Hadoop〖一〗Hadoop3.2.1版本本地安装伪集群实现词频统计案例
Hadoop〖一〗Hadoop3.2.1版本本地安装伪集群实现词频统计案例
- 一. 安装Hadoop在虚拟机上
- 1.1 准备一台虚拟机
- 1.2 安装JDK
- 1.3 安装Hadoop
- 二. 接下来进行配置伪分布式(上面的Hadoop只是单机模式)
- 2.1 创建文件夹
- 2.2 修改hadoop配置文件
- 2.3 启动Hadoop
- 2.4 访问UI界面
- 三. 实现WordCount案例(词频统计)
- 3.1 词频统计实现
- 3.2 将测试文本拖进hdfs
- 3.3 执行案例jar包
- 制作不易,转载请标注~
一. 安装Hadoop在虚拟机上
1.1 准备一台虚拟机
我这边准备的是Centos7版本的虚拟机
为了以防万一,可以在不确定虚拟机是否崩盘的情况下,克隆一下虚拟机,右键虚拟机打开管理点克隆~
1.2 安装JDK
我在桌面准备了这次安装的所有压缩文件,因为Hadoop依靠于JDK环境,所以我们首先安装JDK1.8
首先用我们的xftp工具把JDK拷贝到 /usr/java/ 路径下,然后使用
tar -zxvf jdk-8u231-linux-i586.tar.gz
将压缩包解压到当前目录,注意虚拟机自带OpenJDK的需要提前卸载以免安装错误
解压完成后进入JDK目录(蓝色的)

这里我们打印出来当前目录: /usr/java/jdk1.8.0_231
cd jdk1.8.0_231/
[root@kaikai jdk1.8.0_231]# pwd
/usr/java/jdk1.8.0_231
提前进入root权限 su 命令输入密码,编辑环境变量,
vim /etc/profile
先按i进入insert模式,我们在如下 unset -f pathmunge 添加如下三条 第一行为JDK的地址
unset i
unset -f pathmunge
#jdk
export JAVA_HOME=/usr/java/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
修改完后,按ESC退出编辑模式再按shift+: 输入wq保存并退出
紧接着我们在命令行输入来使我们的配置文件生效,每配置一次环境变量就得刷新一次使生效
source /etc/profile
接着我们来验证一下jdk安装成功没,输入
[root@kaikai jdk1.8.0_231]# java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) Server VM (build 25.231-b11, mixed mode)
出现以上即可证明JDK安装成功~
1.3 安装Hadoop
首先把Hadoop安装包copy到虚拟机目录下
[root@kaikai jdk1.8.0_231] cd /opt/hadoop/
解压Hadoop安装包
[root@kaikai hadoop] tar -zxvf hadoop-3.2.1.tar.gz
进入Hadoop查看当目录
[root@kaikai hadoop-3.2.1] pwd
/opt/hadoop/hadoop-3.2.1
配置环境变量
[root@kaikai hadoop-3.2.1]# vim /etc/profile
在 HADOOP_HOME 后面填上你自己安装的hadoop目录,刚用pwd查看过的
#hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.1
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效
[root@kaikai hadoop-3.2.1] source /etc/profile
判断是否安装成功
[root@kaikai hadoop-3.2.1] hadoop version
Hadoop 3.2.1
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842
Compiled by rohithsharmaks on 2019-09-10T15:56Z
Compiled with protoc 2.5.0
From source with checksum 776eaf9eee9c0ffc370bcbc1888737
This command was run using /opt/hadoop/hadoop-3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar
出现版本信息,说明成功
二. 接下来进行配置伪分布式(上面的Hadoop只是单机模式)
2.1 创建文件夹
创建以下几个文件夹
/opt/hadoop/tmp
/opt/hadoop/hdfs/name
/opt/hadoop/hdfs/data
2.2 修改hadoop配置文件
找到如下目录,进入
[root@kaikai hadoop] pwd
/opt/hadoop/hadoop-3.2.1/etc/hadoop
输入 vim core-site.xml 修改配置
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop/tmpvalue>
property>
configuration>
输入 vim hdfs-site.xml 修改配置
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.name.dirname>
<value>/opt/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.data.dirname>
<value>/opt/hadoop/hdfs/datavalue>
property>
configuration>
etc/hadoop目录下查看是否有配置文件mapred-site.xml。目录下默认情况下没有该文件,可通过执行如下命令:cp mapred-site.xml.template mapred-site.xml修改一个文件的命名,然后执行编辑文件命令:gedit mapred-site.xml并修改该文件内容:
HADOOP_MAPRED_HOME= 后面配置的是Hadoop目录,就是一开始Hadoop的环境变量
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop-3.2.1value>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop-3.2.1value>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop-3.2.1value>
property>
configuration>
在etc/hadoop目录下执行vim yarn-site.xml修改配置
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
2.3 启动Hadoop
第一次启动时需要格式化namenode
[root@kaikai hadoop] hdfs namenode -format
进入如下目录,修改启动配置
[root@kaikai sbin] pwd
/opt/hadoop/hadoop-3.2.1/sbin
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
一键启动命令
[root@kaikai sbin] ./start-all.sh
如下图正自启动
[root@kaikai sbin] ./start-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [localhost]
Last login: Sat Feb 29 14:42:15 CST 2020 on pts/1
Starting datanodes
Last login: Sat Feb 29 19:48:02 CST 2020 on pts/1
Starting secondary namenodes [kaikai.com]
Last login: Sat Feb 29 19:48:05 CST 2020 on pts/1
2020-02-29 19:48:25,974 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
Last login: Sat Feb 29 19:48:16 CST 2020 on pts/1
Starting nodemanagers
Last login: Sat Feb 29 19:48:26 CST 2020 on pts/1
验证启动成功
命令行输入jps出现下面就是启动成功了!
[root@kaikai sbin] jps
8898 NodeManager
8724 ResourceManager
9285 Jps
8122 DataNode
7947 NameNode
8364 SecondaryNameNode
2.4 访问UI界面
命令行输入如下,找到虚拟机的IP地址,若是服务器要用公网IP
[root@kaikai sbin] ifconfig
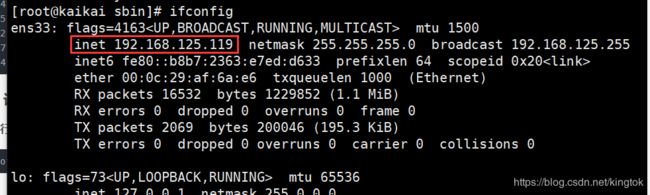
浏览器中输入访问
http://192.168.125.119:9870
UI界面出现!
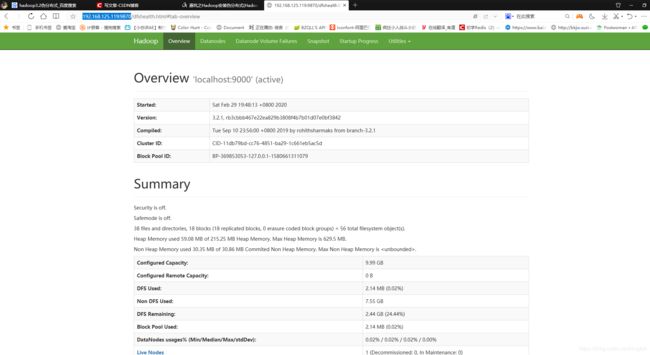
这样我们大功告成,伪分布式已经安装完成!
三. 实现WordCount案例(词频统计)
3.1 词频统计实现
-
Hadoop 的计算需要通过MapReduced来实现,可以通过编写Java程序,将功能打成jar包来执行。所以如果有良好的Java基础,编写MR程序自然会容易很多。
-
我们这里用自带的示例程序来运行wordcount,从而来演示Hadoop的功能。
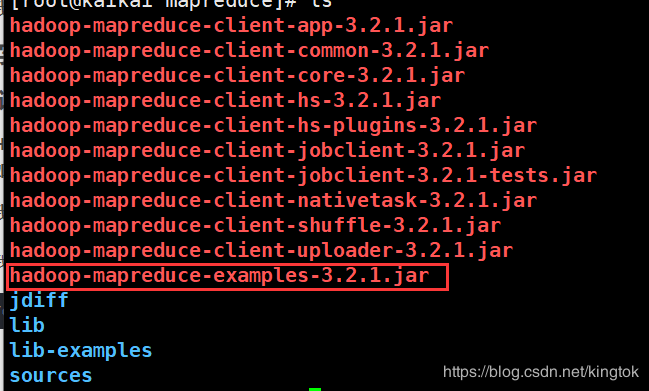
打开我们MapReduced目录
cd /opt/hadoop/hadoop-3.2.1/share/hadoop/mapreduce/
下面就是我们wordcount的jar包我们需要运行起来
3.2 将测试文本拖进hdfs
找到下面目录的LICENSE.txt

执行下面语句
hdfs dfs -put LICENSE.txt /data/wordcount/LICENSE.txt
检查一下测试文件在里面没
hdfs dfs -ls -R /

3.3 执行案例jar包
命令行输入(在mapreduce目录下)
[root@kaikai mapreduce] hadoop jar hadoop-mapreduce-examples-3.2.1.jar wordcount /data/wordcount/LICENSE.txt output
最终我们在out目录下看到执行过的输出文件
![]()
打开输出文件
[root@kaikai mapreduce] hdfs dfs -cat /user/root/output/part-r-00000
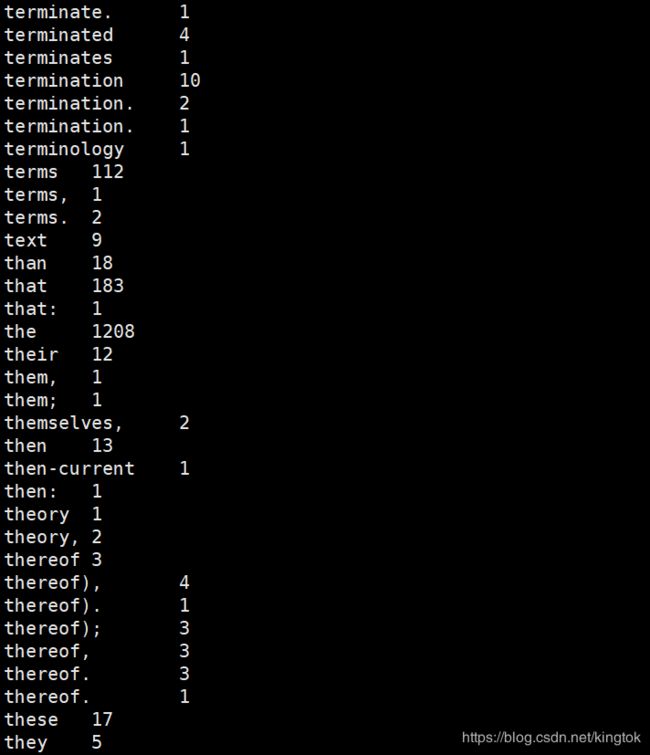
案例实现完成~