip()[5:]),
'score': item[5].strip() + item[6].strip()
}上面程序为了便于提取内容,又定义了3个方法:get_thumb()、get_release_time()和 get_release_area():
# 提取上映时间函数
def get_release_time(data):
pattern = re.compile(r'(.*?)(\(|$)')
items = re.search(pattern, data)
if items is None:
return '未知'
return items.group(1) # 返回匹配到的第一个括号(.*?)中结果即时间
# 提取国家/地区函数
def get_release_area(data):
pattern = re.compile(r'.*\((.*)\)')
# $表示匹配一行字符串的结尾,这里就是(.*?);\(|$,表示匹配字符串含有(,或者只有(.*?)
items = re.search(pattern, data)
if items is None:
return '未知'
return items.group(1)
# 获取封面大图
#http://p0.meituan.net/movie/5420be40e3b755ffe04779b9b199e935256906.jpg@160w_220h_1e_1c
# 去掉@160w_220h_1e_1c就是大图
def get_thumb(url):
pattern = re.compile(r'(.*?)@.*?')
thumb = re.search(pattern, url)
return thumb.group(1)lxml+xpath提取
xpath的具体用法参考这篇博文https://cuiqingcai.com/5545.html
def parse_one_page2(html):
parse = etree.HTML(html)
items = parse.xpath('//*[@id="app"]//div//dd')
# 完整的是//*[@id="app"]/div/div/div[1]/dl/dd
# print(type(items))
# *代表匹配所有节点,@表示属性
# 第一个电影是dd[1],要提取页面所有电影则去掉[1]
# xpath://*[@id="app"]/div/div/div[1]/dl/dd[1]
for item in items:
yield{
'index': item.xpath('./i/text()')[0],
#./i/text()前面的点表示从items节点开始
#/text()提取文本
'thumb': get_thumb(str(item.xpath('./a/img[2]/@data-src')[0].strip())),
# 'thumb': 要在network中定位,在elements里会写成@src而不是@data-src,从而会报list index out of range错误。
'name': item.xpath('./a/@title')[0],
'star': item.xpath('.//p[@class = "star"]/text()')[0].strip(),
'time': get_release_time(item.xpath(
'.//p[@class = "releasetime"]/text()')[0].strip()[5:]),
'area': get_release_area(item.xpath(
'.//p[@class = "releasetime"]/text()')[0].strip()[5:]),
'score' : item.xpath('.//p[@class = "score"]/i[1]/text()')[0] + \
item.xpath('.//p[@class = "score"]/i[2]/text()')[0]
}用beautifulsoup + css选择器提取
beautiful的教程请参考https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
css选择器请参考http://www.w3school.com.cn/cssref/css_selectors.asp
def parse_one_page3(html):
soup = BeautifulSoup(html, 'lxml')
items = range(10)
for item in items:
yield{
'index': soup.select('dd i.board-index')[item].string,
# iclass节点完整地为'board-index board-index-1',写board-index即可
'thumb': get_thumb(soup.select('a > img.board-img')[item]["data-src"]),
# 表示a节点下面的class = board-img的img节点,注意浏览器eelement里面是src节点,而network里面是data-src节点,要用这个才能正确返回值
'name': soup.select('.name a')[item].string,
'star': soup.select('.star')[item].string.strip()[3:],
'time': get_release_time(soup.select('.releasetime')[item].string.strip()[5:]),
'area': get_release_area(soup.select('.releasetime')[item].string.strip()[5:]),
'score': soup.select('.integer')[item].string + soup.select('.fraction')[item].string
}Beautiful Soup + find_all函数提取
def parse_one_page4(html):
soup = BeautifulSoup(html,'lxml')
items = range(10)
for item in items:
yield{
'index': soup.find_all(class_='board-index')[item].string,
'thumb': soup.find_all(class_ = 'board-img')[item].attrs['data-src'],
# 用.get('data-src')获取图片src链接,或者用attrs['data-src']
'name': soup.find_all(name = 'p',attrs = {'class' : 'name'})[item].string,
'star': soup.find_all(name = 'p',attrs = {'class':'star'})[item].string.strip()[3:],
'time': get_release_time(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]),
'area': get_release_time(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]),
'score':soup.find_all(name = 'i',attrs = {'class':'integer'})[item].string.strip() + soup.find_all(name = 'i',attrs = {'class':'fraction'})[item].string.strip()
}数据的存储
def write_to_file(item):
with open('猫眼top100.csv', 'a', encoding='utf_8_sig',newline='') as f:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score']
w = csv.DictWriter(f,fieldnames = fieldnames)
# w.writeheader()
w.writerow(item)封面的下载
def download_thumb(name, url,num):
try:
response = requests.get(url)
with open('./' + name + '.jpg', 'wb') as f:
f.write(response.content)
print('第%s部电影封面下载完毕' %num)
print('------')
except RequestException as e:
print(e)
pass
# 存储格式是wb,因为图片是二进制数格式,不能用w,否则会报错
主函数的实现
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
# print(html)
# parse_one_page2(html)
for item in parse_one_page(html): # 切换内容提取方法
print(item)
write_to_file(item)
# 下载封面图
download_thumb(item['name'], item['thumb'],item['index'])
if __name__ == "__main__":
for i in range(10):
main(i * 10)
time.sleep(5)到这里,我们就把爬虫部分全部实现了。
下面我们对这些得到的数据进行简单的分析。
电影评分最高top10
import pandas as pd
import matplotlib.pyplot as plt
import pylab as pl
plt.style.use('ggplot')
fig = plt.figure(figsize=(8,5))
colors = '#6D6D6D'
columns = ['index','thumb','name','star','time','area','score']
df = pd.read_csv('猫眼top100.csv',encoding="utf-8",header=None,names =columns,index_col = 'index')
df_core = df.sort_values('score',ascending=False)
name = df_core.name[:10]
score = df_core.score[:10]
plt.bar(range(10),score,tick_label = name,)
plt.ylim((9,9.8))
plt.title('电影评分最高top100',color = colors)
plt.xlabel('电影名称')
plt.ylabel('评分')
for x,y in enumerate(list(score)):
plt.text(x,y+0.01,'%s' %round(y,1),ha = 'center',color = colors)
pl.xticks(rotation = 270)
plt.tight_layout()
plt.show()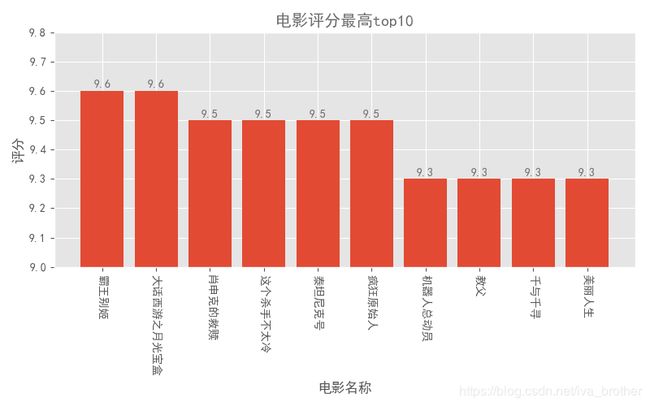
各国家的电影数量比较
area_count = df.groupby(by = 'area').area.count().sort_values(ascending=False)
# 绘图方法1
area_count.plot.bar(color = '#4652B1') #设置为蓝紫色
pl.xticks(rotation=0) #x轴名称太长重叠,旋转为纵向
for x,y in enumerate(list(area_count.values)):
plt.text(x,y+0.5,'%s' %round(y,1),ha = 'center',color = colors)
plt.title('各国/地区电影数量排名')
plt.xlabel('国家/地区')
plt.ylabel('数量(部)')
plt.show()
电影作品数量集中的年份
# 从日期中提取年份
df['year'] = df['time'].map(lambda x:x.split('/')[0])
# 统计各年上映的电影数量
grouped_year = df.groupby('year')
grouped_year_amount = grouped_year.year.count()
top_year = grouped_year_amount.sort_values(ascending = False)
# 绘图
top_year.plot(kind = 'bar',color = 'orangered') #颜色设置为橙红色
for x,y in enumerate(list(top_year.values)):
plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors)
plt.title('电影数量年份排名')
plt.xlabel('年份(年)')
plt.ylabel('数量(部)')
plt.tight_layout()
plt.show()
拥有电影作品数量最多的演员
#表中的演员位于同一列,用逗号分割符隔开。需进行分割然后全部提取到list中
starlist = []
star_total = df.star
for i in df.star.str.replace(' ','').str.split(','):
starlist.extend(i)
# print(starlist)
# print(len(starlist))
# set去除重复的演员名
starall = set(starlist)
starall2 = {}
for i in starall:
if starlist.count(i)>1:
# 筛选出电影数量超过1部的演员
starall2[i] = starlist.count(i)
starall2 = sorted(starall2.items(),key = lambda starlist:starlist[1] ,reverse = True)
starall2 = dict(starall2[:10]) #将元组转为字典格式
# 绘图
x_star = list(starall2.keys()) #x轴坐标
y_star = list(starall2.values()) #y轴坐标
plt.bar(range(10),y_star,tick_label = x_star)
pl.xticks(rotation = 270)
for x,y in enumerate(y_star):
plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors)
plt.title('演员电影作品数量排名',color = colors)
plt.xlabel('演员')
plt.ylabel('数量(部)')
plt.tight_layout()
plt.show()
参考博客:https://www.makcyun.top/2018/08/20/web_scraping_withpython1.html