图像分割/二值化
1 阈值化
当用照像机拍摄一副黑纸白字的纸张时,照相机获得的图像并不是真正的黑白图像。不管从什么角度拍摄,这幅图像实际上是灰度或者彩色的。除非仔细的设置灯光,否则照相机所拍摄的放在桌子上的纸张图像并不能代表原始效果。不像在扫描仪或打印机内部,想控制好桌子表面的光源是非常困难的。这个开放的空间可能会受到台灯、吊灯、窗户、移动的影子等影响。人类的视觉系统能自动补偿这些,但是机器没有考虑到这些因素因此拍出的效果会很差。
计算机视觉中摄像头会产生一副具有不同等级的灰度图像,但在许多应用都必须清楚的知道图像的那一部分是纯黑或纯白,以便将文字传递给OCR软件去识别,选择复制操作,或多个图像合成,系统就不可以使用抖动的图像,系统仅仅需要简单的线条、文字或相对大块的黑色和白色。从灰度图像获得这种黑白图像的过程通常称作为阈值化。
2 二值化原理
阈值化图像其实就是对灰度图像进行二值化操作,根本原理是利用设定的阈值判断图像像素为0还是255,所以在图像二值化中阈值的设置很重要。图像的二值化分为全局二值化和局部二值化,其区别在于阈值是否在一张图像进行统一。
2.1 全局化阈值
全局阈值法方法就是将图像中低于某个阈值的像素设置为黑色,而其他的设置为白色。常见的算法就是选择所有可能取值的中间值,因此对于8位深的图像(范围从0到255),128将会被选中。这个方法在图像黑色像素确实在128以下,而白色也在128以上时工作的很好。但是如果图像过或欠曝光,图像可能全白或全黑。基本思路为首先找到图像中所有像素的最大值和最小值,然后取中点作为阈值。一个更好的选择阈值的方法是不仅查看图像实际的范围,还要看其分布。比如说,你希望图像类似于一副黑色线条画,或者在白纸上的文字效果,那么你就期望大部分像素是背景颜色,而少部分是黑色。一副像素的直方图可能如图所示。
 上图中,可以发现一个背景颜色的大峰值,以及一个黑色墨水的小的峰值。根据周围的光线整个曲线可想向左或者向右偏移,但是在任何情况下,最理想的阈值就是在两个峰值之间的波谷处。这在理论上很好,但在实际中的表现并不理想。
上图中,可以发现一个背景颜色的大峰值,以及一个黑色墨水的小的峰值。根据周围的光线整个曲线可想向左或者向右偏移,但是在任何情况下,最理想的阈值就是在两个峰值之间的波谷处。这在理论上很好,但在实际中的表现并不理想。
上图及其直方图显示整个技术工作的很好。平滑后的直方图显示出2个潜在的峰值,通过拟合直方图曲线或简单的取两个峰值之间的平均值来计算出一个近似理想阈值并不是一件困难的事情。这不是一个典型的图像,因为他有大量的黑色和白色的像素点。算法必须还要对类似图3这样的图像进行阈值处理。这这幅图像的直方图中,较小的黑色峰值已经掩埋在噪音中,因此要可靠地在峰值之间确定哈一个最小值是不太可能的。
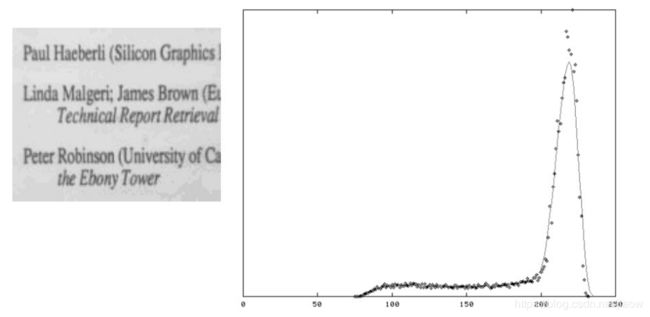 在任何情况下,一个大的(背景)峰值总是存在的并且也容易找到,因此,一个有用的阈值策略可描述如下:
在任何情况下,一个大的(背景)峰值总是存在的并且也容易找到,因此,一个有用的阈值策略可描述如下:
1) 计算直方图。
2) 按照一定的半径对直方图数据进行平滑,并计算平滑后数据的最大值。平滑的目的减少噪音对最大值的影响,如图2和图3所示。
3) 根据上述峰值和最小值(不包括在直方图中为0的项)的距离按照一定的比例选择阈值。
试验表明这个距离的一半能够对很大范围内的图像产生相当好的效果,从非常亮到几乎完全黑的图像。比如,在图3中,峰值在215处,而最小值为75,因此可以使用的阈值为145。图4是四副在不同的光照条件下抓取的图像以及根据上述基于直方图技术阈值处理后的效果。尽管私服图像有这较广的光照范围(可以从直方图中看出),该算法都选择了较为合适的阈值,而阈值处理后的图像基本一样。



这个基于直方图的全局阈值技术对于如上面所举的那些光线条件均匀或那些光线变化不多的部分图像处理的很好。但是对于在正常办公室光照条件下他无法获得满意的结果。因为对整个图像使用一个相同的阈值,图像的部分区域变得太白而其他地区又太黑。因此大部分文字变得不可读,如下图所示
 从光照不均匀的纸张图像中产生较好的二值化图像需要一种自适应的阈值算法。这个技术根据每个像素的背景亮度来改变阈值。下面的讨论都配以图5先显示新算法的效果。这是一个具有挑战性的测试,因为图像边缘有光源,并且其在白色背景上有黑色文字(PaperWorks整个词,以及黑色背景中的白色文字(“XEROX”),还有白色背景中的灰色文字(”The best way。。。”)还有不同的阴影和一个在单词“PaperWorks”下很细小的水平黑色线。
从光照不均匀的纸张图像中产生较好的二值化图像需要一种自适应的阈值算法。这个技术根据每个像素的背景亮度来改变阈值。下面的讨论都配以图5先显示新算法的效果。这是一个具有挑战性的测试,因为图像边缘有光源,并且其在白色背景上有黑色文字(PaperWorks整个词,以及黑色背景中的白色文字(“XEROX”),还有白色背景中的灰色文字(”The best way。。。”)还有不同的阴影和一个在单词“PaperWorks”下很细小的水平黑色线。
2.2 自适应阈值
一个理想的自适应阈值算法应该能够对光照不均匀的图像产生类似上述全局阈值算法对光照均匀图像产生的效果一样好。 为了补偿或多或少的照明,每个像素的亮度需要正规化,之后才能决定某个像素时黑色还是白色。问题是如何决定每个点的背景亮度。一个简单的方式就是在拍摄需要二值图片之前先拍一张空白的页面。这个空白的页面可以当做参考图像。对于每一个要处理的像素,在处理前对应的参考图像像素都将从其中减去。
只要在参考图像和实际要处理的图像拍摄时光照条件没有发生任何变化,这个方法能产生非常好的效果,但是,光照条件会收到人、台灯或其他移动物体的影子的影响。如果房间有窗户,那么光照条件还会随着时间变化而改变。通过一些关于图像实际该是什么样的假设来估计每个像素的背景亮度。Haralick 和 Shapiro提出了以下建议:区域需和灰度调统一;区域内部应该简单,没有过多的小孔;相邻的区域应该有显著的不同值;每个部分的边缘也应该简单,不应凹凸不平,其空间上要准确。
根据Pratt的理论,对于图像二值化,还没有任何量化性能指标提出过。似乎主要评价算法性能的方式就是简单看看结果然后判断其是否很好。对于文字图像,有一个可行的量化办法:不同光照条件下的图片使用不同的二值化算法处理的后的结果被送往OCR系统,然后将OCR识别的结果和原文字比较。虽然该法可能有用,但是他不能用在以下描述的算法中,因为不可能给出一个看起来好的标准。对于一些交互式的应用,比如复制黏贴操作用户必须等到二值的处理。因此另外一个重要的指标就是速度。以下部分提出了不同的自适应阈值算法已经他们产生的结果。
3 基于Wall算法的自适应阈值
首先,将图像分成较小的块,然后分别计算每块的直方图。根据每个直方图的峰值,然后为每个块计算其阈值。然后,每个像素点的阈值根据相邻的块的阈值进行插值获得。
3.1 算法原理
算法基本的细想就是遍历图像,计算一个移动的平均值。如果某个像素明显的低于这个平均值,则设置为黑色,否则设置为白色。仅需一个遍历就够了,用硬件去实现算法也很简答。注意到下面的算法和IBM 1968年用硬件实现的算法的相似性是比较有趣的。
假设Pn为图像中位于点n处的像素。此刻我们假设图像是由所有行按顺序连接起来的一个单行。这导致了在每行开始的时候会产生一些异常,但这个异常要比每行都从零开始要小
 假设fs(n)是点n处最后 s个像素的总和:
假设fs(n)是点n处最后 s个像素的总和:
 最后的图像T(n)是1(黑色)或0(白色)则依赖于其是否比其前s个像素的平均值的百分之t的暗
最后的图像T(n)是1(黑色)或0(白色)则依赖于其是否比其前s个像素的平均值的百分之t的暗
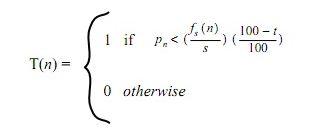 对于s使用图像的1/8宽而t取值15似乎对不同的图像都能产生较好的效果。上图显示了使用该算法从左到右扫描行的结果。
对于s使用图像的1/8宽而t取值15似乎对不同的图像都能产生较好的效果。上图显示了使用该算法从左到右扫描行的结果。

上图是使用相同算法从右到左处理的结果,注意在这个图像中,最左侧的较小的文字是不完整的。在字符PaperWorks中也有更多的孔洞。同样,最右侧的黑色边缘也窄很多。这主要是由于图像的背景光源是从左到右逐渐变黑的。从上面的东西来看,Wellner 自适应滤波阈值实际上就是对像素做指定半径的一维平滑,然后原像素和平滑后的值做比较来决定黑还是白。文章中很大一部分篇幅都是在讨论取样的那些像素的方向问题,是完全在左侧、完全在右侧还是左右对称,抑或是考虑到前一行的效果