网上爬取图片制作成数据集进行训练
一、用pthon爬取图片
如图:
创建一个文件夹,下放每一类的文件夹(我的绝对路径是:/home/user/dataset/)
在每一个class下面,创建一个test.py文件,用以爬取图片
# coding=utf-8
"""根据搜索词下载百度图片"""
import re
import sys
import urllib
import requests
def get_onepage_urls(onepageurl):
"""获取单个翻页的所有图片的urls+当前翻页的下一翻页的url"""
if not onepageurl:
print('已到最后一页, 结束')
return [], ''
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
fanye_url = ''
return pic_urls, fanye_url
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
fanye_urls = re.findall(re.compile(r'下一页'), html, flags=0)
fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
return pic_urls, fanye_url
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1200) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
if __name__ == '__main__':
keyword = '笔记本电脑' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
url_init = url_init_first + urllib.parse.quote(keyword, safe='/')
all_pic_urls = []
onepage_urls, fanye_url = get_onepage_urls(url_init)
all_pic_urls.extend(onepage_urls)
fanye_count = 1 # 累计翻页数
while 1:
onepage_urls, fanye_url = get_onepage_urls(fanye_url)
fanye_count += 1
print('第%s页' % fanye_count)
if fanye_url == '' and onepage_urls == []:
break
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))基本上只需要改变keyword和命名就可以以每次60张图片的速度进行爬取。
具体命令如下:
cd /home/user/dataset/class0
python test.py
在下载过程中会有提示,class1也是一样。下载完批量的图片以后就要开始选择要用什么框架训练数据集。(因为一直在学习mxnet,所以选择了mxnet,mxnet主要将图片数据生成rec文件,有一个im2rec.py专门将图片生成rec文件,具体步骤如下:
1)生成lst文件
recursive:是否递归访问子目录,如果存在多个目录可以设置该参数
list::脚本默认为False,所以制作lst时应设置为True
prefix:需要生成的lst文件的前缀(这里我命名为test,就会生成test.lst)
root:指定数据集的根目录,其子目录为图片或进一步的子目录(注意:路径一定要写对!!!)
终端命令为:python ~/mxnet/tools/im2rec.py --recursive --list test /home/user/dataset/
随后,在我的目录下面就生成了lst文件
打开lst文件是这样的:
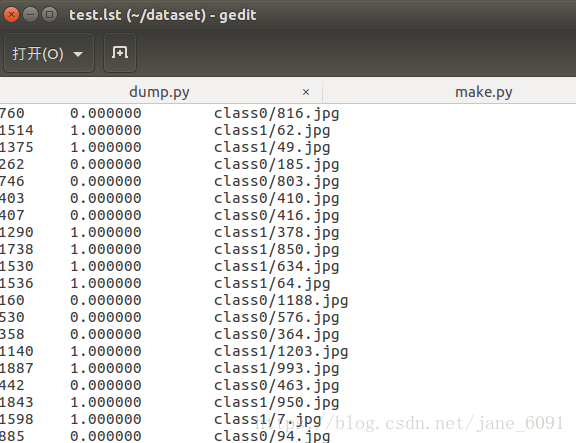
第一行是图片大小,中间是类别,后面是相对路径
2)生成rec文件
涉及参数:
–list 是否创建list文件,默认为False
–exts 所能接受的图片后缀,默认为jpg和jpeg(如果图片是png格式,可以对im2rec.py文件进行修改)
–chunks 分块数量,默认为1
–train-ratio 训练集所占的比例,默认为1.0
–test-ratio 测试集所占的比例,默认为0
–recursive 是否递归的对root下的文件夹进行遍历
–shuffle 是否打乱list中的图片顺序,默认为True
–pass-through 是否跳过transform,默认为False
–resize 是否将短边缩放至设定尺寸,默认为0
–center-crop 是否进行中心剪裁,默认为False
–quality 图片解码质量(0-100),默认为95
–num-thread 编码的线程数,默认为1
–color 色彩解码模式[-1,0,1],-1为彩色模式,0为灰度模式,1为alpha模式,默认为1
–encoding 解码模式(jpeg,png),默认为jpeg
–pack-label 是否读入多维度标签数据,默认为False 如果进行多标签数据制作或者目标检测的数据制作,那么就必须将其设置为True
终端命令:python ~/mxnet/tools/im2rec.py --recursive test /home/user/dataset/
然后就在该路径下生成了一个rec后缀和一个idx文件,里面是bin格式,所以一般打不开。这里就不打开了。
截图:

生成了rec文件以后,就需要在网络中训练了。
import sys sys.path.insert(0, '..') import gluonbook as gb import mxnet as mx from mxnet import autograd, nd, gluon, init from mxnet.gluon import loss as gloss, nn from time import time import os from skimage import io import numpy as np class Residual(nn.HybridBlock): def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs): super(Residual, self).__init__(**kwargs) self.conv1 = nn.Conv2D(num_channels, kernel_size=3, padding=1, strides=strides) self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1) if use_1x1conv: self.conv3 = nn.Conv2D(num_channels, kernel_size=1, strides=strides) else: self.conv3 = None self.bn1 = nn.BatchNorm() self.bn2 = nn.BatchNorm() def hybrid_forward(self, F, X): Y = F.relu(self.bn1(self.conv1(X))) Y = self.bn2(self.conv2(Y)) if self.conv3: X = self.conv3(X) return F.relu(Y + X) def resnet18(num_classes): net = nn.HybridSequential() net.add(nn.Conv2D(64, kernel_size=3, strides=1, padding=1), nn.BatchNorm(), nn.Activation('relu')) def resnet_block(num_channels, num_residuals, first_block=False): blk = nn.HybridSequential() for i in range(num_residuals): if i == 0 and not first_block: blk.add(Residual(num_channels, use_1x1conv=True, strides=2)) else: blk.add(Residual(num_channels)) return blk net.add(resnet_block(64, 2, first_block=True), resnet_block(128, 2), resnet_block(256, 2), resnet_block(512, 2)) net.add(nn.GlobalAvgPool2D(), nn.Dense(num_classes)) return net def get_net(ctx): num_classes = 2 net = resnet18(num_classes) net.initialize(ctx=ctx, init=init.Xavier()) return net batch_size = 32 train_iter = mx.image.ImageIter( batch_size = batch_size, data_shape = (3, 256,256), path_imgrec = 'test.rec', path_imgidx = 'test.idx', #help shuffle performance shuffle = True, #aug_list=[mx.image.HorizontalFlipAug(0.5)] ) train_iter.reset() for batch in train_iter: x = batch.data[0] y = batch.label[0] print(x) print('y is' ,y) break def try_gpu(): try: ctx = mx.gpu() _ = nd.zeros((1,), ctx=ctx) except: ctx = mx.cpu() return ctx ctx = try_gpu() ctx def evaluate_accuracy(data_iter, net, ctx): acc = nd.array([0], ctx=ctx) for X, y in data_iter: # 如果 ctx 是 GPU,将数据复制到 GPU 上。 X = X.as_in_context(ctx) y = y.as_in_context(ctx) acc += gb.accuracy(net(X), y) return acc.asscalar() / len(data_iter) def train_ch5(net, train_iter, loss, batch_size, trainer, ctx, num_epochs): print('training on', ctx) for epoch in range(1, num_epochs + 1): train_l_sum = 0 train_acc_sum = 0 start = time() for batch in train_iter: X = batch.data[0] y = batch.label[0] # 如果 ctx 是 GPU,将数据复制到 GPU 上。 print(X,y) X = X.as_in_context(ctx) y = y.as_in_context(ctx) with autograd.record(): net = get_net(ctx) y_hat = net(X) l = loss(y_hat, y) l.backward() trainer.step(batch_size) train_l_sum += l.mean().asscalar() train_acc_sum += gb.accuracy(y_hat, y) #test_acc = evaluate_accuracy(test_iter, net, ctx) print('epoch %d, loss %.4f, train acc %.3f, ' 'time %.1f sec' % (epoch, train_l_sum / len(train_iter), train_acc_sum / len(train_iter), time() - start)) lr = 0.8 num_epochs = 5 net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier()) trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr}) loss = gloss.SoftmaxCrossEntropyLoss() train_ch5(net, train_iter, loss, batch_size, trainer, ctx, num_epochs)这里简单的用了resnet18作为网络进行训练,大家可以使用适合自己数据集的网络进行训练。 祝大家玩的愉快!有什么问题可以一起探讨~~