java调优方法,jvm监控工具
graph LR
A-->B
性能概述
程序性能表现形式
- 执行速度:程序响应速度,总耗时是否足够短
- 内存分配:内存分配是否合理,是否过多消耗内存或者存在泄漏
- 启动时间:程序运行到可以正常处理业务需要的时间
- 负载承受能力
性能测评指标
- 执行时间
- CPU时间:函数或者线程占用CPU时间
- 内存分配:程序在运行时占用内存空间
- 磁盘吞吐量:描述I/O使用情况
- 网络吞吐量:描述网络使用情况
- 响应时间:系统对用户行为或者时间做出回应的时间。
系统瓶颈相关计算机资源
- 磁盘I/O
- 网络操作
- CPU
- 异常:对java来说,异常捕获和处理是非常消耗资源的
- 锁竞争:高并发程序中,锁的竞争对性能影响尤其重要,增加线程上下文切换开销。而且这部分开销与应用需求五官,占用CPU资源
- 内存:一般只要应用设计合理,内存读写速度不会太低,出发程序进行高频率内存交换扫描。
Amdahl定律
- Amdahl定义了串行系统并行化后加速比的计算公式和理论上线
- 加速比定义:加速比= 优化前系统耗时/优化后系统耗时
- Amdahl定律给出了加速比与系统并行°和处理器数量的关系,加速比Speedup,串行化程序比重F,CPU数量为N:
- Speedup<=1/(f+(1-F)/N)
- 总结:根据Amdahl定律,使用多核CPU对系统进行优化,优化效果取决于CPU数量以及系统中串行程序比重,CPU数越多,串行比重越低优化效果更好。
性能调优层次
- 设计调优
- 代码调优
- JVM调优
- 数据库调优
- 操作系统优化
设计优化
善用设计模式
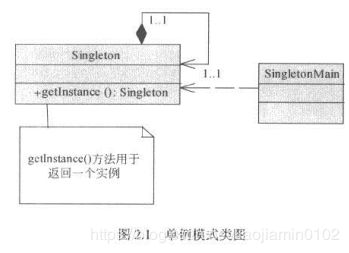
单例模式经典问题
- 用于长沙一个多小的具体实例,可以确保系统中一个类只产生一个实例,能带来两大好处:
- 对的频繁使用的对象,可以省略创建对象花费的时间,这对于那些重量级的对象而言,是非常可观的一笔系统开销
- 由于new操作次数减少,因而对系统内存的使用频率也会降低,这将减轻GC压力,缩短GC停顿时间。
public class Singleton{
private Singleton(){
System.out.println("Singleton is create");//创建单例可能比较慢,应为是大对象。
}
private static Singleton instance = new Singleton();
public Singleton getInstance(){
return instance;
}
}
- 单例模式必须有一个私有构造,只有构造方法是私有的才能保证他不会被实例化;其次instance和getInstance必须是static修饰的,这样JVM加载单例类时候对象就会被穿件,才能全局使用。
- 以上这种单例实现方式简单,可靠,但是缺点是我们无法做到延迟加载,因为static修饰比如JVM加载类时候被建立,如果此时,这个单例类特别大,或者在系统中海油其他角色,你们任何使用这个类的地方都会初始化这个单例变量,而不管是否被用到,比如单例类作为String工厂,如下:
public class SingletonStr {
private SingletonStr(){
System.out.println("SingletonStr is create");
}
private static SingletonStr instance = new SingletonStr();
public static SingletonStr getInstance(){
return instance;
}
public static void createString(){
System.out.println("createString in singleton");
}
public static void main(String[] args) {
SingletonStr.createString();
}
}
/***
*输出如下:
* SingletonStr is create
* createString in singleton
***/
- 如上可见,没有使用instance,但是还是会新建,因此我们需要的是延迟加载机制,使用时候才创建,如下实现
public class LazySingleton {
private LazySingleton(){
System.out.println("LazySingleton is create");
}
private static LazySingleton instance = null;
public static LazySingleton getInstance(){
if(instance == null){
synchronized (LazySingleton.class){
if(instance == null){
instance = new LazySingleton();
}
}
}
return instance;
}
}
- 如上,instance初始值null,在jvm加载时候没有额外的负担,需要调用getinstance()方法之后才会判断是否已经存在,不存在则加上锁来初始化。此处不加锁在并发情况会有线程安全问题。
- 以上案例用synchronized必然存在性能问题,存在锁竞争问题,如下改造
public class StaticSingleton {
private StaticSingleton(){
System.out.println("StaticSingleton is create");
}
private static class SingletionHolder{
private static StaticSingleton instance = new StaticSingleton();
}
public static StaticSingleton getInstance(){
return SingletionHolder.instance;
}
}
- 使用内部类来维护单例的实例,当StaticSingleton被加载时,内部类并不会被初始化,只有getInstance被调用才会加载SingletionHolder,从而初始化instance,因为实例的建立是类加载完成,所以天生就对多线程友好。
代理模式
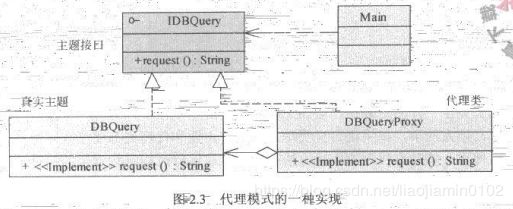
- 代理模式的一个作用可作为延迟加载,例如当前并没有使用某个组件,则不需要初始化他,使用一个代理对象替代它的原有位置,只要在真正需要使用的时候,才对他进行加载。在实践周上分散系统压力,尤其在启动的过程。
动态代理介绍
- 生成动态代理的方法有多个:JDK自带的动态代理,CGLIB,Javassist或者ASM,jdk的无需引入第三方jar,功能比较弱,CGLIB和Javassist都是高级字节码生成库,总体性能不jdk的优秀,而且功能强大,ASM是低级字节码生成工具,使用ASM已近乎使用java bytecode编程,对开发人员要求高。
- 首先jdk的简单如下
public class JdkDBQueryHandler implements InvocationHandler {
IDBQuery real = null;
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if(real == null){
real = new DBQueryImpl();
}
return real;
}
}
- 首先使用JDK动态代理生成代理对象,JDK动态代理需要实现一个处理方法调用的Handler,用于实现代理方法的内部逻辑,接着需要用这个Handler生成代理对象。如下:
public static IDBQuery createJdkproxy(){
IDBQuery jdkProxy = (IDBQuery) Proxy.newProxyInstance(ClassLoader.getSystemClassLoader(),
new Class[]{IDBQuery.class},new JdkDBQueryHandler());
return jdkProxy;
}
}
- 以上代码生成了一个实现IDBQuery接口的代理类,代理类的内部逻辑有JdkDBQueryHandler决定,生成代理类后,由newProxyInstance方法放回该代理类的一个实例。
CGLIB和Javassist
public class CglibDBQueryInsterceptor implements MethodInterceptor {
IDBQuery real = null;
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
if(real == null){
real = new DBQueryImpl();
}
return real;
}
}
public static IDBQuery createCGlibProxy(){
Enhancer enhancer = new Enhancer();
enhancer.setCallback(new CglibDBQueryInsterceptor());
enhancer.setInterfaces(new Class[]{enhancer.createClass()});
IDBQuery cglibProxy = (IDBQuery) enhancer.create();
return cglibProxy;
}
- CGLIB的动态代理使用和JDK的类似,如上代码。
- Javassist的动态java代码创建代理过程和上面的有一些不同,javassist内部可以通过动态java代码,生成字节码,这种方式创建的动态代理可以非常灵活,甚至可以在运行时候生成业务逻辑。很奇特的一种用法,如下代码:
public static IDBQuery createJavassistBytecodeDynamicProxy()
throws NotFoundException, CannotCompileException, IllegalAccessException, InstantiationException {
ClassPool mpool = new ClassPool(true);
CtClass mCtc = mpool.makeClass(IDBQuery.class.getName() + "JavassistBytecodeProxy");
mCtc.addInterface(mpool.get(IDBQuery.class.getName()));
mCtc.addConstructor(CtNewConstructor.defaultConstructor(mCtc));
mCtc.addField(CtField.make("public "+IDBQuery.class.getName()+ " real;", mCtc));
String dbqueryname = DBQueryImpl.class.getName();
mCtc.addMethod(CtNewMethod.make("public String request(){if(real == null) real = new "
+ dbqueryname + "(); return real.request();}",mCtc));
Class pc = mCtc.toClass();
IDBQuery bytecodeProxy = (IDBQuery) pc.newInstance();
return bytecodeProxy;
}
- 以上代码使用CtField.make()方法和CtNewMethod.make方法在运行时候生成了代理类的字段和方法,这些逻辑由于javassist的CtClass对象处理,将java代码转换为对应的字节码,并生成动态代理的实例。
享元模式
- 享元模式核心思想在于:如果一个系统存在多个相同对象,你们只需要共享一份拷贝,不必每次都实例化对象。享元模式对性能的提升有如下两点:
- 节省重复创建对象的开销。因为被享元模式维护的对象只被创建一次,当被对象创建消耗比较大实话,可以节省大量时间。
- 由于创建对象的数量减少,所以对系统内存的需求也减少,这将GC的压力也降低,进而使得系统拥有一个健康的内存结构和更快的响应速度。
- 享元模式主要角色由享元工厂,抽象享元,具体享元类,主函数几部分组成,各功能如下:
- 享元工厂:用来创建具体享元类,维护相同享元对象,他保证相同的享元对象可以被系统共享(内部使用类似单例模式的算法,当请求对象已经存在时候,直接返回对象,不存在时候,在创建对象)
- 抽象享元:定义需共享的对象的业务接口,享元类被创建出来总是为了实现某些特定的业务逻辑。而抽象享元就是定义这些逻辑的语义行为。
- 具体享元类:实现抽象享元类的接口,完成某一具体逻辑。
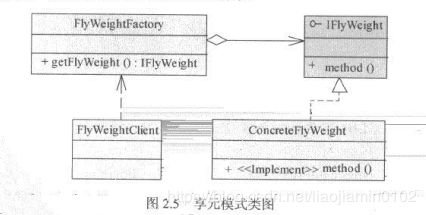
- 如上类图所示,通过FlyWeightFactory工厂方法来生成ConcreteFlyWeight这一类大对象,其中ConcreteFlyWeight可以代表多个不同的类,但是都有相同的属性,通过继承IFlyWeight接口,这样都可以通过工厂方法来生成,如下案例:
public interface IReportManager {
public String createReport();
}
public class EmployeeReportManager implements IReportManager {
private String tenantId;
public EmployeeReportManager(String tenantId){
this.tenantId = tenantId;
}
@Override
public String createReport() {
return "is employee";
}
}
public class FinancialReportManager implements IReportManager {
private String tenantId;
public FinancialReportManager(String tenantId){
this.tenantId = tenantId;
}
@Override
public String createReport() {
return "is financial";
}
}
//工厂方法
public class ReportManagerFactory {
Map<String, IReportManager> financialMap = new HashMap<>();
Map<String, IReportManager> empolyeeMap = new HashMap<>();
public IReportManager getFinancialReportManager(String tenantId){
if(!financialMap.containsKey(tenantId)){
IReportManager financialReportManager = new FinancialReportManager(tenantId);
financialMap.put(tenantId, financialReportManager);
return financialReportManager;
}
return financialMap.get(tenantId);
}
public IReportManager getEmployeeReportReportManager(String tenantId){
if(!empolyeeMap.containsKey(tenantId)){
IReportManager employeeReportManager= new EmployeeReportManager(tenantId);
empolyeeMap.put(tenantId, employeeReportManager);
return employeeReportManager;
}
return empolyeeMap.get(tenantId);
}
}
//使用
public class MainTest {
public static void main(String[] args) {
ReportManagerFactory reportManagerFactory = new ReportManagerFactory();
IReportManager reportManager = reportManagerFactory.getFinancialReportManager("A");
System.out.println(reportManager.createReport());
}
}
装饰者模式
-
装饰者模式基本设计准则 合成/聚合复用原则的思想,代码复用,应该尽可能的使用委托,而不是使用继承。因为继承是一种紧密耦合,任何父类的改动都会影响子类,不利于系统维护,而委托则是松耦合,只要接口不变,委托类的改动并不会影响其上层对象。
-
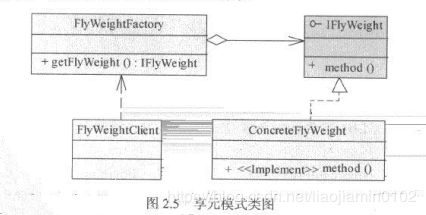
装饰者模式通过委托机制,复用系统中各个组件,在运行时,可以将这些功能进行叠加,从而构造一个超级对象,使其拥有各个组件的功能。基本结构如下
-
装饰者Decorator在被装饰者ConcreteComponent的基础上(拥有相同接口Component)添加自己的新功能,被装饰者拥有的是系统核心组件,完成特定功能模板。如下案例:
//接口
public interface IPacketCreator {
public String handleContent();
}
//被装饰者
public class ConcreteComponent implements IPacketCreator {
@Override
public String handleContent() {
return "Content of packet";
}
}
//装饰器
public abstract class PacketDecorator implements IPacketCreator {
IPacketCreator component;
public PacketDecorator(IPacketCreator c){
component = c;
}
}
//具体的装饰器一
public class PacketHTMLHeaderCreator extends PacketDecorator {
public PacketHTMLHeaderCreator(IPacketCreator c) {
super(c);
}
@Override
public String handleContent() {
StringBuilder sb = new StringBuilder();
sb.append("");
sb.append("");
sb.append(component.handleContent());
sb.append("");
sb.append("");
return sb.toString();
}
}
//具体的装饰器二
public class PacketHTTPHeaderCreator extends PacketDecorator {
public PacketHTTPHeaderCreator(IPacketCreator c) {
super(c);
}
@Override
public String handleContent() {
StringBuilder sb = new StringBuilder();
sb.append("Cache-Control:no-cache\n");
sb.append(component.handleContent());
return sb.toString();
}
}
-
JDK的实现中也有不少组件用的装饰器模式,其中典型的就是IO模型,OutputStream,InputStream类族的实现,如下OutputStream为核心的装饰者模型的实现:
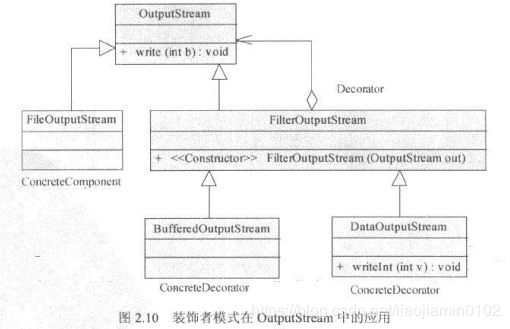
-
其中FileOutputStream为系统核心类,实现了文件写入数据,使用DataOutputStream可以在FileOutputStream的基础上增加多种数据类型的写操作支持。BufferOutputStream装饰器,可以多FileOutputStream增加缓冲功能,优化IO性能,以BufferedOutputStream为代表的功能组件,是将性能模块和功能模块分离的一种典型实现
public static void testIOStream() throws IOException {
DataOutputStream dataOutputStream =
new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("C:\\Users\\Administrator\\Desktop\\重要信息.txt")));
// 没有缓冲功能的流对象
// DataOutputStream dataOutputStream =
// new DataOutputStream(
// new FileOutputStream("C:\\Users\\Administrator\\Desktop\\重要信息.txt"));
long begin = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
dataOutputStream.write(i);
}
System.out.println("speed: " + (System.currentTimeMillis() - begin));
}
- 以上FileOutputStream第一种加入了BufferedOutputStream第二种没有,第一种IO性能明显更高。
观察者模式
- 观察者模式在软件系统中非常常用,当一个对象的行为依赖另外一个对象的状态的时候,观察者模式就相当有用。在JDK内部就已经为开发人员准备了一套观察者模式的实现,在java.util包中,包括java.util.Observable类和java.util.Observer,如图:
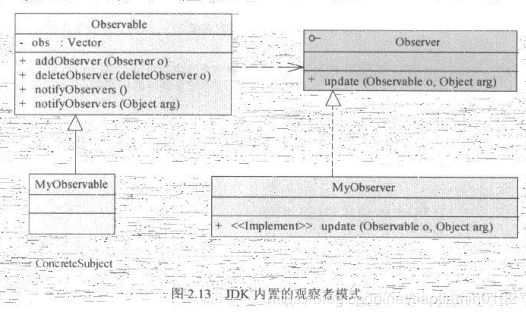
- 如下按以上UML图实现观察者模式:
//观察者的接口
public interface Observer {
void update(Subject s);
}
//Subject顶级接口
public interface Subject {
void registerObserver(Observer o);
void removeObserver(Observer o);
void notivfyAllObserver();
}
//某视频网站,实现了Subject接口
public class VideoSite implements Subject {
private ArrayList<Observer> userList;
private ArrayList<String> videos;
public VideoSite() {
userList = new ArrayList<>();
videos = new ArrayList<>();
}
@Override
public void registerObserver(Observer o) {
userList.add(o);
}
@Override
public void removeObserver(Observer o) {
userList.remove(o);
}
@Override
public void notivfyAllObserver() {
for (Observer observer : userList) {
observer.update(this);
}
}
public void addVideos(String video) {
this.videos.add(video);
//通知所有用户
notivfyAllObserver();
}
public ArrayList<String> getVideos() {
return videos;
}
@Override
public String toString() {
return videos.toString();
}
}
//实现观察者,即看视频的美剧迷们
public class VideoFans implements Observer {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public VideoFans(String name){
this.name = name;
}
@Override
public void update(Subject s) {
System.out.println(this.name + ", new Video are available!");
System.out.println(s);
}
}
//test
public class MainTest {
public static void main(String[] args) {
VideoSite vs = new VideoSite();
vs.registerObserver(new VideoFans("one"));
vs.registerObserver(new VideoFans("two"));
vs.registerObserver(new VideoFans("three"));
vs.addVideos("生活大爆炸大更新!!!");
}
}
常用优化组件和方法
缓冲(Buffer)
- 缓冲可以协调上层组件和下层组件的性能差异,当上层组件性能优于下层组件时,可以有效减少上层组件的处理速度,从而提升系统整体性能。缓冲最好的案例便是I/O中的读取速度。还是上面那个例子
public static void testIOStream() throws IOException {
DataOutputStream dataOutputStream =
new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("C:\\Users\\Administrator\\Desktop\\重要信息.txt")));
// 没有缓冲功能的流对象
// DataOutputStream dataOutputStream =
// new DataOutputStream(
// new FileOutputStream("C:\\Users\\Administrator\\Desktop\\重要信息.txt"));
long begin = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
dataOutputStream.write(i);
}
System.out.println("speed: " + (System.currentTimeMillis() - begin));
}
- 使用BufferedOutputStream,他构造方法有两个和和BufferedWriter类似
public BufferedOutputStream(OutputStream out);
public BufferedOutputStream(OutputStream out, int size)
- 其中第二个构造可以指定缓冲区大小,默认情况和BuffereWriter一样,缓冲区大小8K,缓冲大小不宜过小,这样起不到缓冲作用,也不宜过大,浪费内存增加GC负担,我们使用默认缓冲大小测试,一个2毫秒,一个34毫秒,性能差一个数量级。
- 除了性能优化,缓冲区还可以作为上下层组件的通讯工具,从而做到上下层组件解耦,优化设计结构。
缓存(cache)
- 缓存也是一个提升系统性能而开辟的内存空间。缓存主要作用暂存数据处理结果,并提供下次使用,减少数据库访问,减少计算从而减少CPU的占用,从而提升系统性能。
- 目前有很多java缓存框架EHCache, OSCAche,JBossCache,EhCache缓存出自Hibernate,还有缓存数据库Redis,memcache,这两个都是常用的缓存中间件。
对象复用(池)
- 对象池是目前常见的系统优化技术,核心思想是一个类被频繁请求使用,不必每次生成一个实例,可以将这个类的一些实例保存在一个池中,需要使用直接获取,类似享元模式。
- 对象池的使用最多的就是线程池和数据库连接池,线程池中,保存可以被重用的线程对象,当有任务提交到线程池时候,系统不需要新建线程,而从池中获取一个可用线程,执行即可。任务结束后也不用关闭线程,而将他返回到池中,下次继续用,因为线程创建销毁过程是费时的工作,因为线程池改善了系统性能。
- 数据库连接池也是一个特殊对象池,他维护数据库连接的集合。当系统需要访问数据库直接从池中获取,无需重新创建并连接,使用完后也不会关闭,重新回到连接池中,在这个过程节省了创建和销毁的重量级操作,因此大大节约了事件,减少资源消耗。目前应用多的数据库连接池C3P0 和Hibernate一起发布。
- 处理线程池,数据库连接池,对普通Java对象,必须要时候也可以池化,对于大对象来说,池化不仅节省获取对象实例的成本,还可以减轻GC频繁回收这些对象产生的系统压力。
- 实际开发中对象池,Apache中有现成的Jakarta Commons Pool对象池。
public interface ObjectPool<T> extends Closeable {
......
T borrowObject() throws Exception, NoSuchElementException, IllegalStateException;
......
void returnObject(T var1) throws Exception;
}
- 其中borrowObject方法从对象池获取一个对象,returnObject方法在使用完后将对象返回对象池,另外一个重要接口是PooledObjectFactory
public interface PooledObjectFactory<T> {
//定义如何创建新对象实例
PooledObject<T> makeObject() throws Exception;
//对象从对象池中被销毁时,会执行这个方法。
void destroyObject(PooledObject<T> p) throws Exception;
//判断对象是否可用
boolean validateObject(PooledObject<T> p);
//在对象从对象池取出前,会激活这对象
void activateObject(PooledObject<T> p) throws Exception;
//在对象返回对象池时候被调用
void passivateObject(PooledObject<T> p) throws Exception;
}
- Jakarta Commons Pool中内置了三个对象池,StackObjectPool,GenericObjectPool,SoftReferenceObjectPool
- StackObjectPool利用java.util.Stack来保存对象,可以为StackObjectPool指定一个初始化大小,并且空间不够时候,StackObjectPool自增长,当无法从对象池得到可用对象,他会自动创建新对象。
- GenericObjectPool:一个通用的对象池,可以设定容量,也可以指定无对象可用时候的对象池行为(等待或者创新对象),还可以设置是否进行对象有效性检查。
- SoftReferenceObjectPool使用ArrayList保存对象,但是并不是直接保存对象的强引用,二手保存对象的软引用,对对象数量没有限制,没有可用对象时候新建对象,内存紧张时候JVM可以自动回收具有软引用的对象。
并行替代串行
- 多CPU是的,并行充分发挥CPU的潜能
负载均衡
- 大型应用系统一般用多台服务器来同时提供服务,以此将请求尽可能均匀的分配到各个计算技上。
- 案例TOmcat集群,通过Apache服务器实现,用Apache服务器作为负载均衡分配器,将请求转向各个tomcat类似nginx,tomcat集群,有两种基本Session共享模式,
- 黏性Session所有Session信息平均到各个tomcat上,实现负载均衡,好处在于不同各个节点同步信息,每个节点固定几个用户信息节省内存,缺点是宕机后用户信息丢失,无法做到高可用。
- 复制Session每台Tomcat存储全量用户Session数据,当一个节点上Session修改,广播到所有节点同时做更新操作,,这样即使挂掉也能提供服务,坏处是更新操作占用网络资源,影响效率
- 解决方案分布式缓存框架Terracotta,在公线内存时候,并不会进行全复制,仅仅传输变化的部分,网络复制也比较低,因此效率远高于普通session复制
时间换空间
- 通常用于嵌入式设备,或者内存,硬盘空间不足的情况,通过牺牲CPU的方式,获得原本需要更多内存或者硬盘才能完成的工作。如下哪里,教皇a,b两个变量值,一般是引入第三变量方法一,而方法二通过计算能避免第三变量引入节省资源消耗CPU
//方法一
temp = a;
a = b;
b = temp;
//方法二
a = a+b;
b = a-b;
a = a-b;
空间换时间
- 使用更多的内存或者磁盘空间换取CPU资源或者网络资源等,通过增加系统内存消耗,来加快程序的运行速度。比如使用缓存技术来缓存一部分计算后的结果信息,避免重复计算。
java程序优化
字符串优化处理
- java中String类的基本实现主要包含三部分:char数组,偏移量,String的长度。char数组表示String的内容,他是String对象锁标识字符串的超集。String的真实内容还需要由偏移量和长度在这个Char数组中进行定位和截取。如下图:
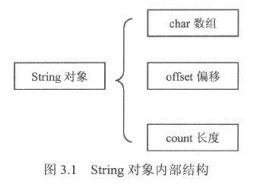
- java设计对String对象进行了一部分优化,主要体现在以下三个方面,同时也是String对象的3个特点:
- 不变性
- 针对常亮池的优化
- 类的final定义
不变性
- String对象一旦生成,则不能在对他进行修改,String的这个特性可以泛化成不变模式,机一个对象的状态在对象被创建后不发送变化,主要作用在一个对象被多线程共享,并发范问时候,可以沈略同步和锁等待的时间,因为不会被修改,因此不存在线程安全问题。
针对常亮池优化
- 当两个String对象拥有相同的值时候,他们只引用常量池中同一个拷贝。这样可以大幅节省内存空间,如下案例
public static void main(String[] args) {
String str1 = "abc";
String str2 = "abc";
String str3 = new String("abc");
System.out.println(str1 == str2);
System.out.println(str1 == str3);
System.out.println(str1 == str3.intern());
}
- 以上案例,str1 和str2 引用了相同的地址,但是str3重新开辟了一块内存,但是str3 最终在常量池的位置和str1 是一样的,虽然str3 重新分配了堆空间,但是在常量池中的实体和str1 相同,intern方法返回Stromg对象在常量池中的引用。如下图说明:
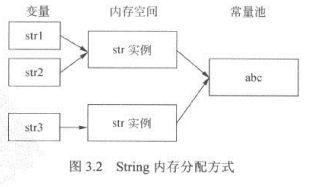
类的final定义
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
.....
}
- 如上java中对String类的定义,final类型的定义是一个重要特点,说明String在系统中不存在子类,这是对系统安全性的保护,同时,对JDK1.5 版本之前环境中,使用final定义有助于虚拟机寻找机会,内敛所有final方法,从而提升系统效率。
subString方法内存泄露风险
- 内存泄露(leak of memory):指为一个对象分配内存后,在对象已经不再使用时候未及时释放,导致一直占用内存单元,是实际可用内存减少,就好像内存漏了。
- 内存溢出(out of memory):通俗说就是内存不够,比如在一个无线循环中不断建大对象,很快就会引发内存溢出。
substring方法内存泄漏JDK1.6
public String substring(int beginIndex, int endIndex)
- 如上是String类的一个方法,这个方法在JDK6 和JDK7 是实现不同的,一下我们分别讨论:
- subString作用是返回一个子字符串,从父字符串的beginindex开始,结束语endindex+1,如下
String x= "abcdef";
x= str.substring(1,3);
System.out.println(x);
//输出:ab
- 看JDK6 中的substring的实现如下:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value); //使用的是和父字符串同一个char数组value
}
//构造方法
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
//案例
String str = "abcdefghijklmnopqrst";
String sub = str.substring(1, 3);
str = null;
- 如上简单案例两个字符串变量str,sub。sub字符串是有父字符串str截取得到,如果在jdk6 中运行,因为数组在内存空间分配是在堆上,那么sub和str的内部char数组value是公用的同一个,也就是上述a~t这个char数组,str和sub唯一的差别就是在数组中的beginindex和字符串长度count不同,我们吧str引用为空实际上是想释放str的空间,这时候GC并不会回收,因为sub引用的还是那个char因此不会被回收,虽然sub只截取一部分,但是str特别大时候那就会造成资源浪费。
subString方法JDK1.7
- JDK1.7中改进了subString的实现,他实际上是为截取的字符创在堆中重新申请内存用来保存字符串的字符,如下源码:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
//构造函数
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
public static char[] copyOfRange(char[] original, int from, int to) {
int newLength = to - from;
if (newLength < 0)
throw new IllegalArgumentException(from + " > " + to);
char[] copy = new char[newLength];
System.arraycopy(original, from, copy, 0,
Math.min(original.length - from, newLength));
return copy;
}
- 可以发现copyOfRange中为子字符串创建了一个新的char数组去存储子字符串中的字符。这样子字符串和父字符串也就没有什么必然联系,父字符串引用失效时候,GC就会适当时候回收。
- substring1.6 这种方式采用了空间换时间的手段,他是一个包内的私有构造,不被外界调用,因此时间使用不用太担心带来的麻烦,但是仍然需要关注这些问题。
字符串分割和查找
public String[] split(String regex)
- 最原始的字符串分割split函数原型,提供强大字符串分割功能,参数可传正则
- 普通字符串分割可以选择性能更好的函数StringTokenizer
StringTokenizer类分割
public static void main(String[] args) {
String orgStr = null;
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < 10000; i++) {
stringBuilder.append(i);
stringBuilder.append(";");
}
orgStr = stringBuilder.toString();
Long timeBegin = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
orgStr.split(";");
}
Long timeEnd = System.currentTimeMillis();
System.out.println("speed :" + (timeEnd - timeBegin));
Long timeBegin1 = System.currentTimeMillis();
StringTokenizer st = new StringTokenizer(orgStr, ";");
for (int i = 0; i < 10000; i++) {
while (st.hasMoreTokens()){
st.nextToken();
}
st = new StringTokenizer(orgStr, ";");
}
Long timeEnd2 = System.currentTimeMillis();
System.out.println("speed2 :" + (timeEnd2 - timeBegin1));
}
//输出
speed :3162
speed2 :2688
- 第二段即使StringTokenizer对象不断被销毁创建性能还是优于split
更优化的分割方式
- 可以用两个组合方法比如IndexOf和subString,之前提到,subString采用空间换时间,速度比较快,我们有如下实现:
Long timeBegin2 = System.currentTimeMillis();
String tmp = orgStr;
while (true){
String splitStr = null;
int j = tmp.indexOf(";");
if(j<0) break;
splitStr = tmp.substring(0,j);
tmp = tmp.substring(j+1);
}
Long timeEnd2 = System.currentTimeMillis();
System.out.println("speed2 :" + (timeEnd2 - timeBegin2));
//输出
speed2 :94
- 由此可以看出,indexOf和subString方法性能远比split和StringTokenizer高,很适合高频函数的使用。
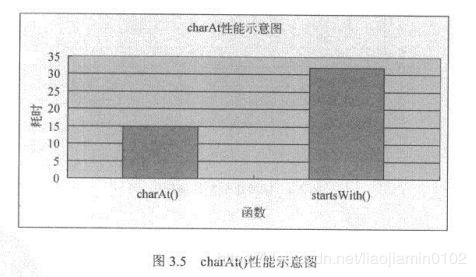
高效的charAt方法
public char charAt(int index);
- 和indexOf相反,返回位置在index的字符效率和indexOf一样高,同样是java内置函数的startWith和endWith效率远低于charAt方法。如下性能示意图
StringBuffer和StringBuilder
- 由于String对象是不可变的,如果我们在做字符串修改操作时候总会生成新对象,这样性能差,所以有这两个用来修改字符串工具方法
String常量的累加操作
//方法一
String result = "String" +"and" + "String" + "append";
//方法二
StringBuilder result = new StringBuilder();
result.append("String");
result.append("and");
result.append("String");
result.append("append");
- 如上代码一会生成String, and, append,Stringand, StringandString,StringandStringappend六个字符串理论上说效率低下
- 两段代码分表指向5万次,方法一小盒0ms,方法二消耗15ms,与预期相反,反编译第一段代码:
String s = "StringandStringappend";
- 以上结果看出对于常量字符串累加,java的编译时候就做了优化,对编译时候就能确定取值的字符串操作,在编译时候就进行了计算,所以运行时候并没有生成大量String实例,而使用StringBuffer的代码反编译后的结果和源代码王完全一致。可见运行StringBuffer对象和append方法都被如实调用,所以第一段代码效率才会这么快。
- 如果我们写如下代码避开编译优化
String str1 = "String";
String str2 = "and";
String str3 = "String";
String str4 = "append";
String result = str1 + str2 + str3 + str4;
- 执行5万次平均耗时16ms,性能与StringBuilder几乎一样,我们反编译一次得到如下
String str1 = "String";
String str2 = "and";
String str3 = "String";
String str4 = "append";
String result = new StringBuilder(String.valueOf(str1)).append(str2).append(str3).append(str4);
- 可以看到对应字符串的累加,java也做了相应的优化操作。实际上就是用的Stringbuilder对象来实现的字符串累加,所以性能几乎一致。
构建超大的String对象
- 有如下字符串修改方式对比:
//耗时1062ms
for (int i = 0; i < 10000; i++) {
str = str + i;
}
//耗时360ms
for (int i = 0; i < 10000; i++) {
str = str.concat(String.valueOf(i));
}
//耗时0ms
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10000; i++) {
sb.append(i);
}
- 如上代码以及耗时与我们预期的方法一和三本相同的不一样,因为一与三本质都是使用的StringBuilder为什么差距这么大,我们反编译一得到的如下:
for (int i = 0; i < 10000; i++) {
new StringBuilder(String.valueOf(str)).append(i).append(str3).toString();
}
- 如上可看出,每次循环都重新生成StringBuilder实例,所以降低系统性能。这个也表明了String的加法操作虽然被优化,但是编译器并不是万能的,因此少用为妙,也可以得出StringBuilder > concat > +,+=这个字符串编辑效率的方法排名。
StringBuilder和StringBuffer的选择
- 两个方法都实现了AbstractStringBuilder抽象类,有相同对外接口,最大不同是StringBuffer几乎所有方法都做了同步处理Synchronized,StringBuilder没有做同步
- StringBuilder效率优于StringBUffer,但是多线程下StringBuilder无法保证线程安全。
容量参数
- StringBuilder和StringBuffer初始化都有一个容量参数,如下构造,不知道的情况默认16字节,
public StringBuilder(int capacity)
public StringBuffer(int capacity)
- 追加append方法时候,如果超过容量,则进行扩容,在AbstractStringBuilder类中,如下:
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
- 如上扩容方法策略将原有容量大小翻倍<< 1 移位运算,以新容量申请内存空间,建新char数组,然后复制原有数据到新数组。因此大对象的处理会涉及到N多次的内存复制扩容,如果能评估StringBuilder的大小,能避免中间的扩容复制操作,提高性能。
核心数据结构
List接口
-
三种list的实现:ArrayList, Vector,LinkedList,类图如下:

-
都来自AbstraList实现,AbstractList直接实现了List接口,
-
ArrayList和Vector都使用数组,但是Vector增加了对多线程的支持,是线程安全的,Vector绝大部分方法做了线程同步,理论上说ArrayList性能要好于Vector
-
LinkedList使用双向链表实现,每个元素都包含三个部分,元素内容,前驱表项,后驱表项

增加元素分析
- ArrayList源码如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
- add方法的性能取决于ensureExplicitCapacity 方法中的grow扩容,当ArrayList足够大,add效率是很高的无需扩容时候只需要执行以下两个步骤
modCount++;
elementData[size++] = e;
- 需要扩容时候,会将数组扩大到原来的1.5倍,之后在进行数据的复制,复制的方法利用Arrays.copyOf方法。
- LinkedList源码如下
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last; //最后一个节点复制给l
final Node<E> newNode = new Node<>(l, e, null); //新节点前驱是l
last = newNode;
if (l == null)
first = newNode;//l为空标识之前没有节点,那么新节点就是首个节点
else
l.next = newNode;//l不为空,将l(此时L是之前最后一个节点) 后驱指针指向新节点。
size++;
modCount++;
}
- 如下last节点就是我们理解的指针,用来指向最后一个节点元素每次添加节点都添加到最后,LinkedList使用链表结构,不需要维护容量大小,无需扩容,这个是对比ArrayList的优势,但是每次需要新建Entry并且赋值,会有一定性能影响
- 如下实验,设置jvm参数(-Xmx512M -Xms512M)
Object obj = new Object();
for(int i=0; i<500000;i++){
last.add(obj);
}
- 使用jvm参数是为了屏蔽GC对程序性能的干扰,ArrayList耗时16ms,LinkedList耗时31ms,不间断的生产新对象还是有一定资源损耗,若不用jvm参数,区别更大,因为LinkedList会产生很多对象,占用堆内存触发GC,因此LinkedList对对内存和GC要求高。
增加元素到任意位置
- List接口中有一个插入元素的方法
public void add(int index, E element)
- ArrayList和LinkedList在这个方法上存在非常大性能差异,ArrayList数组实现,需要对数据重新排列,如下:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);//数据移动拷贝
elementData[index] = element;
size++;
}
- 可见,每次插入都需要将index后面的数据整体后移,非常损耗性能,并且index越靠前需要拷贝的数据越多,性能损耗越大。
- LinkedList优势比较大,如下源码:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
- 如上代码,LinkedList插入随意位置与插入队尾区别在于需要遍历链表到指定index位置,无需数据复制而是对元素中前驱指针与后驱指针作修改。
删除任意位置元素
- 删除与添加的逻辑基本一致,两个的性能取决于需要操作的数据是在List的前,中,后,ArrayList需要复制数据,在头部时候效率低,LinkedList需要遍历List在中间的时候效率更低,我们做如下测试得出以下结论:
while(list.size() > 0){
list.remove(0);
}
while(list.size() > 0){
list.remove(list.size() >> 1);
}
while(list.size() > 0){
list.remove(list.size() - 1);
}
| List类型/删除位置 | 头部 | 中部 | 尾部 |
|---|---|---|---|
| ArrayList | 6203 | 3125 | 16 |
| LinkedList | 15 | 8781 | 16 |
遍历列表
- 遍历有三种方式,forEach,Iterator,i.for,三种方式在100万数据量下性能如下表:
| List类型 | ForEach操作 | 迭代器 | for循环 |
|---|---|---|---|
| ArrayList | 63ms | 47ms | 31ms |
| LinkedList | 63ms | 47ms | ~~无穷大 |
- 最简单的ForEach性能不如迭代器,而用for循环的情况下ArrayList性能最优,LinkedList的在随机访问每次都需要一次列表的遍历操作,性能会非常差,无法等到运行结束。
- ForEach 与 迭代器比较,反编译代码得到一些结果:
//ForEach
for (Iterator iterator = list.iterator(); iterator.hasNext()){
String s = (String) iterator.next();
String s1 = s;
}
//for
for (Iterator iterator = list.iterator(); iterator.hasNext()){
String s = (String) iterator.next();
}
- 由上看出,仅仅是多了一次赋值操作,导致ForEach循环的性能更差一点。
Map接口
- Map接口最主要的实现类是HashTable,HashMap,LinkedHashMap,TreeMap,在HashTable的子类中还有Preperties类的实现。
- HashMap,HashTable 异同
- Hashtable大部分方法做了同步处理,HashMap没有,因此HashMap不是线程安全
- HashTable不允许key或者value使用null,HashMap是允许的
- HashMap,HashTable 的hash算法和hash值到内存索引的映射算法不同。
HashMap实现原理
- 将key做hash算法,将hash值映射到内存地址,直接取得key对应的数据。HashMap的高性能保证以下几点:
- hash算法必须高效的
- hash值到内存地址(数组索引)的算法是快速的
- 更具内存地址(数组索引)可以直接取得对应值
- 首先第一点:hash算法的高效性,我们用get方法中hash算法代码来解释
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//hash值获取
static final int hash(Object key) {
int h;
//调用的Object中的hashCode方法,接着对取得的Hash做移位运算,与原hash值异或(^)运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 先获取key的hash值,调用的Object中的HashCode方法,这个方法是native的实现,比一般方法都要快,其他的操作都是基于位运算,也是高效的
- 注意:native方法快的原因是,他直接调用操作系统本地连接库的API
- 第二点取得key的hash后续通过hash获取内存地址,还是通过get方法中代码:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {//按位与操作
......
}
return null;
}
- 以上get方法中table是数组,将hash值和数组长度(n+1)按位与直接得到数组索引,等效于取余,但是位操作性能更高,这样得到数组下标取对应值,
- 第三点更具数组下标取值直接内存访问速度也快,因此获取内存地址也是快速的
Hash冲突
- HashMap解决Hash冲突,首先结构上如下图结构,HashMap内部维护一个数组,在1.7 中是Entry,在1.8 中是Node,只是节点元素不同,结构一样,此处按1.8 来讲,如下Node源码

static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
....
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
....
}
}
- 如上,每个Node中包含四部分,hash值,key,value,next指针,当put操作时候如如上图,新的Node n1会被放在对应的索引下标内,并且替换原有值,同时为保证旧值不丢失,将Node n1 的next 指向旧的Node n2 ,这样就实现了一个数组索引空间内存放多个值。HashMap实际上就是一个链表的数组。
- 并且在java1.8 时候还做了优化,在链表长度达到7 的时候将链表转红黑数,提高读写效率。
容量参数
- 容量参数对性能影响类似ArrayList和Vector,技术数组结构不可避免有空间不足,进行扩展,扩容的过程也就会对性能消耗。HashMap 有如下构造
public HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity)
public HashMap()
- 其中initialCapacity指定HashMap初始容量,loadFactor指定负载因子,
- 初始容量大小大于等于initialCapacity并且是2的指数次幂的最小整数作为内置数组的大小。
- 负载因此叫填充比,介于0~1 之间浮点数,决定了HashMap在扩容前其内部数组的填充度。默认情况初始大小16,负载因子0,75
- 负载因子 = 元素个数/内部数组总大小
- 负载因子越大,说明HashMap中的hash冲突就越多,次数另外一个参数threshold 变量,他被定义为氮气数组总容量和负载因子的乘积
- threshold = 内部数组总容量*负载因子 = 确定元素总量一个数字
- 依照上面的公式threshold 相当于HashMap的一个元素的阀值,更具各个参数来决定,超过这个阀值会开始扩容,扩容代码如下:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//超过最大值不扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//没超过,扩容为原来2倍,并且扩容后小于最大值,大于默认值16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//计算新的resize上线
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//此处开始数据迁移,吧每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//原索引+ oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//将原索引放到bucket里面
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//原索引+ oldCap放到bucket里面
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
LinkedHashMap,有序的HashMap
- 因为HashMap是无序的,因此有一个替代品LinkedHashMap,继承自HashMap,因此也具备HashMap的高性能,
- 在HashMap基础上增加一个链表存放元素顺序,相当于一个维护了元素顺序的HashMap,通过如下构造:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
- 当accessOrder 为true时候,按元素最后范问时间排序, 当accessOrder 为false时,按插入顺序排序,默认false。
- LinkedHashMap 中的元素用的Entry,继承了HashMap的Node,并且在此基础扩展了before,after指针,如下:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
- 每个Entry 2通过after指向后继元素Entry n,而Entry n的before指向前驱元素Entry 2,构成一个循环链表。如下图所示:

TreeMap----另一种Map实现
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
- TreeMap功能上比HashMap更强大,他实现了SortedMap的功能,如上构造函数注入了一个Comparator,使用一个实现了Comparable接口的key,对于TreeMap而言,排序是必须进行的一个过程
- TreeMap的性能相比HashMap更差
- TreeMap的排序不同于LinkedHashMap,LinkedHashMap 是更具元素增加或者访问的先后顺序来排序,TreeMap是根据key实现的算法进行排序。
Set接口
- Set接口并没有在Collection接口上增加额外的操作,Set结婚中的元素是不能重复的,而且Set是比较特殊的一个,他的三个实现HashSet,LinkedHashSet,TreeSet的实现分表是对HashMap,LinkedHashMap,TreeMap的一个封装以HashSet为例,内部维护一个HashMap,所有有关Set’的实现都委托HashMap对象完成,如下构造:
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
优化集合访问代码
减少循环中相同的操作,比如循环中的size等
减少方法调用
RandomAccess接口
使用NIO提升性能
- 虽然java提供了基于流的IO实现InputStreamOutputStream,这种实现以字节为单位处理数据,并且非常容易建立各种过滤器,但是还是基于传统的IO凡是,是系统性能的瓶颈。
- NIO是New IO的简称,有以下特点:
- 为所有原始类型提供Buffer缓存支持
- 使用java.nio.charset.Charset作为字符集编码解码解决方案
- 增加通道Channel对象,作为新的原始IO抽象
- 支持锁和内存映射文件的文件访问接口
- 提供了基于Selector的异步网络IO
- 与IO不同的是NIO基于Block块的,以块为基本单位处理数据,NIO中最重要两个组件Buffer,Channel,缓冲是一块连续的内存块,是NIO读写数据的中转地,通过标识缓存数据的源头或者目的地,用于向缓冲读写。如下图:
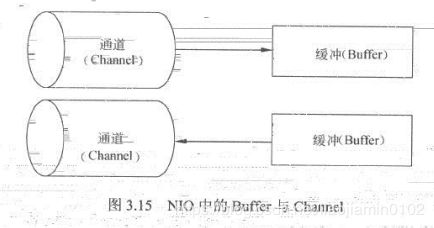
NIO的Buffer和Channel
- Buffer是一个抽象类,他为JDK中每种原生数据类型创建了一个Buffer:IntBuffer,ByteBuffer,Charbuffer,DubboBuffer,FloatBuffer,LongBuffer,ShortBuffer,除了ByteBuffer其他每种都有完全一样的操作,唯一去吧是对应的数据类型
- NIO中和Buffer配合使用的是Channel,相当于一个双向通道,读与写如下一个读文件案例:
public static void nioCopyFileTest(String source, String destination) throws IOException {
FileInputStream fis = new FileInputStream(source);
FileOutputStream fos = new FileOutputStream(destination);
FileChannel readChannel = fis.getChannel();
FileChannel writeChannel = fos.getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);//申请堆内存
while (true){
byteBuffer.clear();
int len = readChannel.read(byteBuffer);
if(len == -1){
break;
}
byteBuffer.flip();
writeChannel.write(byteBuffer);
}
readChannel.close();
writeChannel.close();
}
Buffer的基本原理
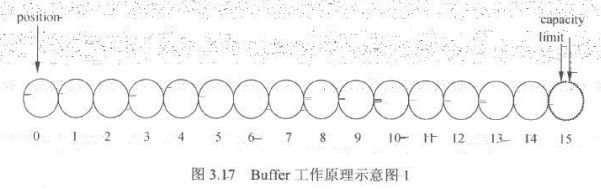
- Buffer三个重要参数,位置(position),容量(capacity),上限(limit)
- 位置:position,写的时候,当前缓冲区的位置,从position的下一个位置开始写入,读取的时候当前缓冲区读取的位置从此位置后读取数据
- 容量:capacit,读写的时候缓冲区总容量上线。
- 上限:limit,写入时候缓冲区实际上线,一般小于等于总容量,通常和总容量相等,读取的时候代表可读取的总容量,和上次写入的数据量相等。
- 一下案例解析三个参数:
public static void main(String[] args) {
//分配15个字节
ByteBuffer byteBuffer = ByteBuffer.allocate(15);
System.out.println("limit: "+ byteBuffer.limit() + "capacity: "
+ byteBuffer.capacity() + "position: "+ byteBuffer.position());
for (int i = 0; i < 10; i++) {
byteBuffer.put((byte) i);
}
System.out.println("limit: "+ byteBuffer.limit() + "capacity: "
+ byteBuffer.capacity() + "position: "+ byteBuffer.position());
byteBuffer.flip();//重置position
System.out.println("limit: "+ byteBuffer.limit() + "capacity: "
+ byteBuffer.capacity() + "position: "+ byteBuffer.position());
for (int i = 0; i < 5; i++) {
System.out.println(byteBuffer.get());
}
System.out.println("limit: "+ byteBuffer.limit() + "capacity: "
+ byteBuffer.capacity() + "position: "+ byteBuffer.position());
byteBuffer.flip();
System.out.println("limit: "+ byteBuffer.limit() + "capacity: "
+ byteBuffer.capacity() + "position: "+ byteBuffer.position());
}
/**
limit: 15capacity: 15position: 0
limit: 15capacity: 15position: 10
limit: 10capacity: 15position: 0
0
1
2
3
4
limit: 10capacity: 15position: 5
limit: 5capacity: 15position: 0
*/
-
第一步申请15个字节大小缓冲区,初始阶段如下图
-
Buffer中放入10个byte,因此position前移10,其他两个不变
-
flip操作,重置position,将buffer重写模式转为读,并且limit设置到当前position位置作为读取的界限位置:
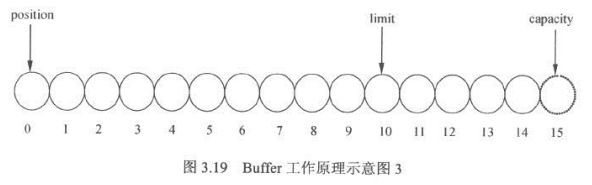
- 五次读操作,与写操作一样重置position到当前位置,指定已经读取的位置
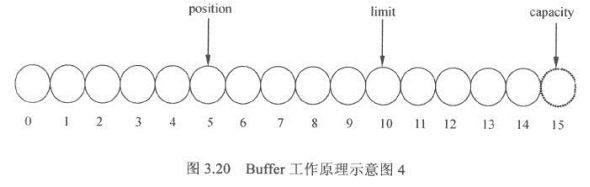
- 再次flip归零position,同事limit设置到position位置:
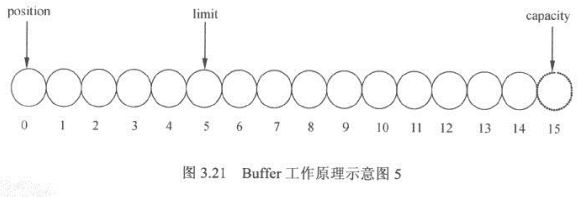
Buffer相关操作
- Buffer的创建
ByteBuffer byteBuffer = ByteBuffer.allocate(15);
byte array[] = new byte[1024];
ByteBuffer b = ByteBuffer.wrap(array, 0, array.length-1);
- 重置和清空缓冲区
b.rewind();
b.clear();
b.flip();
- 以上三个函数类似功能,都重置buyffer,这里说明的重置只是重置了标志位,并不是清空buffer,数据还是存储在buffer中。分别看一下源码:
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
- rewind 将position设置零,同时清除标志位mark,作用在于为提取Buffer的有效数据做准备
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
- clear将position设置零,将limit设置为cipicity大小,清除remark,因为limit清空了,所有无法指定buffer内那些数据是有效的,这个方法用于重新写buffer做准备
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
- flip将limit设置到position位置,position清零,清除标志位mark,一般在读写转换时候使用。
标志缓冲区
- 标志mark缓冲区类似书签一样的功能,数据处理过程中随时纪律当前位置,然后任意时刻,回到这个位置,加快或者简化数据处理流程。如下源码
public final Buffer mark() {
mark = position;
return this;
}
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
- mark用来记录当前位置,reset用于恢复到mark所在的位置,如下使用方法:
public static void main(String[] args) {
ByteBuffer byteBuffer = ByteBuffer.allocate(15);
for (int i = 0; i < 10; i++) {
byteBuffer.put((byte) i);
}
byteBuffer.flip();
for (int i = 0; i < byteBuffer.limit(); i++) {
System.out.print(byteBuffer.get());
if(i == 4){
byteBuffer.mark();
System.out.println("mark at: " + i );
}
}
byteBuffer.reset();
System.out.println(" reset to mark");
while (byteBuffer.hasRemaining()){
System.out.print(byteBuffer.get());
}
}
/**
01234mark at: 4
56789reset to mark
56789
*/
复制缓冲区
- 以原有缓冲区为基础,生成一个完全一样的新缓冲区
public abstract ByteBuffer duplicate();
- 特点在于新生成的缓冲区与原缓冲区共享同一内存数据,所以数据修改互相可见,但两者又独立维护个字position,limit,remark,使得操作更加灵活。
缓冲区分片
- 使用slice方法将现有缓冲区中创建新的子缓冲区,字缓冲区和父缓冲区共享数据,这个方法有助于将系统模块化,当需要处理一个Buffer的一个片段时候,可以使用slice方法取得一个子缓冲区,然后单独处理。如下案例
ByteBuffer byteBuffer = ByteBuffer.allocate(15);
for (int i = 0; i < 10; i++) {
byteBuffer.put((byte) i);
}
byteBuffer.position(2);
byteBuffer.limit(6);
ByteBuffer byteBuffer2 = byteBuffer.slice();
- 上例子中分出的子缓冲区如图所示:

只读缓冲区
- asReadOnlyBuffer()方法获取与当前缓冲区一直的,并且内存共享的只读缓冲区,保证数据安全性。
- 当只读缓冲区被尝试修改的时候回抛出异常
java.nio.ReadOnlyBufferException
文件映射到内存
- NIO提供将文件映射到内存的方法进行IO操作,比常规IO流快很多,由FileChannel.map()实现,如下案例
public static void main(String[] args) throws IOException {
RandomAccessFile raf = new RandomAccessFile("D:\\sentinel.txt", "rw");
FileChannel fc = raf.getChannel();
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, raf.length());
while (mbb.hasRemaining()){
System.out.println((char) mbb.get());
}
raf.close();
}
- 将文件0~最后一位byte字节映射到对应MapperByteBuffer内存中,之后直接操作内存中数据
处理结构化数据
- NIO提供的结构化数据处理:散射(Scattering),聚集(Gathering)。散射指将数据读入一组Buffer中。聚集指将数据写入一组Buffer中。接口实现如下
- ScatteringByteChannel用法通道一次填充每个缓冲区,甜蜜一个后,开始填充下一个,类似缓冲区数组的一个大缓冲区:
public long read(ByteBuffer[] dsts, int offset, int length) throws IOException;
public long read(ByteBuffer[] dsts) throws IOException;
- 如果需要创建指定格式的文件,只需要先构造好大小合适的Buffer对象,使用聚集写的方式,可以很快的创建出文件
- GatheringByteChannel用法:
public long write(ByteBuffer[] srcs, int offset, int length)
throws IOException;
public long write(ByteBuffer[] srcs) throws IOException;
- JDK提供的各种通道中DatagramChannel,FileChannel和SocketChannel都实现了这两个接口,以下FileChannel为例,解释如何使用散射和聚集读写结构化文件。
public static void main(String[] args) throws IOException {
ByteBuffer bookBuf = ByteBuffer.wrap("java性能优化技巧".getBytes("utf-8"));
ByteBuffer autBuf = ByteBuffer.wrap("葛一鸣".getBytes("utf-8"));
Integer booklen = bookBuf.limit();
Integer autlen = autBuf.limit();
ByteBuffer[] bufs = new ByteBuffer[]{bookBuf, autBuf};
File file = new File("D:\\test.txt");
if(!file.exists()){
file.createNewFile();
}
FileOutputStream fos = new FileOutputStream(file);
FileChannel fc = fos.getChannel();
fc.write(bufs);
fos.close();
}
- 以上代码建两个ByteBuffer,分别存储书名,和作者信息,构造ByteBuffer数组使用文件通道将数组写入文件
public static void main(String[] args) throws IOException {
ByteBuffer bookBuf = ByteBuffer.wrap("java性能优化技巧".getBytes("utf-8"));
ByteBuffer autBuf = ByteBuffer.wrap("葛一鸣".getBytes("utf-8"));
Integer booklen = bookBuf.limit();
Integer autlen = autBuf.limit();
ByteBuffer b1 = ByteBuffer.allocate(booklen);
ByteBuffer b2 = ByteBuffer.allocate(autlen);
ByteBuffer[] bufs = new ByteBuffer[]{b1, b2};
File file = new File("D:\\test.txt");
FileInputStream fis = new FileInputStream(file);
FileChannel fc = fis.getChannel();
fc.read(bufs);
String bookName = new String(bufs[0].array(), "utf-8");
String authname = new String(bufs[1].array(), "utf-8");
System.out.println(bookName + " : " + authname);
}
- 同样散射读的方式根据长度精确构造buffer,通过文件通道散射读将文件信息装载到对应的Buffer中,之后直接从buffer中读取信息。
- 以上两个案例可看到,通过和通道的配合使用,可以简化Buffer对于结构化数据处理的难度。
MappedByteBuffer性能评估
- 分别用传统IO,基于Buffer的IO,基于内存映射的MappedByteBuffer的I三种IO模型下的效率,我们用如下案例
//文件写入
public static void main(String[] args) throws IOException {
long bgTime = System.currentTimeMillis();
Integer numOfInt = 4000000;
FileChannel fileChannel = new RandomAccessFile("D:\\test.txt", "rw").getChannel();
IntBuffer ib = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, numOfInt*4).asIntBuffer();
for (Integer i = 0; i < numOfInt; i++) {
ib.put(i);
}
if(fileChannel != null){
fileChannel.close();
}
System.out.println("speed: "+ (System.currentTimeMillis() - bgTime));
}
//文件读取
public static void main(String[] args) throws IOException {
long bgTime = System.currentTimeMillis();
Integer numOfInt = 4000000;
FileChannel fileChannel = new RandomAccessFile("D:\\test.txt", "rw").getChannel();
IntBuffer ib = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, numOfInt*4).asIntBuffer();
for (Integer i = 0; i < numOfInt; i++) {
ib.get();
}
if(fileChannel != null){
fileChannel.close();
}
System.out.println("speed: "+ (System.currentTimeMillis() - bgTime));
}
- 此处指给出内存映射的方式文件读写,基于上几章节案例对比,本次耗时写入109ms,读文件耗时61ms,大大优于基于Buffer的IO,此外基于Buffer的IO大大优于基于传统的IO。总结如下表格
| 使用Stream | ByteBuffer | MaooedByteBuffer | |
|---|---|---|---|
| 写耗时 | 1641 | 954 | 109 |
| 独耗时 | 1297 | 296 | 79 |
直接内存访问
- NIO中直接访问内存的类,DireBuffer,他是一个借口,对应ByteBuffer的实现类是DirectByteBuffer,继承自ByteBuffer,如下:
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer
- 与ByteBuffer不同的是,普通ByteBuffer仍然在JVM的堆内存上分配空间,最大内存收到最大堆内存限制,DirectBuffer直接分配在物理内存中,不占用堆内存空间(重要)
- 普通ByteBuffer访问,系统会使用一个“内核缓冲区”进行间接操作,而DirectBuffer所处的位置,就相当于这个“内核缓冲区”。使用DirectBuffer是一种更接近系统底层的方法。比普通ByteBuffer更快。
- DirectBuffer相对于ByteBuffer访问速度更快,但是创建和销毁DirectBuffer的花费远比ByteBuffer高,如下测试,配置JVM参数VM options:-XX:+PrintGCDetails -XX:MaxDirectMemorySize=10M -Xmx10M
public static void main(String[] args) throws IOException {
long begin = System.currentTimeMillis();
for (int i = 0; i < 20000; i++) {
//测试一
ByteBuffer b = ByteBuffer.allocate(1000);
//测试二
ByteBuffer b = ByteBuffer.allocateDirect(1000);
}
System.out.println(System.currentTimeMillis() - begin);
}
//测试一中普通ByteBuffer结果
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->758K(9728K), 0.0009691 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2536K->488K(2560K)] 2806K->774K(9728K), 0.0013332 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2536K->488K(2560K)] 2822K->850K(9728K), 0.0009512 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2536K->504K(2560K)] 2898K->914K(9728K), 0.0006810 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2552K->504K(2560K)] 2962K->930K(9728K), 0.0010715 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2552K->504K(1536K)] 2978K->930K(8704K), 0.0005587 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1528K->224K(2048K)] 1954K->1184K(9216K), 0.0005771 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1248K->160K(2048K)] 2208K->1160K(9216K), 0.0003433 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1184K->32K(2048K)] 2184K->1080K(9216K), 0.0002990 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1056K->32K(2048K)] 2104K->1080K(9216K), 0.0003482 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1056K->32K(2048K)] 2104K->1080K(9216K), 0.0002876 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1056K->32K(2048K)] 2104K->1080K(9216K), 0.0004324 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1056K->0K(2048K)] 2104K->1048K(9216K), 0.0003900 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1024K->32K(2048K)] 2072K->1080K(9216K), 0.0003066 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1056K->32K(2048K)] 2104K->1080K(9216K), 0.0002950 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1056K->32K(2048K)] 2104K->1080K(9216K), 0.0002153 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
18
Heap
PSYoungGen total 2048K, used 849K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 1024K, 79% used [0x00000000ffd00000,0x00000000ffdcc7d0,0x00000000ffe00000)
from space 1024K, 3% used [0x00000000fff00000,0x00000000fff08000,0x0000000100000000)
to space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
ParOldGen total 7168K, used 1048K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 14% used [0x00000000ff600000,0x00000000ff7062e0,0x00000000ffd00000)
Metaspace used 3456K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 376K, capacity 388K, committed 512K, reserved 1048576K
//测试二 DirectBuffer 结果
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->762K(9728K), 0.0011810 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (System.gc()) [PSYoungGen: 2064K->496K(2560K)] 2338K->2288K(9728K), 0.0022161 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 496K->0K(2560K)] [ParOldGen: 1792K->1482K(7168K)] 2288K->1482K(9728K), [Metaspace: 3464K->3464K(1056768K)], 0.0179332 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
47
Heap
PSYoungGen total 2560K, used 1276K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 62% used [0x00000000ffd00000,0x00000000ffe3f278,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 7168K, used 1482K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 20% used [0x00000000ff600000,0x00000000ff772a10,0x00000000ffd00000)
Metaspace used 3475K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 377K, capacity 388K, committed 512K, reserved 1048576K
- 如上配置JVM信息 XX:MaxDirectMemorySize 指定DirectBuffer的大小最大10,-Xmx指定最大堆内存10M,在同等内存下,DirectBuffer的相对耗时 47 ,Buffer耗时18,可得到频繁创建销毁DirectBuffer的代价更大
- 测试二中DirectBuffer的GC信息简单,因为GC只记录堆空间内存回收,由于DirectBuffer占用内存并不在堆内存中,因此对操作更少,日志自然少,但是DirectBuffer对象本身还是在堆空间分配,只是他指向的内存地址不在对内存空间范围内而已。
引用类型
- 引用类型分四种: 强引用,软引用,弱引用,虚引用
强引用
- java引用类似指针,通过引用可以对堆中的对象进行操作,如下
StringBuffer str = new StringBuffer("hello world");
StringBuffer str1 = str;
- 以上代码,局部变量str分配在栈上,对象StringBuilder实例分配在堆内存,str会执行StringBuffer所在堆内存空间,通过str操作改实例,str1 也同时指向StringBuffer实例内存,也就是有两个引用,str与str1,
- 如上两个引用都是强引用,有如下特点
- 强引用可以直接访问目标对象
- 强引用所指向的对象在任何时候都不会被系统回收。JVM宁愿抛出OOM异常也不会回收强引用指向的对象
- 强引用可能导致内存泄露
软引用
- 软引用是通过java.lang.ref.SoftReference使用软引用,一个持有软引用的对象,不会被jvm回收,jvm会判断当堆内存使用临近阀值时候。才会去回收软引用的对象。只有内存足够,理论上存活相当长的时间。
- 基于软引用特点,我们可以利用软引用来实现对内存敏感的Cache
弱引用
- 弱引用比软引用更弱,在系统GC时,只要发现弱引用,不管系统堆空间是否足够,都会讲对象回收。但是GC的线程通常优先级不高,因此,并不一定能很快发现持有弱引用的对象。一旦弱引用对象被GC回收,便会加入到一个注册引用队列中。
- 软引用,弱引用都非常适合来保存那些可有可无的缓存数据,如果这么做,当系统内存不足时候,这些缓存数据会被回收,不会导致内存溢出。而当内存资源充足时候,这些缓存数据又可以存在相当长的时间,从而起到加速系统的作用。
虚引用
- 虚引用是引用中最弱一个,和没有引用几乎一样,随时可能被GC回收。当通过虚引用的get()方法去的强引用对象时候总是失败的,并且,虚引用必须和引用队列一起使用.
- 虚引用的作用在于跟踪垃圾回收过程。清理被销毁对象的相关资源。通常,对象不被使用时候,重载该类的finalize方法可以回收对象的资源。但是,如果finalize方法使用不慎可能导致回收失效对象复活的情况,如下案例:
public class CanReliveObj {
public static CanReliveObj obj;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("CanreliveObj finalize called");
obj = this;
}
@Override
public String toString(){
return "i am CanReliveObj";
}
public static void main(String[] args) throws InterruptedException {
obj = new CanReliveObj();
obj = null;
System.gc();
Thread.sleep(1000);
if(obj == null){
System.out.println("obj is null");
}else {
System.out.println("obj is alieve");
}
System.out.println("second gc");
// obj = null;
System.gc();
Thread.sleep(1000);
if(obj == null){
System.out.println("obj is null");
}else {
System.out.println("obj is alieve");
}
}
}
//输出
CanreliveObj finalize called
obj is alieve
second gc
obj is alieve
- 如上案例输出显示obj对象两次gc后还是存活状态,我们在第二次gc前加上obj=null得到结果才能回收obj对象,通过obj=null去除强引用,由此可看出在复杂应用系统中一旦finalize方法实现有问题,容易造成内存泄露。而虚引用则不会有这种情况,因为他实际上是已经完成了对象的回收工作的。
WeakHashMapl类及其实现
- WeakHashMap类在java.util包内,他实现了Map接口,是HashMap的一种实现,他时使用弱引用作为内部数据的存储方案,如下定义源码:
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {
.....
}
- 用处:如果系统中需要一个很大的Map表,Map中的表项作为缓存用,这种场景下,使用WeakHashMap是比较合适,因为WeakHashMap会在系统内存范围,保存所有表项,而内存一旦不够,GC清楚未被引用的表项避免内存泄露。
- 如下测试HashMap与WeakHashMap区别,我们设置-Xxm 5M来限制堆内存信息
//案例一
public static void main(String[] args) {
Map<Integer, Byte[]> map = new WeakHashMap<>();
for (int i = 0; i < 10000; i++) {
Integer ii = new Integer(i);
map.put(ii, new Byte[i]);
}
}
//GC日志堆栈信息
[GC (Allocation Failure) [PSYoungGen: 1024K->504K(1536K)] 1024K->656K(5632K), 0.0406638 secs] [Times: user=0.00 sys=0.00, real=0.05 secs]
[GC (Allocation Failure) [PSYoungGen: 1524K->504K(1536K)] 1677K->806K(5632K), 0.0012177 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1528K->504K(1536K)] 1830K->1878K(5632K), 0.0010152 secs] [Times: user=0.11 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1526K->504K(1536K)] 2901K->3014K(5632K), 0.0010945 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1528K->504K(1536K)] 4038K->3960K(5632K), 0.0013167 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 504K->0K(1536K)] [ParOldGen: 3456K->3416K(4096K)] 3960K->3416K(5632K), [Metaspace: 3422K->3422K(1056768K)], 0.0076172 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[Full GC (Ergonomics) [PSYoungGen: 1021K->0K(1536K)] [ParOldGen: 3416K->1915K(4096K)] 4438K->1915K(5632K), [Metaspace: 3437K->3437K(1056768K)], 0.0047949 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
.....
Heap
PSYoungGen total 1536K, used 1441K [0x00000000ffe00000, 0x0000000100000000, 0x0000000100000000)
eden space 1024K, 91% used [0x00000000ffe00000,0x00000000ffeeaae8,0x00000000fff00000)
from space 512K, 98% used [0x00000000fff00000,0x00000000fff7dd00,0x00000000fff80000)
to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
ParOldGen total 4096K, used 3114K [0x00000000ffa00000, 0x00000000ffe00000, 0x00000000ffe00000)
object space 4096K, 76% used [0x00000000ffa00000,0x00000000ffd0a9b8,0x00000000ffe00000)
Metaspace used 3458K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 376K, capacity 388K, committed 512K, reserved 1048576K
- 因为限制堆内存来实验,可以看到没固定一段时间后就会触发Full GC,因为内存不够,会将之前申请的所有key都释放,以维持内存需求,避免OOM
//案例二
public static void main(String[] args) {
Map<Integer, Byte[]> map = new HashMap<>();
for (int i = 0; i < 10000; i++) {
Integer ii = new Integer(i);
map.put(ii, new Byte[i]);
}
}
[GC (Allocation Failure) [PSYoungGen: 1024K->504K(1536K)] 1024K->616K(5632K), 0.0009105 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1528K->496K(1536K)] 1640K->862K(5632K), 0.0007723 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 1518K->504K(1536K)] 1885K->1862K(5632K), 0.0011210 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
.......
[Full GC (Allocation Failure) Exception in thread "main" [PSYoungGen: 1023K->1023K(1536K)] [ParOldGen: 4091K->4091K(4096K)] 5115K->5115K(5632K), [Metaspace: 3443K->3443K(1056768K)], 0.0025873 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) java.lang.OutOfMemoryError: Java heap space
[PSYoungGen: 1023K->0K(1536K)] [ParOldGen: 4095K->874K(4096K)] 5119K->874K(5632K), [Metaspace: 3449K->3449K(1056768K)], 0.0039615 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
at com.ljm.resource.nio.WeakHashmapDemo.main(WeakHashmapDemo.java:16)
PSYoungGen total 1536K, used 66K [0x00000000ffe00000, 0x0000000100000000, 0x0000000100000000)
eden space 1024K, 6% used [0x00000000ffe00000,0x00000000ffe10808,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
ParOldGen total 4096K, used 874K [0x00000000ffa00000, 0x00000000ffe00000, 0x00000000ffe00000)
object space 4096K, 21% used [0x00000000ffa00000,0x00000000ffadaa08,0x00000000ffe00000)
Metaspace used 3480K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 379K, capacity 388K, committed 512K, reserved 1048576K
- 案例二中用的HashMap运行语段时间后直接OOM,因为5M堆内存显然不够用,此处就体现出WeakHashMap的优势
- 一下分析JDK中WeakHashMap的源码如下Entry的定义片段:
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
final int hash;
Entry<K,V> next;
/**
* Creates new entry.
*/
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
.....
}
- Entry的模式还是沿用jdk1.6以及之前的HashMap的一个Entry结构,并且Entry继承了WeakReference,在构造函数中构造了Key的弱引用,
- 此外WeakHashMap各项操作,get(),put()等,直接或者间接的调用了expungeStaleEntries 函数,用来清理持有的弱引用的key的表项,如下源码:
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) x;
int i = indexFor(e.hash, table.length);//找到这个表项的位置
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
while (p != null) {//移除以及被回收的表项
Entry<K,V> next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
e.value = null; // Help GC
size--;
break;
}
prev = p;
p = next;
}
}
}
}
- 总结:WeakHashMap使用弱引用,可以自动释放以及被回收的key所在的表项,但如果WeakHashMap的key都在系统内持有强引用,那么WeakHashMap就退化成了普通的HashMap,因为所有的表项都无法被自动清理。
有助于改善性能的技巧
慎用异常
使用局部变量
- 调用方法传递的参数,以及调用中创建的临时变量都保存在栈Stack中,速度较快。其他变量,如静态变量,实例变量等,都在堆Heap中创建,速度较慢
位运算代替乘除法
- 所有运算中,位运算最为高效,如下优化:
//方案一
long a = 100;
for(int i=0; i<100000; i++){
a+=2;
a/=2;
}
//方案二
long a = 100;
for(int i=0; i<100000; i++){
a<<=1;
a>>=1;
}
- 看两段代码执行相同功能,第一段普通运算耗时219ms,第二段位运算耗时31ms
一维数组替代二维数组
提取表达式避免重复计算
布尔运算代替位运算
- 位运算速度高于算数运算,但是条件判断时候, 布尔运算速度高于位运算
- java对布尔运算做了充分优化,比如,a,b,c布尔运算a&&b&&c,更具逻辑与操作,只有一个false立刻返回false,因此a为false,立刻返回false,当b,c运算需要消耗大量系统资源时候,这种处理方式效果最大化
- 同理计算a||b||c,逻辑或时候,一个未true,返回true。
- 位运算:虽然位运算效率也搞,但是位运算只能将所有子表达式全部计算完成后,在给出最终结果。因此从这个角度说使用位运算替代布尔运算可能会有额外消耗。如下案例对比
public static void main(String[] args) {
boolean a = false;
boolean b = true;
int d = 0;
for (int i = 0; i < 1000000; i++) {
if(a&b&"javaperform".contains("java")){ //位运算
d=0;
}
}
}
public static void main(String[] args) {
boolean a = false;
boolean b = true;
int d = 0;
for (int i = 0; i < 1000000; i++) {
if(a&&b&&"javaperform".contains("java")){ //布尔运算
d=0;
}
}
}
//位运算耗时250ms
//布尔运算耗时16ms
使用arrayCopy
- 数组赋值功能,JDK提供的高效API
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
- System.arraycopy()函数时native函数,通常native函数性能要优于普通的函数,仅处于性能考虑,在软件开发时候,应尽可能调用native函数。
使用Buffer进行I/O操作
- 处理NIO外,使用java进行IO操作有两种基础方式
- 使用inputStream与OutputStream
- 使用Writer和Reader
- 两种方式都应该合理配合使用缓冲,能有效提高IO性能。以文件IO为例如下图组件
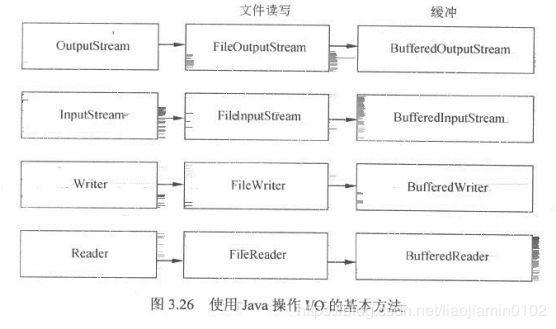
- 如下测试demo
public static void main(String[] args) throws Exception {
// DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("D:\\test.txt")));
DataOutputStream dos = new DataOutputStream(new FileOutputStream("D:\\test.txt"));
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
dos.writeBytes(String.valueOf(i) + "\r\n");
}
dos.close();
System.out.println("speed time: "+ (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
// DataInputStream dis = new DataInputStream(new BufferedInputStream(new FileInputStream("D:\\test.txt")));
DataInputStream dis = new DataInputStream(new FileInputStream("D:\\test.txt"));
while (dis.readLine() != null){
// System.out.println(dis.readLine());
}
dis.close();
System.out.println("speed time: "+ (System.currentTimeMillis() - start));
}
- 没有Buffer的耗时分别是203, 138 ,添加缓存BufferInputStream的方式耗时分别是11,10 读写都差了一个数量级,很明显的性能提升。并且FileReader和FileWriter的性能要优于直接使用FileInputStream和FileOutputStream用同样代码可以得出
使用clone()代替new
- java中新建对象一般new关键字,但是如果对象构造函数过于复杂,会导致对象实例化变得十分耗时且消耗资源,此时Object.clone方法会更好的选择。
- 原因在于Object.clone()方法可以绕过对象构造方法,快速复制一个对象实例,跳过了构造函数对性能的影响
静态方法替换实例方法
- 使用static字段修饰的方法是静态方法,java中由于实例方法需要维护一张类似虚拟函数表的结构,以实现对多台的支持。与今天方法相比,实例方法的调用需要更多资源。工具方法没有对其进行重载的必要,更适合于用作为静态方法。
并行程序开发及优化
并行程序设计模式
- 常见的并行设计模式有Future模式,Master-Worker,Guarded Suspeionsion,不变模式,生产者消费者模式
Future模式
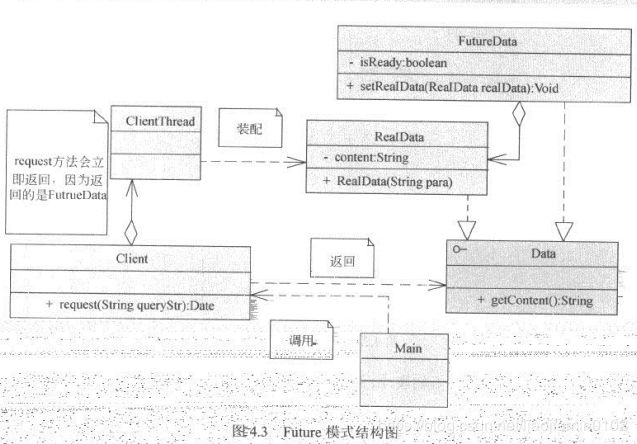
-
简单说就是一个异步获取的流程,在main函数中利用Future提交一个任务线程task,但是这个任务执行是有耗时的,并不会立刻返回,此时main函数无需等待或者阻塞,可以继续main函数之后的逻辑,等结果是必要因素的时候通过Future.get来阻塞等待获取对应信息。如下图解
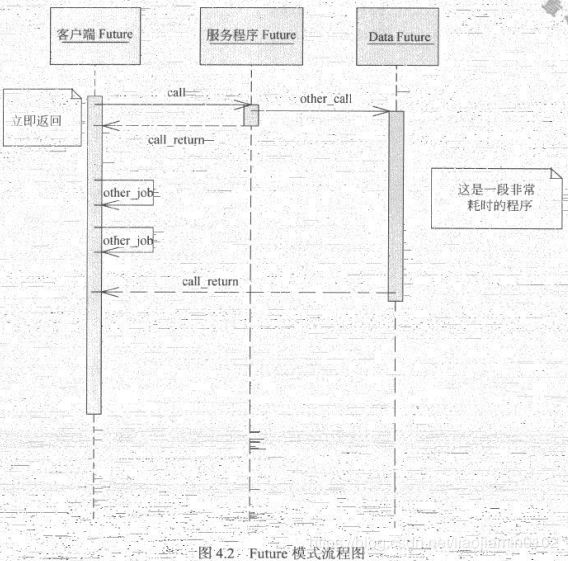
-
如下源码,自己实现的一个Future模式实现
public interface Data {
public String getResult();
}
public class RealData implements Data {
protected final String result;
public RealData(String para){
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append(para);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
result = sb.toString();
}
@Override
public String getResult() {
return result;
}
}
public class FutureData implements Data {
protected RealData realData = null;
protected boolean isReady = false;
public synchronized void setRealData(RealData realData){
if(isReady){
return;
}
this.realData = realData;
isReady = true;
notifyAll();
}
@Override
public String getResult() {
while (!isReady){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return realData.result;
}
}
public class Client {
public Data request(final String queryStr){
final FutureData futureData = new FutureData();
new Thread(){
@Override
public void run(){
RealData realData = new RealData(queryStr);
futureData.setRealData(realData);
}
}.start();
return futureData;
}
}
public class MainTest {
public static void main(String[] args) {
Client client = new Client();
Data data = client.request("my name");
System.out.println("request over");
try {
System.out.println("sleep 2000ms");
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("data = "+ data.getResult());
}
}
- 以上代码中FutureData实现了一个快速返回的RealData包装。他只是一个包装,或者说是一个RealData的虚拟实现,并且设置FutureData的getReault的时候回被wait阻塞,等待RealData被注入才能返回
- FutureData是Future模式的关键,时间上是真实数据RealData的代理,封装了RealData的等待过程。
- UML图如下
JDK的内置实现
-
Future模式在JDK的并发包中内置了一个实现,比以上Demo更加复杂,如下类图
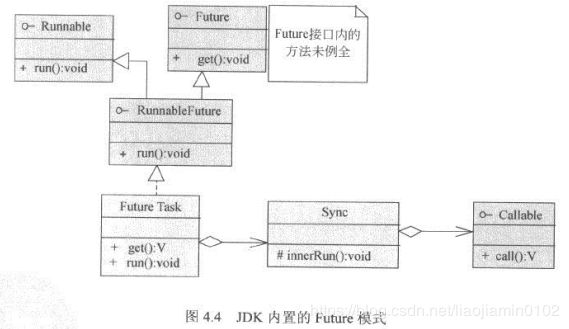
-
其中FutureTask类重要类,FutureTask提供线程控制的功能:
public boolean cancel(boolean mayInterruptIfRunning)
public boolean isCancelled()
public boolean isDone()
public V get() throws InterruptedException, ExecutionException
public V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException
- 我们将上一步骤中自己的Demo用JDK的Future实现。如下改进的代码变更简单,直接通过RealData构造FutureTask将其作为单独线程运行,通过FutureTask.get()方法获取结果。
public class NewRealData implements Callable<String> {
private String para;
public NewRealData(String para){
this.para = para;
}
@Override
public String call() throws Exception {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append(para);
Thread.sleep(100);
}
return sb.toString();
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(new NewRealData("my name"));
ExecutorService executor = Executors.newFixedThreadPool(1);
executor.submit(futureTask);
System.out.println("request over");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("data = "+ futureTask.get());
}
- Future模式核心优势在于去除了调用方的等待时间,并使得原本需要等待的时间段可以用于处理其他的业务逻辑,从而充分利用计算机资源。
Masher-Worker模式
- 核心思想:两部分,一个Master进程和一个Worker进程,Master负责接收分配任务,Worker负责处理任务,Worker处理完后结果返回给Master,由Master进程做归纳和汇总,从而得到最终结果。
- 优点:能够将大任务切分执行,提高系统吞吐量,每个子任务都是异步处理,无需Client等待,如下流程:
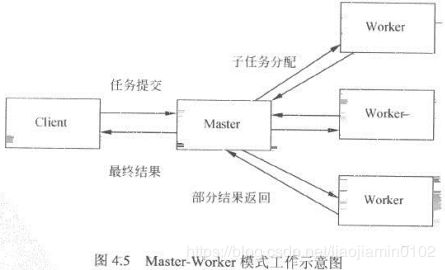
Master-Worker模式结构
- 维护一个Worker进程队列不断处理新任务,由master进程维护Worker队列类似线程池,如图:
- 自实现Demo
public class Worker implements Runnable {
protected Queue<Object> workQueue;
protected Map<String, Object> resultMap;
public void setWorkQueue(Queue<Object> workQueue) {
this.workQueue = workQueue;
}
public void setResultMap(Map<String, Object> resultMap) {
this.resultMap = resultMap;
}
//子任务处理逻辑,子类中实现具体逻辑
public Object handle(Object input) {
return input;
}
@Override
public void run() {
while (true) {
//获取子任务
Object input = workQueue.poll();
if (input == null) {
break;
}
//处理子任务
Object re = handle(input);
//处理结果写入结果集
resultMap.put(Integer.toString(input.hashCode()), re);
}
}
}
public class Master {
//任务队列
protected Queue<Object> workQueue = new ConcurrentLinkedQueue<>();
//worker进程队列
protected Map<String, Thread> threadMap = new HashMap<>();
//子任务处理结果集,此处必须用ConcurrentHashMap,否则多线程put必然存在线程不安全问题,造成size值与实际数据量不符合。
protected Map<String, Object> resultMap = new ConcurrentHashMap<>();
//所有子任务结束
public boolean isComplete(){
for (Map.Entry<String, Thread> stringThreadEntry : threadMap.entrySet()) {
if(stringThreadEntry.getValue().getState() != Thread.State.TERMINATED){
return false;
}
}
return true;
}
//Master的构造,需要一个Worker进程逻辑,需要Worker进程数
public Master(Worker worker, int countWroker){
worker.setResultMap(resultMap);
worker.setWorkQueue(workQueue);
for (int i = 0; i < countWroker; i++) {
threadMap.put(Integer.toString(i), new Thread(worker, Integer.toString(i)));
}
}
//提交一个任务
public void submit(Object obj){
workQueue.add(obj);
}
//返回子任务结果集
public Map<String, Object> getResultMap(){
return resultMap;
}
//运行所有worker进程,进行处理
public void execute(){
for (Map.Entry<String, Thread> stringThreadEntry : threadMap.entrySet()) {
stringThreadEntry.getValue().start();
}
}
}
- 利用如上Demo计算1~100 立方和
public class PlusWorker extends Worker {
@Override
public Object handle(Object input){
Integer i = (Integer) input;
return i*i*i;
}
}
public class MainTest {
public static void main(String[] args) {
Master m = new Master(new PlusWorker(), 5);
for (int i = 0; i < 100; i++) {
m.submit(i);
}
m.execute();
int re = 0;
Map<String, Object> resultMap = m.getResultMap();
while (resultMap.size() > 0 || !m.isComplete()){
Set<String> keys = resultMap.keySet();
String key = null;
for (String s : keys) {
key = s;
break;
}
Integer i = null;
if(key != null){
i = (Integer)resultMap.get(key);
}
if(i!= null){
re+=i;
}
if(key != null){
resultMap.remove(key);
}
}
System.out.println(re);
}
}
Guarded Suspension 模式
-
保护暂停模式,当服务进程准备好时候才提供服务。如下场景,服务器吞吐量有限的情况下,客户端不断的请求,可能会超时丢失请求,次数,我们将客户端请求进入队列,服务端一个一个处理。如下工作流图:
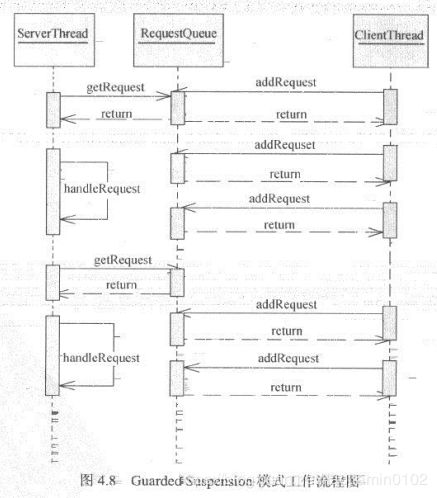
-
ResquestQueue队列用来缓存请求,使这种模式可以确保系统仅在有能力处理任务时候才获取队列这任务执行其他时间则等待。类似MQ提供的生产者消费者模式。如上模式并没有返回值的获取,有一定缺陷,如下改进流程图:
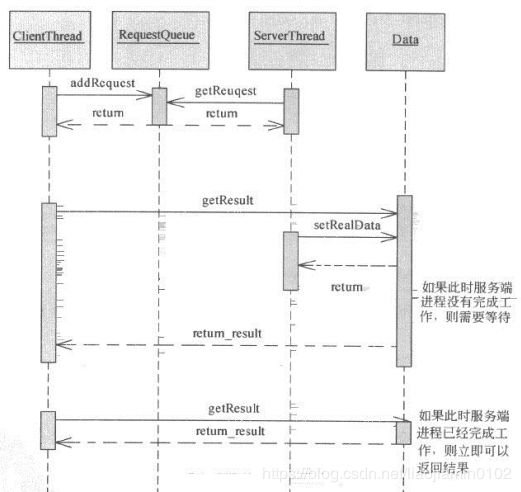
- 如上添加了Data类型,其实是参照了Future模式代码一样,此模式环境系统压力,将系统负载再时间轴上均匀分布,可以做到流量削峰的效果。
不变模式
- 为了在多线程环境下对象读写的线程安全性,如果新建的对象中属性是不可更改的,这样即使在高并发情况下也可以做到天生的线程安全。并且这中模式实现也简单,满足如下要求:
- 去除setter方法以及所有修改自身属性方法
- 将所有属性设置私有,用final标记,确保不可修改
- 确保没有子类可以重载修改它的行为
- 有一个可以创建完整对象的构造函数。
- 不变模式在JDK中使用比较多,比如基本数据类型和String类型中都是定义的final,但是不变模式是通过回避问题而不是解决问题的态度来处理多线程并发访问控制,可以在需求允许的情况下提高系统并发性能和并发量
生产者-消费者模式
- 经典的多线程设计模式,该模式中有两类线程,若干个生产者线程和若干消费者线程,在两者中间共享内存缓冲区,生产者和消费者互相不直接通信,通过内存缓冲区来交换信息,这样即使生产消费的速度不一致也不会影响业务的正常进行。
public class PCData {
private final int intData;
public PCData(int d ){
intData = d;
}
public PCData(String d){
intData = Integer.valueOf(d);
}
public int getIntData() {
return intData;
}
@Override
public String toString() {
return "PCData{" +
"intData=" + intData +
'}';
}
}
//生产者
public class Producer implements Runnable {
private volatile boolean isRunning = true;
private BlockingQueue<PCData> queue;
private static AtomicInteger count = new AtomicInteger();
private static final int SLEEPTIME = 1000;
public Producer(BlockingQueue<PCData> blockingQueue) {
this.queue = blockingQueue;
}
@Override
public void run() {
PCData data = null;
Random r = new Random();
System.out.println("start producer id = " + Thread.currentThread().getName());
try {
while (isRunning) {
Thread.sleep(r.nextInt(SLEEPTIME));
data = new PCData(count.incrementAndGet());
System.out.println(data + "is put into queue");
if (!queue.offer(data, 2, TimeUnit.SECONDS)) {
System.out.println("failed to put data: "+ data);
}
}
} catch (Exception e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
public void stop(){
isRunning = false;
}
}
//消费者
public class Consumer implements Runnable {
private BlockingQueue<PCData> queue;
private static final int SLEEPTIME = 1000;
public Consumer(BlockingQueue<PCData> queue){
this.queue = queue;
}
@Override
public void run() {
System.out.println("start consumer id= "+ Thread.currentThread().getId());
Random r = new Random();
try{
PCData pcData = queue.take();
if(null != pcData){
int re = pcData.getIntData() * pcData.getIntData();
System.out.println(MessageFormat.format("{0} * {1} ={2}", pcData.getIntData(), pcData.getIntData(), re));
Thread.sleep(r.nextInt(SLEEPTIME));
}
}catch (Exception e){
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}
//run
public static void main(String[] args) throws InterruptedException {
BlockingQueue<PCData> queue = new LinkedBlockingQueue<>(10);
Producer producer1 = new Producer(queue);
Producer producer2 = new Producer(queue);
Producer producer3 = new Producer(queue);
Consumer consumer1 = new Consumer(queue);
Consumer consumer2 = new Consumer(queue);
Consumer consumer3 = new Consumer(queue);
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(producer1);
executorService.execute(producer2);
executorService.execute(producer3);
executorService.execute(consumer1);
executorService.execute(consumer2);
executorService.execute(consumer3);
Thread.sleep(10*1000);
producer1.stop();
producer2.stop();
producer3.stop();
Thread.sleep(3000);
executorService.shutdown();
}
- 生产者消费者模式能很好对生产者线程和消费者现在进行解耦,优化了系统整体结构,同事由于缓冲区作业,运行
JDK多任务执行框架
- JDK提供了用于多线程管理的线程池
无限制线程池的缺陷
- 多线程的确可以最大限度的利用多核处理器的计算能了,但同时线程的创建销毁时有系统开销的,需要消耗内存,占用CPU资源,当线程创建无限制时候,反而会耗尽CPU和内存导致正常业务无法进行。
- 实际生产环境中,线程数必须得到控制,盲目地大量创建线程对系统性能是有伤害的。
简单线程池实现
- 线程池作用在于在多线程环境下避免线程不断创建和销毁所带来的额外开销。有线程池的存在,当系统需要一个线程时候,并不立刻创建线程,而是先去线程池查找是否有空余,若有,直接使用,若没有则将任务放入等待队列或者创建新线程,任务完成后将线程放回线程池。
- 简单线程池Demo
/**
* @author liaojiamin
* @Date:Created in 10:33 2020/4/15
*/
public class ThreadPool {
private static ThreadPool instance = null;
//空闲队列
private List<PThread> idleThreads;
//线程总数
private int threadCounter;
private boolean isShutDown = false;
private ThreadPool(){
this.idleThreads = new Vector<>(5);
threadCounter = 0;
}
public int getCreatedThreadsCount(){
return threadCounter;
}
//获取线程池实例
public synchronized static ThreadPool getInstance(){
if(instance == null){
instance = new ThreadPool();
}
return instance;
}
//结束池中所有线程
public synchronized void shutDown(){
isShutDown = true;
for (int i = 0; i < idleThreads.size(); i++) {
PThread idleThread = (PThread) idleThreads.get(i);
idleThread.shutDown();
}
}
//将线程放入池中
protected synchronized void repool(PThread repoolingThread){
if(!isShutDown){
idleThreads.add(repoolingThread);
}else {
repoolingThread.shutDown();
}
}
//执行任务
public synchronized void start(Runnable target){
PThread thread = null;
//有空闲闲置至今获取最后一个使用
if(idleThreads.size() > 0){
int lastIndex = idleThreads.size() - 1;
thread = (PThread) idleThreads.get(lastIndex);
idleThreads.remove(lastIndex);
thread.setTarget(target);
}else {
//没有空闲线程新增一个线程并使用
threadCounter ++ ;
thread = new PThread(target, "PThread #" + threadCounter, this);
thread.start();
}
}
}
public class PThread extends Thread {
//线程池
private ThreadPool threadPool;
//任务
private Runnable target;
private boolean isShutDown = false;
private boolean isIdle = false;
public PThread(Runnable target,String name, ThreadPool pool){
super(name);
this.threadPool = pool;
this.target = target;
}
public Runnable getTarget(){
return target;
}
public boolean isIdle(){
return isIdle;
}
@Override
public void run(){
//只有没有关闭,一直运行不结束线程
while (!isShutDown){
isIdle = false;
if(target != null){
//运行任务
target.run();
}
//结束,修改闲置状态
isIdle = true;
threadPool.repool(this);
synchronized (this){
try {
//等待新任务
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
isIdle = false;
}
}
public synchronized void setTarget(Runnable newTarget){
target = newTarget;
//设置任务后,通知run方法,开始执行任务
notifyAll();
}
public synchronized void shutDown(){
isShutDown = true;
notifyAll();
}
}
public class MyThread implements Runnable{
protected String name;
public MyThread(){}
public MyThread(String name){
this.name = name;
}
@Override
public void run() {
try {
Thread.sleep(100);
System.out.println("run target targetname: "+ Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
ThreadPool.getInstance().start(new MyThread("testThreadPool" + Integer.toString(i)));
//new Thread(new MyThread("testThreadPool" + Integer.toString(i))).start();
}
}
}
- 以上用线程池做1000 个任务与直接创建1000个线程做对比,线程池花费218 ms, 普通453ms,简单线程池的实现看起来效率更高,
Executor框架
-
其实JDK中提供了一套Executor框架,帮助开发人员有效的进行线程控制,如下ExecutorsUML图
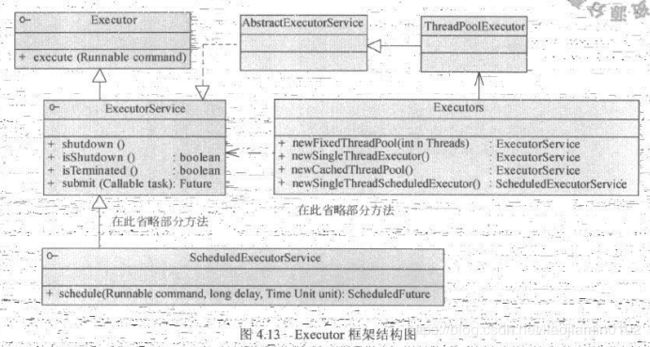
-
我们用executors来执行上面的demo
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
executorService.execute(new MyThread("testJDKThreadPool" + Integer.toString(i)));
}
- 运行的世界和上面线程池Demo近似265ms,Executors工厂类还有如下方法
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newWorkStealingPool(int parallelism)
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newCachedThreadPool()
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
- 以上工厂方法分表返回具有不同工种特性的线程池
- newFixedThreadPool()方法:返回一个固定线程数量的线程池,改线程池中线程数不变,当有一个新任务提交,线程池有空闲则只需,没有则添加到等待队列,等空闲之后才处理在队列中的任务
- newSingleThreadExecutor():返回一个只有一个线程的线程池,多余任务提交放入一个FIFO(先入先出)的顺序队列的任务中
- newCacheThreadPool():返回一个可根据实际情况调整线程数量的线程池,线程池数量不确定,有空闲则复用,没有则会建新线程处理任务,所有线程执行完放回线程池中
- newSingleThreadScheduledExecutor():返回一个ScheduledExecutorServer对象,线程池大小1,ScheduledExecutorService接口在ExecutorService接口上扩展了在给定实际执行某任务的功能,比如在某固定延迟后执行或者周期性来执行任务。
- newScheduledThreadPool:返回一个ScheduledExecutorService对象,但是可以指定线程数量。
- 如没有特殊要求,一般使用JDK内置线程池。不自己实现
自定义线程池
- 线程池底层实现用最多的是ThreadPoolExecutor,其中newFixedThreadPool, newSingleThreadExecutor,newCachedThreadPool都是使用的,我们来看ThreadPoolExecutor的构造。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
- 依次介绍参数含义:
- corePoolSize:指定线程池中核心线程数量
- maximumPoolSize:指定线程池中最大线程数
- keepAliveTime:当线程池数超过corePoolSize,多余的空闲线程存活时间。也就是超过corePoolSize的空闲线程在多久空闲时间后会被销毁
- unit:keepAliveTime的单位
- workQueue:任务队列,被提及尚未被执行的任务
- threadFactory:线程工厂,用于创建线程,一般用默认即可
- handler:拒绝策略,任务太多来不及处理,如何拒绝任务。
- workQueue是一个BlockingQueue接口对象,用于存放Runnable对象,可以用一下几个BlockingQueue:
- 直接提交的队列:这个由SynchronousQueue对象提供,他是一个特殊BolckingQueue,没有容量,每次insert操作都需要等待delete操作,反之也是同样。SynchronousQueue不保存任务,只是将任务提交给线程执行,没有空闲线程则创建,直到达到最大线程数,执行拒绝策略。
- 有界任务队列:可以使用ArrayBlockingQueue实现。ArrayBlockingQueue的构造函数必须带一个容量参数,标识最大容量。
- 当使用有界队列时候线程池中的情况:
- 有新任务需要执行,如果线程池现有线程数
- 如果线程池现有线程数>=corePoolSize,将任务加入等待队列
- 如果等待队列满,则无法加入,在总线程< maximumPoolSize前提下新建线程执行任务
- 如果此时现有线 > = maximumPoolSize,执行拒绝策略。
- 无界队列:LinkedBlockingQueue,无上限的一个队列,除非耗尽了系统资源否则无界队列不存在无法入队列情况,但是按照上面的规则,线程数量一直都会是corePoolSize的数量。
- 优先队列:带有执行优先级的队列,通过PriorityBlockingQueue实现,可控制任务的先后顺序,特殊的无界队列,总是确保最高优先级的任务先执行。
- 依据上面的规则,我们在来看JDK中几个线程池的实现
- newFixedThreadPool实现,返回一个corePoolSize和maximimPoolSize一样大的,使用LinkedBlockingQueue任务队列线程池,从而他不存在线程数的动态变化,而且他用的无界队列,任务提交频繁时候迅速耗尽资源
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- newSingleThreadExecutor方法corePoolSize和maximumPoolSize都是1 ,说明他永远只有一个线程存活,队列用的LinkedBlockingQueue也存在资源耗尽情况
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- newCacheThreadPool方法,corePoolSize为0 ,maximumPoolSize看成无穷大,意味着任务提交时候回用空闲线程执行,如果没有空闲,则加入SynchronousQueue队列,这种队列的特定是无容量的,也就是说没有空闲线程也不会入队列,而是直接创建线程,这中线程池也存在资源耗尽的危险。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
拒绝策略
- ThreadPoolExecutor最后一个参数指定拒绝策略,当任务超过系统承载的处理策略,JDK内置了四种策略。
- AborPolicy策略:抛出异常,组织系统正常工作,这个也是默认策略
- CallerRunsPolicy:只要线程池未关闭,该策略直接在调用者线程,运行当前被丢弃的任务
- DiscardOledestPolicy:丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务
- Discardpolicy:直接丢弃无法处理的任务,不做任务处理。
- 以上策略都实现了RejectedExecutionHandler,如果这几个都不满足业务,我们可以自己实现
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
- 以下用优先级队列的Demo
public class MyThread implements Runnable, Comparable<MyThread>{
private String name;
public MyThread(){}
public MyThread(String name){
this.name = name;
}
@Override
public int compareTo(MyThread o) {
int me = Integer.parseInt(this.name.split("_")[1]);
int other = Integer.parseInt(o.name.split("_")[1]);
if(me > other) {
return 1;
}else if(me < other) {
return -1;
}else {
return 0;
}
}
@Override
public void run() {
try {
Thread.sleep(100);
System.out.println(name + " ");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class MainTest {
public static void main(String[] args) {
ExecutorService executorService = new ThreadPoolExecutor(100,
200 , 0L, TimeUnit.SECONDS,
new PriorityBlockingQueue<Runnable>());
for (int i = 0; i < 1000; i++) {
executorService.execute(new MyThread("testThreadPoolExecutor3_" + Integer.toString((999-i))));
}
}
}
/**
testThreadPoolExecutor3_989
testThreadPoolExecutor3_998
testThreadPoolExecutor3_999
testThreadPoolExecutor3_997
testThreadPoolExecutor3_996
testThreadPoolExecutor3_995
testThreadPoolExecutor3_973
testThreadPoolExecutor3_936
testThreadPoolExecutor3_970
......
testThreadPoolExecutor3_1
testThreadPoolExecutor3_6
testThreadPoolExecutor3_8
testThreadPoolExecutor3_9
testThreadPoolExecutor3_5
testThreadPoolExecutor3_11
*/
- 调度中,线程以999,998~0 的顺序加入,以上是一个输出片段,可以看到在省略号之前都是按照我们预期的顺序执行的,之后是不规则顺序,那是因为我们设置了初始线程数量是100,也就是刚开始的时候并不会直接放入队列中,而是用现有的线程执行。
- 由此可见,使用自定义线程池可以提供更灵活的任务处理和电镀方式。在JDK内置线程池无法满足应用需求的时候,则可以考虑使用自定义线程池。
优化线程池大小
- 对线程池的大小设置需要考虑CPU数量,内存,JDBC链接等因素,在并发编程实战的数字有如下公式
Ncpu = cpu数量
Ucpu = 目标Cpu的使用率 0<= Ucpu <=1
W/C = 等待时间与计算时间的比率
- 为了保持处理器达到期望的使用率,最优的线程池的大小由如下公式得出,在java中我们用二方法得到
//公式
Nthread = Ncpu * (1+W/C)
//方法
Runtimg.getRuntime().availableProcessors();
扩展ThreadPoolExecutor
- ThreadPoolExecutor是一个可扩展的线程池,提供了三个可扩展接口:
protected void beforeExecute(Thread t, Runnable r)
protected void afterExecute(Runnable r, Throwable t)
protected void terminated()
- ThreadPoolExecutor.Worker.runWorker方法有如下实现(部分代码):
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//运行前
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//运行结束
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
- Worker是ThreadPoolExecutor的一个内部类,实现Runnable接口,ThreadPoolExecutor线程池中的工作线程也就是Worker,Worker.runWorker()会被线程池中多线程异步调用,所以before,after方法也会被多线程范文
- ThreadPoolExecutor实现中提供空的before和after方法,实际应用我们可以对他扩展,实现对线程状态的跟踪,比如增加一些日志的输出等。如下demo
public class MyThreadPoolExecutor extends ThreadPoolExecutor {
public MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
protected void beforeExecute(Thread t, Runnable r){
System.out.println("beforeExecute myThread name: "+ ((MyThread)r).getName() + "TID: " + t.getId());
}
@Override
protected void afterExecute(Runnable r, Throwable t){
System.out.println("afterExecute TID:" + Thread.currentThread().getId());
System.out.println("afterExecute PoolSize: "+ this.getPoolSize());
}
}
- 以上扩展方法带有日志输出功能,更好排查问题。
JDK并发数据结构
并发List
- Vector或者CopyOnWriteArrayList是线程安全的List,ArrayList是非线程安全的,应该避免在多线程环境中使用,如果业务需要,我们可以用Collections.synchronizedList(List list)进行包装,
- CopyOnWriteArrayList和Vector的内部实现是不同的,CopyOnWriteArrayList是一种比较特殊的实现,例如get()方法如下:
//CopyOnWriteArrayList源码
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
//Vector
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
-
如上源码对比来看CopyOnWriteArrayList的get()方法并没有任何锁操作,而对比Vector的get()是用了Synchronized,所有get操作之前必须取得对象锁才能进行。在高并发读的时候大量锁竞争非常消耗系统性能,我们可以得出,在读性能上,CopyOnWriteArrayList是更优的一种方式。
-
接下来看下两个的写入方式add的源码
//vector中add方法
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
//CopyOnWriteArrayList中add方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
- 由上部分源码中CopyOnWriteArrayList 每次add方法都会是一次复制,新建一个新数组,将老数组拷贝,并在新数组加入新来的元素,这种开销还是挺大的
- Vector中add方法其实就是一次synchronized之后的数组操作,出发需要扩容才会出现数组复制的情况,因此绝大多数情况写入性能比CopyOnWriteArrayList更优秀。
并发Set
- CopyOnWriteArraySet线程安全Set,实现了Set接口,内部实现完全依赖CopyOnWriteArrayList,所以特性和他一样,适合读多写少的情况。如果需要并发写的时候用到Set,我们可以用一下方式得到线程安全Set
//Collections包中的方法
public static <T> Set<T> synchronizedSet(Set<T> s)
高并发Map
- 因为Map是非线程安全,我们可用Collections的synchronizedMap()方法得到一个线程安全的Map,但并不是最优解,JDK提供专用高并发Map,ConcurrentHashMap性能更优
- ConcurrentHashMap维持高吞吐量得益于其内部实现是用的锁分离技术,同事ConcuttentHashMap的get操作也算无锁的。put操作的锁粒度小于同步的HashMap(HashTable),因此性能更优于同步HashMap
并发Queue
- JDK中有两套并发队列实现,ConcurrentLinkedQueue高性能队列,BlockingQueue阻塞队列,都继承自Queue接口,前者适用于高并发场景,通过无锁的凡是实现高并发状态的高性能性能高于BlockingQueue
- BlockingQueue的代表有LinkedBlockingQueue,与ConcurrentLinkedQueue使用场景不同,BlockingQueue主要用来简化多线程之间数据共享,典型的生产者–消费者模式,提供一种读写阻塞的模式,以下两种实现
- ArrayBlockingQueue:基于数组的阻塞队列,维护一个定长数组,缓存队列中的数据对象,还保存着两个整型变量,分表标识队列头部,尾部在数组中位置,还可以控制内部锁是否采用公平锁,默认非公平锁。
- LinkedBlockingQueue:一个基于链表的阻塞队列,生产者放入数据时候,将会缓存到一个链表中,生产者立刻返回,只又当缓冲链表达到最大容量,才阻塞生产者,知道有消费者从链表获取数据生产者才被换醒。
并发Deque
- jdk1.6 以后提供了一种双端队列,运行在队列头部或者尾部进行出队列和入队列。主要接口Deque,有三个实现类LinkedList,ArrayDeque和LinkedBlockingDeque,都实现了Deque,,
- linkedList使用的链表实现,有利于扩容,无需数组的复制,随机读取性能低
- ArrayDeque使用数组实现,拥有高效随机访问性能,更好的遍历性能,不利于数据扩容
- LinkedBlockingDeque,线程安全的双端队列实现,使用双向链表,没有读写锁分离,所有效率远低于LinkedBlockingQueue,更低于CocurrentLinkedQueue
并发控制方法
- JDK中提供多种途径实现多线程的并发控制,例如:内部锁,重入锁,读写锁,信号量等。
Java内存模型与volatile
- java每个线程有自己的工作内存,并且还有另外一块内存是给所有线程共享的,线程自己的工作内存区域存放这共享内存区域中变量值的拷贝,如下步骤以及图解
- 当执行拷贝时候,线程会先锁定并清除自己的工作内存区,这保证共享变量从共享内存区正确拷贝到自己的工作内存区域
- 装载到线程工作内存区域后,线程就可以操作对应的内存区域的数据,应为内存拷贝之后对值修改是共享的,即修改了本地内存变量,也就同时修改了共享内存中变量,所有只要保证当线程解锁是保证该工作内存区中变量值都已经写回到共享内存中。
- 以上图中步骤:使用use,赋值assign,装载load,存储store,锁定lock,解锁unlock,而主内存可以执行的操作有读read,写write,锁lock,解锁unlock
- 共享内存中变量值一定是由他本身或者其他线程存储到变量中的值,即使他被多个线程操作,也就是其中某个线程修改后的值,而线程工作内存中的局部变量的是线程安全的只能自己线程访问。
- 如上图4.18所示描述了线程工作内存与主内存的一些操作,其中use,assign很好理解,下面主内存和工作内存的操作
- read操作与相匹配的load操作总是成对出现,read读操作相,就想线程工作内存需要用一个局部变量去读取主内存中变量数据,之后在通过load操作加载到工作内存
- Store操作与write操作总是成对出现,store操作我需要将线程工作内存中的变量赋值给主内存变量的一个拷贝中,可以看成是一个局部变量,接着write操作将这个拷贝后的值写入到主内存中变量,完成修改操作。
- Double和Long操作比较特殊,因为只有他两是双精度64位,但是在32位操作系统中CPU最多一次性处理32位字长的数据,这将导致Double,Long类型需要CPU处理两次才能完成对一个数据的操作,可能存在多线程下非原子性的问题,所以需要将其声明为volatile进行同步处理。
- volatile关键字破事所有线程均读写主内存中的对应变量,从而使得volatile变量在多线程之间可见
- olatile变量可以做以下保证:
- 其他线程对变量的修改可以及时反映在当前线程中
- 确保当前线程对volatile变量的修改,能及时写会共享主内存中,并被其他线程所见
- 使用volatile申明的变量,编译器会保证其有序性。
同步关键字synchronized
- synchronized是java预约中最常见的同步方法,与其他同步方式比更简洁,代码可读性和维护性更好。并且从JDK1.6开始对其性能优化,已经和非公平锁的差距缩小,并且不断优化中。
- synchronized最常用方法如下,当method方法被调用,调用线程首先必须获得当前对象的锁,如果当前对象锁被其他线程持有,则需等待,方法结束才会释放锁,接着获取。synchronized中同步的代码越少越好,粒度越小越好。
public synchronized void method(){}
//等价如下
public void method(){
synchronized(this){
....
}
}
- 还有如下情况,用于static函数时候相当于Class对象上加锁,所有对改方法调用都需要获取Class对象锁。
public synchronized static void method(){}
- 为了实现多线程之间的交互,还需要使用Object对象的wait和notify方法
- wait可以让线程等待当前对象上的通知(notify被调用),在wait过程中,线程会释放对象锁,将锁让给其他等待线程获取。
- notify将唤醒一个等待在当前对象上的线程,如果当前有多个线程等待,则随机选择其中一个。
ReentrantLock重入锁
- 比synchronized功能更强大,可以中断,可定时。
- RentrantLock提供了公平,非公平两种锁
- 公平锁,保证锁在等待队列中的各个线程是可以公平获取的,不存在插队,永远先进先出。
- 非公平锁:不保证申请锁的公平性,申请锁能差多,
- 公平锁实现代价更大,从性能上分析,非公平锁性能好更多,无特殊需求选择非公平锁
public RentrantLock(boolean fair)
- RentrantLock使用完后必须释放锁,相比synchronized,JVM虚拟机总是会在最后自动释放synchronized锁。
- RentrantLock提供几个重要方法:
abstract void lock();//获得锁,如果被占用则等待
public void lockInterruptibly() throws InterruptedException //获得锁但有限响应中断
public boolean tryLock()//尝试获得,成功返回true,否则false,改方法不等待立刻返回
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException //给定实际内尝试获取锁
public void unlock()//释放锁
- lock与lockInterruptibly不同之处在于lockInterruptibly在锁等待的过程中可以响应中断事件。
ReadWriteLock读写锁
- 读写锁,jdk5开始提供这种锁,读写锁允许多个线程同时读取,但是如果有写操作在执行,其他操作需要等待写操作执行完后获取锁才能执行。
- 当读操作次数远远大于写操作,读写锁效率很高,提升系统性能
Condition对象
- Condition对象可以用于协调多线程间的复杂协作,Condition与锁相关联的,通过Lock接口的Condition newCondition方法可以生成一个与锁板顶的Condition实例。Condition对象与锁关系类似Object.wait与Object.notify两个函数已经synchronized关键字一样,配合使用完成多线程控制。Condition提供如下方法
void await() throws InterruptedException;
void awaitUninterruptibly();
long awaitNanos(long nanosTimeout) throws InterruptedException;
boolean await(long time, TimeUnit unit) throws InterruptedException;
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
- await()方法使当前线程等待,同时释放当前锁,当其他线程中使用signal()或者signalAll()方法时候,线程重新获得锁并执行。或者当前线程被中断时,也能跳出等待。
- awaitUninterruptibly()方法与await()基本相同,但是他并不会在等待过程中响应中断
- Singal()方法用于唤醒一个等待中的线程,相对singalAll方法会唤醒所有在等待中的线程。
- ArrayBlockingQueue为案例,利用Condition,ReentrantLock来实现队列满时候让生产者线程等待,又在队列空时让消费者线程等待。
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
/**初始化锁,对Condition进行赋值*/
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
//加入队列
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();//队列满 利用await阻塞添加
enqueue(e);
} finally {
lock.unlock();
}
}
//从队列中获取元素
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();//队列空,利用await阻塞获取
return dequeue();
} finally {
lock.unlock();
}
}
Semaphore信号量
- 信号量可以指定多个线程同时访问某个资源,如下构造方法
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
//参数一指定信号量准入大小,fair 指定是否公平获取信号量
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
- 提供如下几个主要方法控制线程
//尝试获取一个准入许可,无法获取则等待,知道有线程释放或者中断
public void acquire() throws InterruptedException
//尝试获取一个许可,成功返回true,否则false,不会等待直接返回
public boolean tryAcquire()
//线程访问资源结束后,释放一个许可,使其他等待许可的线程可以进行资源访问
public void release()
ThreadLocal线程局部变量
- ThreadLocal不提供锁,使用空间换时间的方式,为每个线程提供变量的独立副本,用这种方式解决线程安全的问题,因此他不是一种数据共享的解决方案。
- ThreadLocal并不具有绝对优势,只是并发的另外一种解决思想,在高并发量或者锁竞争激烈的场合,使用ThreadLocal可以在一定程度上减少锁竞争从而减少系统CPU损耗。
public void set(T value);//将次现场局部变量的当前线程副本中的值设置为指定值
public void remove();//移除此线程局部变量当前线程的值
public T get();//返回次现场局部变量的氮气线程副本中的值
- 我们用如下demo来测试ThreadLocal中变量是线程安全的:
public class ThreadLocalDemo implements Runnable{
public static final ThreadLocal<Date> localvar = new ThreadLocal<>();
private long time;
public ThreadLocalDemo(long time){
this.time = time;
}
@Override
public void run() {
Date d = new Date(time);
for (int i = 0; i < 50000; i++) {
localvar.set(d);//将d的值设置到线程的局部变量中
if(localvar.get().getTime() != time){//判断线程中值是否变化,如果有则输出
System.out.println("id = " + time + " localvar "+localvar.get().getTime());
}
}
}
public static void main(String[] args) throws InterruptedException {
//每次给与不同的时间测试是否有时间变化
for (int i = 0; i < 1000; i++) {
ThreadLocalDemo threadLocalDemo = new ThreadLocalDemo(new Date().getTime());
new Thread(threadLocalDemo).start();
Thread.sleep(100);
}
}
}
- 以上没有输出,即使在并发时候也可以保证多个线程间localvar变量是本线程独立的,即使没有同步操作,单多个线程数据互不影响。如下set源码解释本地线程安全性问题
public void set(T value) {
Thread t = Thread.currentThread();//获取当前线程
ThreadLocalMap map = getMap(t);//获取线程ThreadLocalMap对象,每个线程独有
if (map != null)
map.set(this, value);将value设置到map中,get方法也是从这里获取数据
else
createMap(t, value);
}
锁的性能和优化
- 锁性能优化和常见思路:避免死锁, 减小锁粒度,锁分离
线程开销
- 多核时代,并发提高效率是因为多线程尽可能的利用了多核心的工作优势,但是对比单线程方式也增加开销,系统需要维护多线程环境的上下文切换,线程共享内存,局部变量信息,线程调度等。
避免死锁
- 死锁是多线程特有问题,满足以下情况下出现死锁:
- 互斥条件:一个资源每次只能被一个线程持有
- 请求与保持条件:一个进程请求资源阻塞时候,对已获得的资源保持不放
- 不剥夺条件:若干线程之前形成,在未使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系
减少锁持有时间
- 尽量减少持有锁的时间,以减少线程间互斥的可能。
减少锁粒度
- 典型使用场景就是ConcurrentHashMap类实现的锁分段即使,他将整个HashMap分成若干段(Segment),每一段都是一个HashMap
- 例如在ConcurrentHashMap中增加一个新表项,并不是将整个HashMap加锁,首先更具HashCode获取数据落到哪一个段(segment)上,然后对该段加锁,并完成put操作,在并发put的时候,只要被操作的不是同一个段就可以真正做到并行
- 减少锁粒度缺点:当系统需要去全局锁时候,其资源的消耗会更多,例如ConcurrentHashMap里面我们需要获取每个Segment的锁后才能获取全局锁,因此我们应该通过其他方式避免这种操作
读写分离锁替换独占锁
- 读写锁共享读,独占写,可以有效提升系统并发能力。
锁分离
- 从读写锁中可以衍生出锁分离,我们在LinkedBlockingQueue中take,put操作实现可以看出这种思想的实现,因为LinkedBlockingQueue是链表,存取是不冲突的,如果是全局所,你们存取只能单个进行,效率很低,锁竞争激烈,JDK中用如下方法
/** Lock held by take, poll, etc take操作需要持有takeLock*/
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc put操作必须持有putLock*/
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
- 如上将take,put操作用两个锁来避开竞争关系,削弱了竞争可能性,如下实现:
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
//获取takeLock
final ReentrantLock takeLock = this.takeLock;
//不能有两个线程同时读数据
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {//没有数据一直等
notEmpty.await();//等待put操作中的notEmpty.signal方法释放
}
x = dequeue();//获取第一个数据节点
c = count.getAndDecrement();//统计数据增加1 原子操作
if (c > 1)
notEmpty.signal();//如果取出元素后还有剩余元素则通知其他take操作
} finally {
takeLock.unlock();//释放锁
}
if (c == capacity)
signalNotFull();//通知put操作,已经有剩余空间
return x;
}
//put操作类似,不重复
重入锁ReentrantLock,内部所synchronized
- 内部锁,重入锁功能上是重复的,使用上synchronized更简单,jvm会自动释放,ReentrantLock需要在finally中自己释放。
- 功能上ReentrantLock功能更强大功能,如下:
boolean tryLock(long time, TimeUnit unit);//锁等待时间功能
public void lockInterruptibly();//支持锁中断
public boolean tryLock()//快速锁轮换
- 以上功能都有效避免死锁的产生,从而提高系统稳定性。而且重入锁中的Condition机制可以进行复杂的线程控制,上面一节中已经有过说明。
锁粗化(Lock Coarsening)
- 本来应该锁的粒度越小越好,但是在某些情况下有必要对锁粒度进行扩大化,比如,我们连续不断请求释放同一个锁,这样JVM需要不断对同一个锁进行请求,释放,造成系统资源浪费,这个时候其实JVM也会帮我们做优化,将连续锁操作合成一个。
自旋锁(Spinning Lock)
- 自旋锁是JVM虚拟机多锁的优化,当多线程并发时候,频繁的官气和恢复操作会有很大系统开销,当获取锁的资源仅仅需要一小段CPU时间时候,锁的等待获取的时间可能就非常短,以至于比挂起和恢复的时间还要短,这就是一个问题了
- JVM引入的自旋锁就是为了解决上面问题,可以使线程在未获取到锁时候,不被挂起,而作一个空循环(即所谓的自旋),若干个空循环后,线程如果获得了锁,则只需,没有获取,则挂起
- 自旋后被挂起的几率变小,这种锁对那竞争不激烈并且锁占用时间少的并发线程有利,但是对竞争激烈,锁占用时间长大概率自旋后也大概率不能获取锁,徒增了CPU时间的占用,得不偿失。
- JVM通过虚拟机参数-XX: +UseSpinning参数开启自旋
- JVM通过虚拟机参数-XX:PreBlockSpin参数来设置自旋等待次数
锁消除(Lock Elimination)
- 锁消除是JVM在编译时候做的一个优化,当JVM对上下文进行解析时候,会去除一些不可能存在共享资源竞争的锁。也就是如果一个变量不可能存在多线程并发竞争的情况,但是他却有加锁,JVM会编译时候讲锁去除,以此避免不必要的锁获取消耗过程。
- JDK的API中有一些线程安全的工具类StringBuffer,Vector,在某些场合工具类内部同步方法是不必要的,JVM在运行时基于逃逸分析技术,捕获这些不存在禁止却有锁的代码,消除这些锁,以此提高性能。
- 逃逸分析可以使用JVM参数-XX:+DoEscapeAnalysis
- 消除锁可以用JVM参数-XX:+EliminateLocks
- 用如下案例分析:
public class LockTest {
private static final int CREATE = 20000000;
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < CREATE; i++) {
createStringBuffer("Java", "Performance");
}
long bufferCost = System.currentTimeMillis() - start;
System.out.println("createStringBUffer: "+ bufferCost + "ms");
}
public static String createStringBuffer(String str1, String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1);
sb.append(str2);
return sb.toString();
}
}
- 使用参数 -server -XX:-DoEscapeAnalysis -XX:-EliminateLocks 关闭逃逸分析和锁消除运行,相对耗时:1567ms
- 使用参数 -server -XX:+DoEscapeAnalysis -XX:+EliminateLocks 开启逃逸分析和锁消除运行,相对耗时:943ms
偏向锁(Biased Lock)
- JDK1.6开始提出的一种锁优化。核心思想:如果没有程序竞争,则取消之前已经取得锁的线程同步操作。就是说如果一段时间内所有竞争这个锁资源的线程都是同一个那么我就在这段时间点取消锁竞争避免锁定获取释放过程。
- JVM中可以用-XX:+UseBiasedLocking可以设置启用偏向锁
- 缺点:偏向锁在竞争激烈场合没有优化效果,因为竞争大导致有锁线程不停切换,锁也很难保存在偏向模式,次数,使用偏向锁大不大上面提到的性能优化还有损性能。
无锁的并行计算
- 非阻塞同步的线程安全方式
非阻塞的同步/无锁
- 基于锁方式存在他的弊端就是收核心限制线程竞争已经相互等待,而非阻塞则避开了这个问题,类似ThreadLoadl,还有一种更重要的基于比较交换的CAS(Compare And Swap)算法的无锁并发控制。
- CAS优势,非阻塞,无死锁情况,没有锁竞争开销,没有线程调度开销。
- CAS算法过程:CAS(V,E,N)。V表示需要更新的变量,E预期值,N新值。类似乐观锁的思想,当V==E时候,才将V值设置为N,如果V和E不同,则标识其他线程已经修改则不作更新,CAS返回当前V的真实值。更新失败并不挂起,而是被告知失败。
- 大部分处理器支持原子化CAS命令,JDK5 以后JVM可以使用这个指令实现并发操作和并发数据结构。
原子操作
- JDK的java.util.concurrent.atomc包下有一组无锁计算实现的原子操作类,例如AtomicInteger,AtomicLong,AtomicBoolean等,他们封装了对整数,长整型等对象多线程安全操作。以AtomicInteger为案例:
public final boolean get()
public final boolean compareAndSet(boolean expect, boolean update)
public boolean weakCompareAndSet(boolean expect, boolean update)
public final void set(boolean newValue)
public final void lazySet(boolean newValue)
public final boolean getAndSet(boolean newValue)
- 以getAndSet方法为例,看原因如何实现CAS算法工作流程:
public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);//unsafe方法操作系统底层命令的调用
}
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);//获取当前值
} while(!this.compareAndSwapInt(var1, var2, var5, var4));//尝试设置var4 作为新值,如果失败则继续循环直到成功为止
return var5;
}
- 如上代码是一个循环,循环退出条件是设置成功,并且返回原值,此处并没有用到锁,只是不停尝试。更新失败后继续获取当前值然后比较设置,继续循环而已,并没有干扰其他线程的相关代码。
- java.util.concurrent.atomic包中性类性能是非常优越的,包中的原子类是基于无锁算法实现的,他们的性能远优于普通有锁操作。
- 无锁的操作实际将多线程并发冲突交给应用层,不仅提升系统性能,还增加系统灵活性。相对的,算法以及编码的复杂度也明显增加了。
Amino框架介绍
- 无锁算法缺点是需要应用层处理线程的冲突问题,这增加开发难度和算法复杂度。现在Amino无锁框架提供了可用于线程安全的基于无锁算法的一些数据结构,同事还内置了一些多线程调度如下优势:
- 对死锁问题免疫
- 确保系统整体进度
- 高并发下无锁竞争带来的性能开销
- 可以轻易使用一些成熟无锁结构,无需自己研发
Amino集合
- 反正就是性能比JDK搞的一个框架,提供了基础数据例如List,Set这些
协程
- 进程— 线程— 协成,这三个概念是逐步拆分的一个过程,进程是一种重量级的调度方式,因为创建,调度,上下文切换的成本太高,因此我们将进程拆分为多个线程,将线程作为并发控制的基本单元,但是单并发在趋于激烈,为了在进一步提升系统性能,我们对线程在进一步分割就是协程。
- 无论进程,线程,协成在逻辑上都对应一个任务,执行一段逻辑代码。当使用协程实现一个任务时候,协程并不完全占据一个线程,当一个协程处于等待状态,CPU交给线程内的其他协程。与线程相比,协程间的切换更轻便,因此,具有更低的操作系统成本和更高的任务并发性。
- 协程优势:
- 协程的执行效率非常高,因为子进程切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比较,线程数量越多,协程的性能优势越明显
- 协程不需要多线程的锁机制,在协成中控制共享资源不加锁,只需要判断状态。
Kilim框架
-
协程不被java语言原生支持,我们可以使用kilim框架通过较低成本开发引入协程。
-
协程没有锁,同步块等概念,不会有多线程程序的复杂度,但是与java其他框架不同的是,开发后期需要通过kilim框架提供的织入(weaver)工具,将协程控制代码块织入原始代码,已支持协程的正常工作。如下图
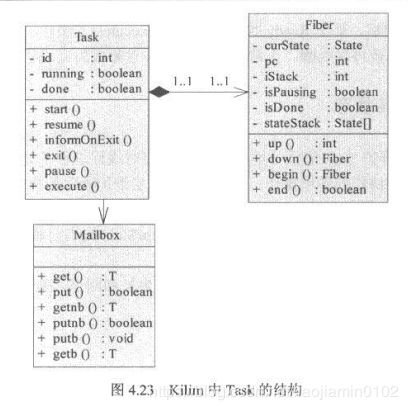
-
Task是协程的任务载体,execute方法用于执行任务代码,fiber对象保存和管理任务执行堆栈,以实现任务可以正常暂停和继续。Mailbox对象为协程间的通信载体,用于数据共享和信息交流。
Task及其状态
- Task多谢负责执行代码完成任务,kilim官网中状态图:
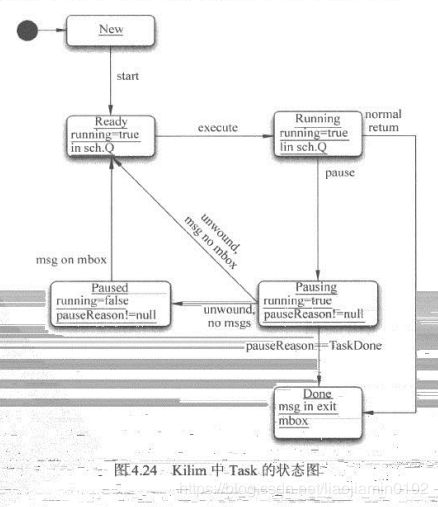
- Task创建后处于Ready状态,调用execute方法后,开始运行,期间可以被暂停,也可以被唤醒。正常结束后Task对象成为完成状态。
Fiber及其状态
-
Fiber用来维护Task执行堆栈,Kilim框架对线程进行分割,以支持更小的并行度,所以Kilim需要自己维护执行堆栈
-
Fiber主要成员如下:
- pc:程序计数器,记录当前执行位置
- curState:当前状态
- stateStack:协程的状态堆栈
- istack:当前栈位置
-
Fiber的up方法,down方法用于维护堆栈的生长和回退,如下fiber状态机:
-
上图所示,^ 符号 标识并且的医生,其中begin,down,end,up标识Fiber操作iStack=0/up可以解毒为:进行up操作后iStack=0
-
Kilim 框架中协程间的通讯和数据交换依靠Mailbox邮箱进行,就像管道,多个Task间共享,以生产者消费者作类比,生产者向Mailbox提交一个数据,消费者协程则想Mailbox中获取数据。
Kilim示例以及性能评估
- 协程拥有比线程更小粒度,所以理论上kilim的并发模型可以支持更高的并行度。使用kilim可以让系统更低成本的支持更高的并行度
JVM调优
java虚拟机内存模型
- 程序计数器:用于存放下一条运行的指令
- 虚拟机栈,本地方法栈:用于存放函数用堆栈信息
- java堆:存放程序运行时候需要的对象等数据方法区
- 方法区:用于存放程序的类元数据信息
程序计数器
- 是一块很小的空间,当我们用多线程时候,其实一个CPU一个时刻只能为一个现场提供服务,所以线程数超过CPU个数的时候,线程质检轮询争夺CPU资源。此时当一个线程被切换出去,为此需要程序计数器来记录这个独立线程运行到哪一个步骤指令,以便下一次轮询到继续执行的时候从这个步骤指令开始往下执行。
- 各个线程质检的计数器互补影响,独立工作,是一块线程私有的内存空间。
- 如果一个线程在执行java方法,程序计数器就在记录正在执行java字节码的地址,如果是一个Native方法,程序计数器为空。
java虚拟机栈
- 也是线程私有的内存空间,同java线程统一时刻创建,保存:局部变量,部分结果,并参与方法调用放回
- java虚拟机运行栈空间动态边,如果java线程计算栈深度大于最大可用深度异常StackOverFlowException,如果java动态扩容到内存不够异常:OutOfMamoryException
- 可用-Xss参数控制栈大小,如下测试,我们设置-Xss1M,之后设置-Xss2M
public class TestStack {
private static int count = 0;
public void recursion(){
count ++;
System.out.println("deep of stack :" + count);
recursion();
}
public static void main(String[] args) {
TestStack testStack = new TestStack();
try{
testStack.recursion();
}catch (Exception e){
System.out.println("deep of stack :" + count);
e.printStackTrace();
}
}
}
/**输出
1M栈输出
deep of stack :5544
Exception in thread "main" java.lang.StackOverflowError
at sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:691)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:579)
......
2M栈输出
deep of stack :11887
Exception in thread "main" java.lang.StackOverflowError
at sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:691)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:579)
at sun.nio.cs.StreamEncoder.implWrite(StreamEncoder.java:271)
**/
-
栈存储结构是栈帧,每个栈帧存放:
- 方法局部变量表
- 操作数栈
- 动态连接方法
- 返回地址
-
每个方法调用就是一次入栈,出栈过程,参数多,局部变量表就大,需要内存就大。如下图:
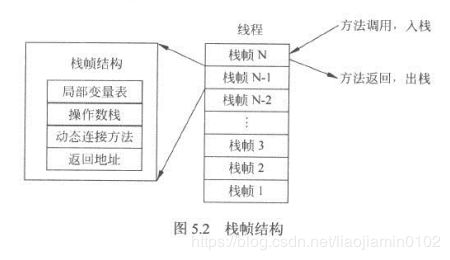
-
再次测试如下代码
public class TestStack {
private static int count = 0;
public void recursion(long a, long b, long c){
long d=0,e=0,f=0;
count ++;
System.out.println("deep of stack :" + count);
recursion(1l,2l,3l);
}
public static void main(String[] args) {
TestStack testStack = new TestStack();
try{
testStack.recursion(1l,2l,3l);
}catch (Exception e){
System.out.println("deep of stack :" + count);
e.printStackTrace();
}
}
}
//-Xss1M 输出
deep of stack :4167
Exception in thread "main" java.lang.StackOverflowError
at sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:691)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:579)
-
如上可看出,调用函数参数,局部变量越多,占用栈内存越大,导致调用次数比无参数时候下降5544–>4167
-
我们用idea中jclasslib插件看下class文件中的recursion方法

-
可见最大局部变量是13,是这么算的,局部变量存放单位字32位(并非字节),long,double是64为,两个字,所以三个参数,三个局部变量都是long 6*2=12个字,还有一个非static方法,虚拟机回将当前对象(this)最为参数通过局部变量传递给当前方法所以最终13字
-
局部变量中的字对GC有一定影响,如果局部变量被保存在局部变量表,GC根能引用到这个局部变量所指向的空间,可达性算法判断不可回收,因此不会清除,如下:
public static void test1(){
{
byte[] b = new Byte[6*1224*1024];
}
System.gc();
System.out.println(""s)
}
//GC日志
[GC (System.gc()) [PSYoungGen: 10006K->512K(38400K)] 10006K->7856K(125952K), 0.0077538 secs]
[Times: user=0.01 sys=0.01, real=0.01 secs]
[Full GC (System.gc()) [PSYoungGen: 512K->0K(38400K)]
[ParOldGen: 7344K->7739K(87552K)] 7856K->7739K(125952K),
[Metaspace: 3117K->3117K(1056768K)], 0.0070191 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
the first byte
- 以上GC日志显示已经回收,但是依据可达性分析算法是不能回收的,是GC做的其他优化,后续解答(???)
- 局部变量表中字可能会影响GC回收,如果这个字没有被后续代码复用,那么他引用的对象不会被GC释放。
本地方法栈
- 本地方法栈和虚拟机栈类似,只不过是用来管理本地方法调用,本地方法比不是用java实现,而是C实现,SUN的HotSpot虚拟机中不区分本地方法栈和虚拟机栈。因此和虚拟机栈一样会抛出StackOverFlowError,OutOfMemoryError
java堆
-
java堆运行是内存,几乎所有对象和数组都在堆空间分配内存,堆内存分为新生代存放刚产生对象和年轻对象,老年代,存放新生代中一定时间内一直没有被回收的对象。如下
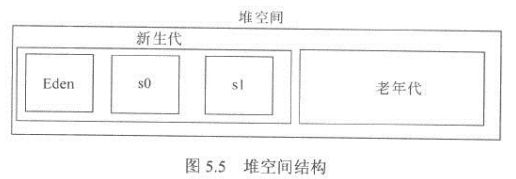
-
如上图,新生代分为三个部分:
- eden:对象刚建立时候存放的位置
- s0(surivivor space0 或者 from space),s1(survivor space1 或者通space):servivor意为幸存者空间,也就是存放其中的对象至少经历一次GC并新村。并如果幸存区到指定年龄还没被回收,则有机会进入老年代
-
如下案例我用JVM参数:
-XX:+PrintGCDetails //打印GC日志
-XX:SurvivorRatio=8 //JVM参数中有一个比较重要的参数SurvivorRatio,它定义了新生代中Eden区域和Survivor区域(From幸存区或To幸存区)的比例,默认为8,也就是说Eden占新生代的8/10,From幸存区和To幸存区各占新生代的1/10
-XX:MaxTenuringThreshold=15 //设置对象进入老年代需要的GC次数
-Xms20M // jjvm最小可用内存
-Xmx20M //jvm最大可用内存
-Xmn12M //年轻代大小设置
public class TestHeapGC {
public static void main(String[] args) {
byte[] b1 = new byte[1024*1024/2]; //0.5M
byte[] b2 = new byte[1024*1024*8]; //8M
b2 = null;
b2 = new byte[1024*1024*8]; //8M
// System.gc();
}
}
//GC日志
Heap
PSYoungGen total 11264K, used 9066K [0x00000007bf400000, 0x00000007c0000000, 0x00000007c0000000)
eden space 10240K, 84% used [0x00000007bf400000,0x00000007bfc66868,0x00000007bfe00000)
from space 1024K, 45% used [0x00000007bff00000,0x00000007bff74010,0x00000007c0000000)
to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)
ParOldGen total 8192K, used 1032K [0x00000007bec00000, 0x00000007bf400000, 0x00000007bf400000)
object space 8192K, 12% used [0x00000007bec00000,0x00000007bed02010,0x00000007bf400000)
Metaspace used 3134K, capacity 4494K, committed 4864K, reserved 1056768K
class space used 349K, capacity 386K, committed 512K, reserved 1048576K
- 上面GC日志是注释掉GC代码后生成,可以看到,进行了多次内存分配,我们算一下先分配8.5M,从fromspace使用率 92%,因为触发了GC,将eden中的b1移动到了from空间,最后分配的8MB,被分配到eden新生代,新生代设置12 并且按照8:1:1 分配,所以清理掉的0.5 M可以存放在from中,如果from更小,导致存放不下回直接到old区
- 我们打开gc看下:
Heap
PSYoungGen total 11264K, used 8744K [0x00000007bf400000, 0x00000007c0000000, 0x00000007c0000000)
eden space 10240K, 85% used [0x00000007bf400000,0x00000007bfc8a190,0x00000007bfe00000)
from space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)
to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)
ParOldGen total 8192K, used 1025K [0x00000007bec00000, 0x00000007bf400000, 0x00000007bf400000)
object space 8192K, 12% used [0x00000007bec00000,0x00000007bed00658,0x00000007bf400000)
Metaspace used 3175K, capacity 4494K, committed 4864K, reserved 1056768K
class space used 352K, capacity 386K, committed 512K, reserved 1048576K
- 如上,调试来几次Xmn的大小得出的结果,因为回更具对内存中年轻态的大小来决定GC之后存储的位置,上日志看出FUllGC后,新生代有一部分,老年态也有一部分,我猜测是原来的b1 到老年态,二最好的b2的8M内存在新生态。
方法区
- 方法区最重要的是类信息,常量池,域信息,方法信息。
- 类信息:类的名称,父类名称,类型修饰符(public/private/protected),类型的直接接口类表
- 常量池:类方法,域等信息引用的常量
- 域信息:域名称,域类型,域修饰符
- 方法信息:方法名,返回类型,方法参数,方法修饰符,方法字节码,操作数栈,方法栈帧的局部变量区大小以及异常表。
- HotSpot中方法去也成为永久区,GC对此部分也能回收,两点:
- GC对永久区常量池的回收
- 永久区对类元数据的回收
- 如下Demo测试常量池回收
//jvm参数:-XX:PermSize=1M -XX:MaxPermSize=2m -XX:+PrintGCDetails
public class TestGCPermGen {
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
String t = String.valueOf(i).intern();
}
}
}
//GC日志
.....
[GC (Allocation Failure) [PSYoungGen: 133568K->464K(138240K)] 133584K->480K(225792K), 0.1607520 secs] [Times: user=0.16 sys=0.00, real=0.16 secs]
[GC (Allocation Failure) [PSYoungGen: 133584K->448K(266752K)] 133600K->464K(354304K), 0.2681573 secs] [Times: user=0.26 sys=0.00, real=0.27 secs]
[GC (Allocation Failure) [PSYoungGen: 266688K->0K(266752K)] 266704K->428K(354304K), 0.4384817 secs] [Times: user=0.43 sys=0.01, real=0.44 secs]
....
- 以上代码无限循环中向常量池中添加对象,如果不清理必然OutOfMemoary,但是日上日志中得出,GC在一段时间后清理,使程序正常运行
- 类元数据回收需要构造N个类来测试对应GC回收情况如下DEMO用Javassist类库来生成类。
//jvm参数:-XX:PermSize=1M -XX:MaxPermSize=2m -XX:+PrintGCDetails
public class JavaBeanObject {
private String name = "java";
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public class JavaBeanGCTest {
public static void main(String[] args) throws Exception{
for (int i = 0; i < Integer.MAX_VALUE; i++) {
CtClass cc = ClassPool.getDefault().makeClass("Geym" + i);
cc.setSuperclass(ClassPool.getDefault().get("com.ljm.jvm.JavaBeanObject"));
Class clz = cc.toClass();
JavaBeanObject v = (JavaBeanObject) clz.newInstance();
}
}
}
GC日志:
......
[GC (Allocation Failure) [PSYoungGen: 832K->320K(1024K)] 2970K->2738K(3584K), 0.0010876 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 320K->0K(1024K)] [ParOldGen: 2418K->2058K(2560K)] 2738K->2058K(3584K), [Metaspace: 5480K->5480K(1056768K)], 0.0193576 secs] [Times: user=0.05 sys=0.00, real=0.02 secs]
[GC (Allocation Failure) [PSYoungGen: 512K->320K(1024K)] 2570K->2386K(3584K), 0.0004815 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 832K->352K(1024K)] 2898K->2690K(3584K), 0.0007751 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 352K->0K(1024K)] [ParOldGen: 2338K->2556K(2560K)] 2690K->2556K(3584K), [Metaspace: 5757K->5757K(1056768K)], 0.0174732 secs] [Times: user=0.04 sys=0.01, real=0.01 secs]
......
- 以上日志看出在一段时间后就回触发一次FullGC,之后并没有OOM,由此可见GC能够保证方法区中类元数据的回收。
JVM内存分配参数
设置最大堆内存
- 用-Xmx指定最大堆内存,最大堆指的是新生代+ 老年代大小只和的最大值。
设置最小堆内存
- 用-Xms设置最小对内存
- 意义在于:Java启动优先满足-Xms的指定大小,当指定内存不够才向操作系统申请,直到触及Xmx导致OOM,
- -Xms过小,JMV为保证系统尽量在指定范围内存工作,只能频繁的GC操作来释放内存,间接导致MinorGC和FUllCc的次数,如此啊测试
//参数:-XX:+PrintGCDetails -Xms1M -Xmx11M
public class GCTimesTest {
public static void main(String[] args) {
Vector vector = new Vector();
for (int i = 0; i < 20; i++) {
byte[] bytes = new byte[1024*1024];
vector.add(bytes);
if(vector.size() > 3){
vector.clear();
}
}
}
}
//GC日志
......
[GC (Allocation Failure) [PSYoungGen: 506K->400K(1024K)] 506K->408K(1536K), 0.0008198 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 805K->480K(1024K)] 7981K->7664K(9216K), 0.0010682 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 480K->496K(1024K)] 7664K->7680K(9216K), 0.0005386 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 496K->0K(1024K)] [ParOldGen: 7184K->1424K(3072K)] 7680K->1424K(4096K), [Metaspace: 3117K->3117K(1056768K)], 0.0063393 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 10K->96K(1536K)] 7579K->7664K(9728K), 0.0005220 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 96K->128K(1536K)] 7664K->7696K(9728K), 0.0003231 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 128K->0K(1536K)] [ParOldGen: 7568K->1411K(3584K)] 7696K->1411K(5120K), [Metaspace: 3169K->3169K(1056768K)], 0.0046456 secs] [Times: user=0.00 sys=0.01, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 31K->96K(3072K)] 7586K->7651K(11264K), 0.0003348 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
......
- 以上demo控制循环次数越多FullGC的次数越多,20次循环中有两次FullGC,修改JVM参数
-XX:+PrintGCDetails -Xms1M -Xmx11M
- 将最大堆,堆小堆都设置11M,只触发一次FUllGC,由此可见:
- JVM将系统内存尽量控制在-Xms大小内,当内存触及-Xms时候,就Full GC,我们将-Xms与-Xmx设置成一样可以在系统运行初期减少GC次数和耗时。
设置新生代
- 用-Xmn设置新生代的大小,新生代也会堆GC有比较大影响,如上案例在继续增加如下:
-XX:+PrintGCDetails -Xms11M -Xmx11M -Xmn2M
- 结果可以看的20次循环中又有2次FullGC
- HotSpot虚拟机中,-XX:NewSize设置新生代初始大小,-XX:MaxNewSize设置新生代最大值,只设置-Xmn等效同时设置这两个参数。
设置永久代,方法区
- 用-XX:MaxPermSize,-XX:PermSize,分别设置永久代最大,最小值,永久代直接决定来系统可以支持多少个类的定义,以及多少个产量,合理设置有助于系统动态类的生成。
public class JavaBeanGCTest {
public static void main(String[] args) throws Exception{
Integer count = 0;
try {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
CtClass cc = ClassPool.getDefault().makeClass("Geym" + i);
cc.setSuperclass(ClassPool.getDefault().get("com.ljm.jvm.JavaBeanObject"));
Class clz = cc.toClass();
JavaBeanObject v = (JavaBeanObject) clz.newInstance();
count++;
}
}catch (Exception e){
System.out.println("test test---------------------"+ count);
}
}
}
//JVM参数:-XX:PermSize=1M -XX:MaxPermSize=2m -XX:+PrintGCDetails
//JVM参数:-XX:PermSize=2M -XX:MaxPermSize=4m -XX:+PrintGCDetails
- 以上JVM参数分别可以运行4142 ,9333 次,一般我们设置MaxPermSize=64M可以满足绝大部分,不够的话可以增加128M,在不够就代优化代码了。
设置线程栈
- 使用-Xss参数设置线程栈大小
- 栈过小,将会导致线程运行时候没有足够空间分配聚币变量,或者达不到足够深度的栈深度调用,导致StackOverFlowError。栈空间过大,那么将导致开启线程所需要的内存成本上升,系统所能支持线程总数下降。
- 如下Demo测试固定栈空间下开设线程数量:
public class StackTest {
public static class MyThread extends Thread{
@Override
public void run(){
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
int i=0;
try {
for (i = 0; i < 1000000; i++) {
new MyThread().start();
}
}catch (Exception e){
System.out.println("count thread is " + i);
}
}
}
//JVM参数-Xss1M
- 很大可能是一直运行到结束并没有预期结果,调大-Xss10M并且增加循环次数,最大可能是死机原因在于,次数设置的是线程栈大小10M,也就是一个线程10M,每次创建都会向系统内存申请10M的内存,导致系统内存不够,从而电脑卡顿,死机都有可能,而最终应该是OutOfMemoryError。
堆比例分配
- 之前提了设置堆最大最小,新生代大小JVM参数配置,实际生产环境,希望能对对空间进行比例分配,有如下参数:
- 用-XX:SurivorRatio用来设置新生代中eden空间和from space,to space空间的比例关系,from空间和to空间大小相同,只能一样,并且在MinorGC后互换角色。
//JVM参数用-XX:+PrintGCDetails -Xmn10M -XX:SurvivorRatio=8测试:
PSYoungGen total 9216K, used 2516K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
eden space 8192K, 30% used [0x00000000ff600000,0x00000000ff875110,0x00000000ffe00000)
from space 1024K, 0% used [0x00000000fff00000,0x00000000fff00000,0x0000000100000000)
to space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
ParOldGen total 118784K, used 0K [0x0000000082200000, 0x0000000089600000, 0x00000000ff600000)
object space 118784K, 0% used [0x0000000082200000,0x0000000082200000,0x0000000089600000)
Metaspace used 3435K, capacity 4500K, committed 4864K, reserved 1056768K
class space used 374K, capacity 388K, committed 512K, reserved 1048576K
- 如上GC日志显示eden space大小8192 ,from区,to区都是1024,可见是8:1 的关系
我们使用参数 -XX:+PrintGCDetails -Xmn10M -XX:SurvivorRatio=2
Heap
PSYoungGen total 7680K, used 2327K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
eden space 5120K, 45% used [0x00000000ff600000,0x00000000ff845c60,0x00000000ffb00000)
from space 2560K, 0% used [0x00000000ffd80000,0x00000000ffd80000,0x0000000100000000)
to space 2560K, 0% used [0x00000000ffb00000,0x00000000ffb00000,0x00000000ffd80000)
ParOldGen total 118784K, used 0K [0x0000000082200000, 0x0000000089600000, 0x00000000ff600000)
object space 118784K, 0% used [0x0000000082200000,0x0000000082200000,0x0000000089600000)
Metaspace used 3445K, capacity 4500K, committed 4864K, reserved 1056768K
class space used 376K, capacity 388K, committed 512K, reserved 1048576K
- 如上GC日志,2:1 的关系,因为新生代10M所以计算eden=(10/(1+1+2))*2=5MB
- 同类型参数-XX:NewRatio=老年代/新生代,继续添加参数测试:
//Jvm参数设置:-XX:+PrintGCDetails -Xmn10M -XX:SurvivorRatio=2 -XX:NewRatio=2 -Xmx20M -Xms20M
PSYoungGen total 6144K, used 2350K [0x00000000ff980000, 0x0000000100000000, 0x0000000100000000)
eden space 5632K, 41% used [0x00000000ff980000,0x00000000ffbcba40,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 13824K, used 0K [0x00000000fec00000, 0x00000000ff980000, 0x00000000ff980000)
object space 13824K, 0% used [0x00000000fec00000,0x00000000fec00000,0x00000000ff980000)
Metaspace used 3454K, capacity 4500K, committed 4864K, reserved 1056768K
class space used 377K, capacity 388K, committed 512K, reserved 1048576K
- 如上堆内存20M,新生代老年代1:2,计算得到老年代12MB,和GC日志中13824 相符合。
- 总结
- -XX:SurvivorRatio=2 设置Eden与survivor区的比例
- -XX:NewRatio=2 设置老年代与新生代比例
- -Xms:堆内存初始大小
- -Xmx:堆内存最大大小
- -Xss:线程栈大小
- -XX:MinHeapFreeRatio:设置堆空间最小空闲比例,堆空间内存小于这个JVM会扩展堆空间
- -XX:MasHeapFreeRatio:设置堆空间最大空闲比例,当对空间空闲内存大于这个,会压缩堆空间,得到一个较小的堆
- -XX:NewSize :设置新生代大小
- -XX:MaxPermSize:设置最大持久区大小(方法区)
- -XX:PermSize : 设置永久区初始值(方法区)
- -XX:TargetSurvivorRatio:设置survivior区可使用率,当survivor区使用率达到这个数值,会将对象送入老年代。
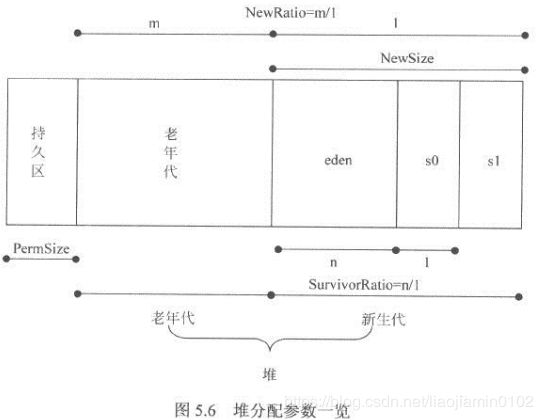
垃圾收集基础
垃圾收集作用
- Java和C++最大区别就是C++需要手动回收分配的内存,但是Java使用了垃圾收集器替代C++的手工管理方式减少程序员负担,减少出错几率。因此GC需解决一下问题:
- 那些对象需要回收
- 什么时候回收
- 怎么回收
GC回收算法与思想
引用计算算法
- 最古老的的GC算法,对象A,只要有任何对象引用了A就计数器+1,任何取消A引用-1,当引用为0,A就可以被清除
- 弊端在于无法解决相互引用的死局,例:A,B相互引用,但是没有任何第三方引用,根据算法是不可被回收,这种情况导致内存泄露。
- 不适合作为JVM的GC策略
标记清除算法(Mark-Sweep)
- 分两个步骤:
- 标记:通过根节点(java虚拟机栈中对象的引用)标记从根节点开始可达对象,未被标记则是可回收对象
- 清除:清除未被标记的对象
- 弊端:清理后产生空间碎片,空间是非连续空间,大对象分配时候,不连续内存空间工作效率更低。
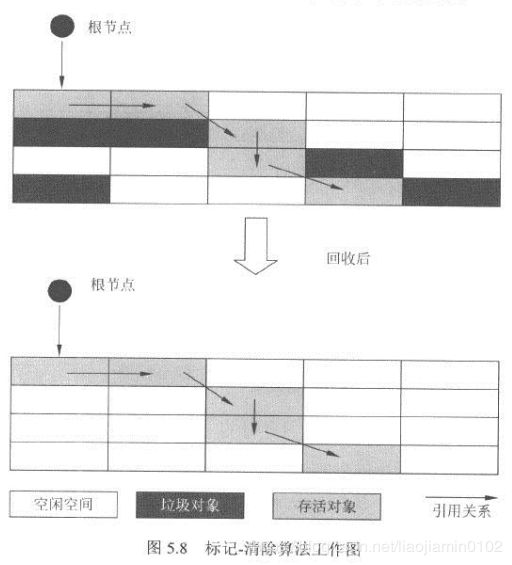
复制算法(Copying)
-
基于标记算法将原内存分两块,每次用其中一块,GC时候,将存活对象复制到另一块内存中,清楚原来内存块中所有对象,然后交换角色。
-
优势:如果系统中垃圾对象多,复制算法需要复制的就少,此时复制算法效率最高,并且统一复制到某一块内存,不会有内存碎片。
-
弊端:内存折半,负载自然降低。
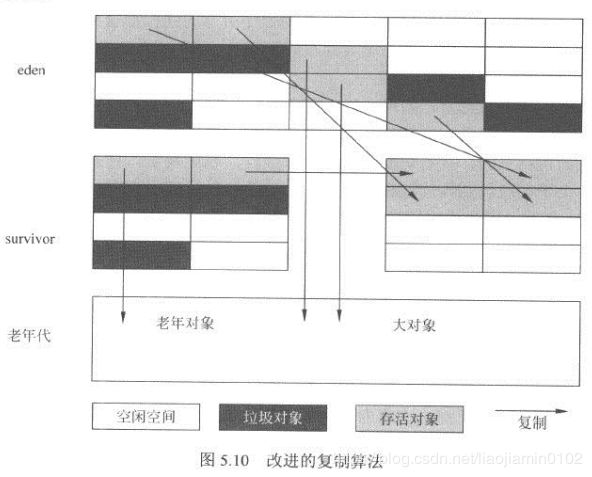
-
用处: Java新生代串行垃圾回收器使用复制算法,Eden空间,from,to空间三部分,from = to空间,天生就有区域划分,并且from与to空间角色互换。因此GC时候,eden空间存活对象复制到survivor空间(假设是to),正在使用的survivor(from)中的年前对象复制到to,大对象to放不下直接进入old区域,to满了,其他放不下的直接去old区域,之后清理eden与from去。
-
体现复制算法优势在新生代的合理性,新生代存活对象比例小,复制算法效果更佳
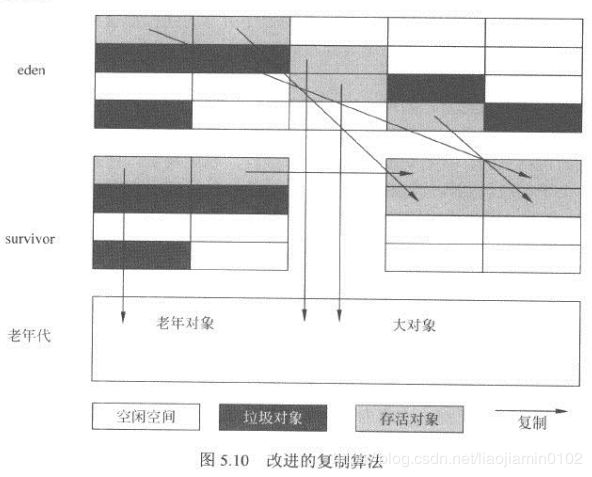
标记压缩算法(Mark-Compact)
- 一个老年代的回收算法
- 标记:和之前一样的通过根节点可达性分析获取被引用的对象,做标记
- 压缩:清理没标记对象并且将存活对象压缩到内存的一端,接着清理边界外所有空间,避免碎片产生
- 标记压缩,避免碎片化的同时不需要进行内存空间减半的风险,因此性价比高
- 老年代中存活对象多,不使用与复制算法,因此可以用标记压缩方式。

增量算法(Incremental Collecting)
- 为解决Stop the World状态提出的一种思想,GC时间长影响用户体验,
- 增量算法思想:一次性完成GC需要更多时间,我们让GC收集线程与应用线程交替执行,每次收集一部分区域,将对系统影响降到最低
- 弊端:线程切换和上下文切换的消耗一定程度影响应用程序性能是系统吞吐量下降,使GC总体成本上升
分代收集(Generational Collecting)
- 主要思想:按每个GC算法不同给合适的区域使用对应的GC算法。
- HotSpot案例:
- 年轻代:对象存活度低,使用复制算法,经过N次后,存活对象进入old区
- 老年代:对象存活度高,使用标记压缩算法,提高GC效率

垃圾收集器类型
- 如下图表分类:
| 分类 | 垃圾回收器类型 |
|---|---|
| 线程数 | 串行垃圾回收器 |
| 线程数 | 并行垃圾回收器 |
| 工作模式 | 并发垃圾回收器 |
| 工作模式 | 独占垃圾回收器 |
| 碎片处理 | 压缩垃圾回收器 |
| 碎片处理 | 非压缩垃圾回收器 |
| 分代 | 新生代垃圾回收器 |
| 分代 | 老年代圾回收器 |
评价GC策略的指标
- 一下指标评价GC处理器好坏
- 吞吐量:系统吞吐量 (系统总运行时间 = 应用程序耗时 + GC耗时)
- 垃圾回收器负载:垃圾回收器耗时与系统运行总时间比值
- 停顿时间:stop the word 时间
- 垃圾回收频率:通常增加对内存空间可以有效降低GC频率,但是会增加一次GC的耗时
- 反应时间:标记为垃圾后多久能清理
- 堆分配:不同垃圾收集器堆内存分配不同,好的收集器应该有一个合理的分配方式。
新生代串行收集器
- JDK中最老的也是最基本的回收器,有两个特点
- 第一仅仅使用单线程进行垃圾回收
- 第二他是独占式垃圾回收
- 此垃圾回收器工作,java应用程序必须听着,就是“Stop The World”,但是他是最成熟的一个,并且新能高,新生代中使用复制算法,逻辑简单
- JVM参数设置-XX:+UseSerialGC 来指定新生代中使用串行收集器,老年代中使用串行收集器
老年代串行收集器
- 老年代不同在于使用标记压缩算法,也是同样需要其他线程停顿,但是可以和多种新生代回收器配合用如下JVM参数
- -XX:UseSerialGC: 新生代,老年代都使用串行收集
- -XX:UseParNewGC:新生代用并行收集器,老年代用串型
- -XX:UseParallelGC:新生代用并行回收收集器,老年代使用串型收集器
并行收集器
- 只是将串型收集器多线程化,回收策略,算法都一样。
- 多核CPU系统下更快的处理,单核CPU系统下甚至比串型差
- 用以下参数:
- -XX:UseParNewGC:新生代用并行收集器,老年代用串型
- -XX:UseConcMarkSweepGC:新生代使用并行,老年代使用CMS
- 线程数指定JVM参数:-XX:ParallelGCThreads,一般设置CPU数量一样的线程,当cpu数量大于8,设置规则可安这个公式:3+[(5*CPU_Count)/8]
新生代并行回收(Parallel Scavenge)收集器
- 一个很牛逼的收集器,和并行比较,都是多线程,独占,但是他有一些关键的参数可以设置,我们可以用一下参数启用:
- -XX:+UseParallelGC:新生代用并行回收收集器,老年代用串型收集器
- -XX:+UseParallelOldGC:新生代老年代都用并行回收收集器
- 用如下JVM参数设置关键值:
- -XX:MaxGCPauseMillis:设置最大GC停顿时间,它自动调整java堆大小来控制GC的时间,如果时间设置的很短,他会使用一个较小堆,这样回收很快,但是回收频繁,吞吐量就降低来
- -XX:GCTimeRatio:这个设置吞吐量,比如设置N,那么他自动调节系统话费不超过1*(1+n)时间用于GC,默认99即不超过1% 的时间用来GC
- -XX:+UseAdptiveSizePolicy:这个开启自适应GC调节策略,此时新生代,eden和survivor的比例,晋升老年代时间都回被自动调节,以达到对大小,吞吐量和停顿时间的平衡点。在手工调节比较困难时候用这个,我们只要指定虚拟机最大堆,目标吞吐量(GCTimeRatio),和停顿时间(MaxGCPauseMillis)
老年代并行回收收集器
- 和新生代的并行回收收集器一样,只不过用的标记压缩算法
- JVM参数-XX:-UseParallelOldGC开启新生代老年代都使用并行回收收集器,其他JVM调优的参数新生代的一致
CMS收集器
-
Concurrent Mark Sweep,并发标记清除,标记清除算法,同时也是多线程并行回收的垃圾收集器回收过程如下:
- 初始标记: 标记GCRoots能直接管理到的对象,速度快(独占系统资源)
- 并发标记:GC Roots Tarcing过程,即可达性分析(并发的与用户线程一起)
- 重新标记:为修正上一个步骤中标记期间用户程序引起的对象标记的变动,重新进行更正(独占系统资源)
- 并发清楚:并行对未标记对象进行清楚(与用户线程一起)
- 并发重置:GC完成之后,重新初始化CMS数据结构和数据,为下一次垃圾回收做准备(与用户线程一起)
-
如下图所示:
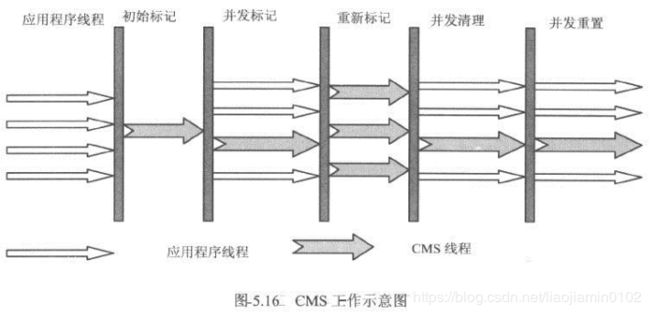
-
JVM参数介绍,CMS执行期间有部分并行执行,对吞吐量影响是不可避免的,
- CMS默认线程是(ParallelGCThread+3)/4,parallelGCThreads是新生代收集器线程数量
- 通过-XX:ParallelCMSThread参数手动设定CMS线程数
- CMS回收启动阀值设置:-XX:CMSInitiatingOccupancyFraction,默认68,也就是老年代空间使用率68% 时候,执行CMS回收,意义在于CMS是并行GC,GC进行同时应用线程也在运行必须占用一定资源,如果等到100% 在去GC就只能停顿,为了互不影响需要GC的同时保留一部分内存给用户线程,如果GC到一半内存不够,则CMS回收失败,JVM将启动老年代串行收集器,这样直接Stoptheworld。
- 内存压缩参数-XX:+UseCMSCompactAtFullCollection开关可以使CMS的GC完成后进行碎片整理
G1收集器(Garbage First)
link G1资源
-
G1是JDK1.6出试用,1.7 后才开始正式,java1.9的默认收集器,用于替代CMSDE新型GC,解决CMS空间碎片等一系列缺陷,是适用于java HotSpotVM的低暂停,服务器风格的分带式垃圾回收器。
-
要了解G1的GC原理,先要知道G1的一些设计理论。
Region:
- G1的结构内存在传统堆内存基础上在做了一次自定义的分割,G1将内存划分成了大小相等的内存块Region(默认512k),Region是逻辑上连续的,物理内存地址上不一定连续。每个内存地址都属于某一个堆内存区域比如:E:eden,S:Survivor,O:old,H:Humongous,其中O,H都是老年代。如下图:
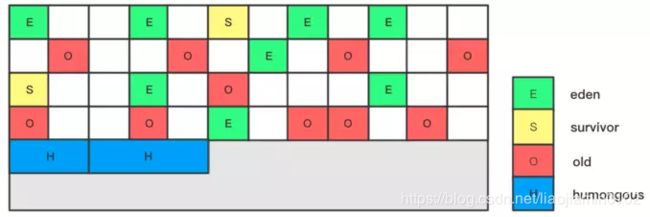
夸代引用
-
YoungGC的时候,Young区域(年轻代)对象还可能存在Old区的引用,这是夸代引用,此时如果年轻代GC触发,为避免扫描整个老年代,G1 引入了两个概念Card Table和Remember Set。思路是空间换时间,用来记录Old到Young区的引用。
- RSet:全称RememberSet,用来记录外部指向Region的所有引用,每个Region都维护一个RSet
- CardTable:JVM将内存划分成固定大小Card,也就是每个Region划分成多个card,逻辑上的划分。
-
如下图展示上面部分中数据结构:
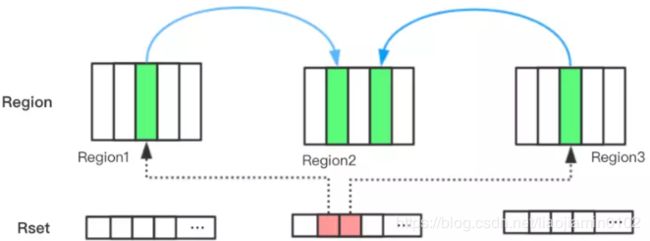
-
如上图,RSet与Card,每个Region多个Card,绿色部分Card表示这个card中有对象引用了其他card中对象,Rset是一个HashTable,key是Region的起始地址,value是catdTable类似Map
SATB
-
SATB全称(Snapshot At the Beginning)GC钱存活对象的快照。作用是保证并发标记阶段的正确性。理解整个我们需要先知道三色标记算法,如下图:
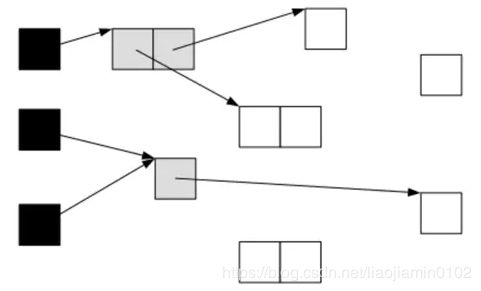
-
黑色:根对象,或者该对象与它的子对象都被扫描过
-
灰色:对象本身被扫描,单没有扫描他的子对象
-
白色:未被扫描对象,扫描完成所有对象后,最终为白色的是不可达对象即垃圾对象
-
如下案例GC扫码C之前颜色如下:
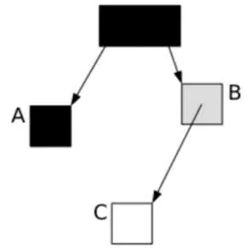
- 并发标记阶段,应用线程改变了引用关系,得到之后结果
A.c = C
B.c = null

- 在重新标记阶段结果如下:
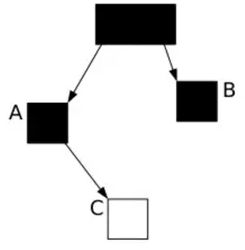
-
这种情况C会被清理,因为在第二阶段A已被标记黑色,说明A及其子类已经被扫描过,之后不会再重复扫描。此时Snapshot存活对象原来是A,B,C,现在是A,B。快照被破坏显然不合理。
-
解决凡是:G1 采用pre-write barrier解决,在并发标记阶段引用关系变化的记录都通过pre-write barrier存储在一个队列,JVM源码中这个队列叫satb_mark_queue。在remark阶段(重新标记阶段)会扫描这个队列,通过这种凡是旧的引用指向对象也会被标记,其子孙类递归标记上,不会漏任何对象,以此保证snapshot完整性。
-
此部分也是G1 相对CMS的一个优势,在remark阶段是独占的,CMS中incremental update设计使得它在remark阶段必须重新扫描所有线程栈和整个young gen作为root,但是G1 的SATB设计在remark阶段只需要扫描队剩下的satb_mark_queue,解决CMS的GC重新标记阶段长时间STW的潜在风险。
-
弊端: Satb方式记录存活对象,当snapshot时刻,可能之后这个对象就变成了垃圾,这个叫浮动垃圾(floating garbage),这种只能下次GC回收,这次GC过程中性分配的对象是活的,其他不可达对象就是死的。
-
接着又有问题:下次GC如何区分哪些对象是GC开始后重新分配,哪些是浮动垃圾
- Region中通过top-at-mark-start(TAMS)指针,分别为prevTAMS和nextTAMS记录新分配对象如下图
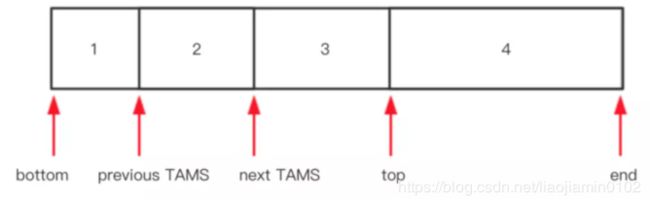
- Region中通过top-at-mark-start(TAMS)指针,分别为prevTAMS和nextTAMS记录新分配对象如下图
-
如上Region中指针设计,top是region当前指针
- [bottom,top) 区间是已用部分,[top, end)是未使用的可分配空间
- [bottom,prevTAMS):这部分对象存活信息通过prevBitMap来记录
- [prevTAMS,nextTAMS):这部分对象在n-1轮concurrent marking隐式存活
- [nextTAMS,top):这部分对象在第N轮concurrent marking是隐式存活
-
通过以上几个区域划分可以得出每次GC应该清理的上次留下来的隐式存活对象并且进行清理。
G1 的Young GC
- Young GC回收的所有年轻代Region,和其他的垃圾收集器规则,算法类似,使用复制算法,当E区不能在分片新对象时候触发GC,如下图所示
- E区对象会移动到s区
- S区空间不够,E去对象直接到O区
- 同时S区的数据移动到新的S区,
- 如果S区部分对象达到一定年龄晋升O区
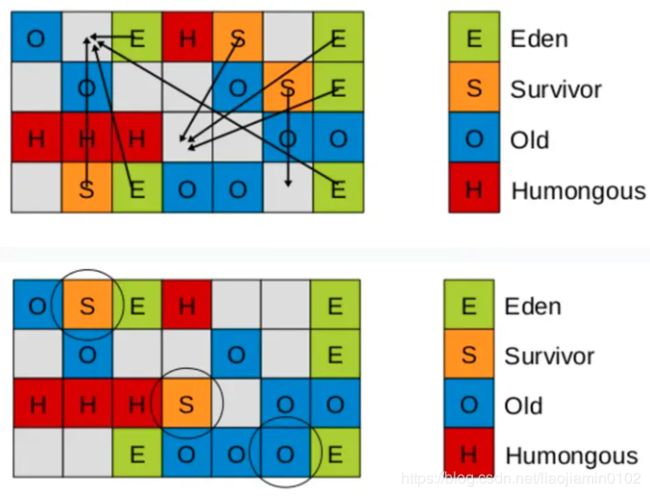
Mixed GC
- 混合回收,因为他回收所有年轻代Region+ 部分老年代的Region
- 为什么是老年代部分Region?
- 什么时候触发Mixed GC?
- 上面的问题一:回收部分老年代是参数-XX:MaxGCPauseMillis,用来指定一个G1收集过程目标停顿时间,默认值200ms,当然这只是一个期望值。G1的强大之处在于他有一个停顿预测模型(Pause Prediction Model),他会有选择的挑选部分Region,去尽量满足停顿时间,关于G1的这个模型是如何建立的,这里不做深究。
- 上面问题二:Mixed GC的触发也是由一些参数控制。比如XX:InitiatingHeapOccupancyPercent表示老年代占整个堆大小的百分比,默认值是45%,达到该阈值就会触发一次Mixed GC。
- Mixed GC主要分两个阶段
- 阶段一全局并发标记有如下几个环节
- 初始标记(initial mark,STW):标记GC root开始直接可达的对象。
- 并发标记(Concurrent Marking):这个阶段GC root开始对heap中对象的标记,标记线程与应用线程并行,并且手机各个Region存活对象信息,还扫描单文提到的SATB write barrier锁记录下的引用。
- 最终标记(Remark, STW):标记那些并发标记阶段发生变化的对象,将被回收
- 清除垃圾(cleanup,部分STW):这个阶段如果发现完全没有活对象的region就将其整体回收到可分配region列表,清除空Region
- 阶段二拷贝存活对象(Evacuation)
- Evacuation阶段是全暂停的。它负责把一部分region里的活对象拷贝到空region里去(并行拷贝),然后回收原来的region的空间。Evacuation阶段可以自由选择任意多个region来独立收集构成收集集合(collection set,简称CSet),CSet集合中Region的选定依赖于上文中提到的停顿预测模型,该阶段并不evacuate所有有活对象的region,只选择收益较高的region来evacuate,这种暂停的开销就可以一定范围可控。
- MixedGC清理过程示意图
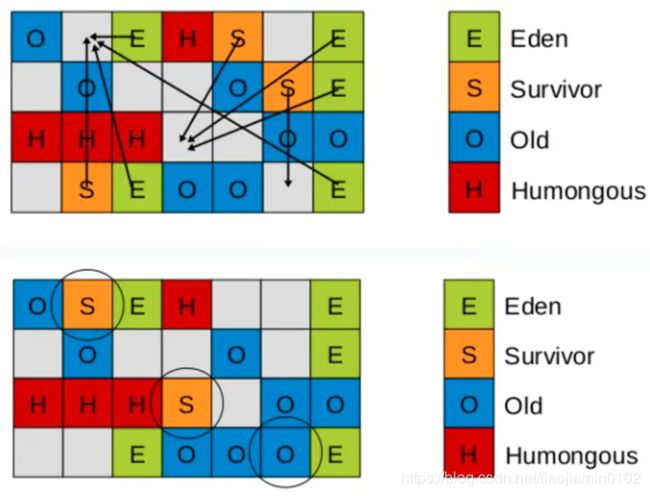
Full GC
- G1垃圾回收是和应用程序并发执行,当Mixed GC速度赶不上程序申请内存的速度,Mined G1 就只能降级到Full GC,使用的是Serial GC。导致长时间STW,导致切换到FullGC的原因可能有如下
- Evacuation的时候没有足够to-space存放晋升的对象
- GC并发处理过程完成之前空间耗尽
G1总结
- G1收集器用标记压缩算法,不产生碎片,没有CMS收集器中独立的碎片整理工作,G1收集器可以可以进行精确停顿控制,开发人员指定长度为M的时间段中GC时间不超过N。
- JVM相关参数如下:
//JVM参数控制启用G1回收器
-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC
-XX:MaxGCPauseMillis =50
-XX:GCPauseIntervalMillis = 200
StopTheWorld案例
- 用一个Demo模拟StopTheWorld说明Gc对程序性能的影响
public class StopTheWorldTest {
public static class MyThread extends Thread{
Map<Long, Object> map = new HashMap<>();
@Override
public void run(){
try {
while(true) {
if (map.size() * 512 / 1204 / 1024 >= 400) {//防止OOM
map.clear();
System.out.println("clean map");
}
byte[] b;
for (int i = 0; i < 100; i++) {
b = new byte[512];
map.put(System.nanoTime(), b);
}
}
}catch (Exception e){
}
}
}
public static class PrintThread extends Thread{
public static final long startTime = System.currentTimeMillis();
@Override
public void run(){
try{
while (true){
Long t = System.currentTimeMillis() -startTime;
System.out.println(t/1000+" . "+ t%1000);
Thread.sleep(100);
}
}catch (Exception e){
}
}
}
public static void main(String[] args) {
MyThread myThread = new MyThread();
PrintThread p =new PrintThread();
myThread.start();
p.start();
}
}
//JVM参数
-Xmx512M -Xms512M -XX:+UseSerialGC -Xloggc:gc.log -XX:+PrintGCDetails
//输出
......
1 . 977
2 . 715
[Full GC (Allocation Failure) [Tenured: 349567K->349567K(349568K), 0.3569460 secs] 506815K->506815K(506816K), [Metaspace: 3234K->3234K(1056768K)], 0.3569830 secs] [Times: user=0.35 sys=0.00, real=0.36 secs]
3 . 777
[Full GC (Allocation Failure) [Tenured: 349567K->349567K(349568K), 0.3663700 secs] 506815K->506815K(506816K), [Metaspace: 3238K->3238K(1056768K)], 0.3664147 secs] [Times: user=0.36 sys=0.00, real=0.36 secs]
[Full GC (Allocation Failure) [Tenured: 349568K->349568K(349568K), 0.4278699 secs] 506816K->506815K(506816K), [Metaspace: 3239K->3239K(1056768K)], 0.4279018 secs] [Times: user=0.42 sys=0.01, real=0.43 secs]
4 . 144
[Full GC (Allocation Failure) [Tenured: 349568K->349568K(349568K), 0.4185880 secs] 506815K->506815K(506816K), [Metaspace: 3240K->3240K(1056768K)], 0.4186427 secs] [Times: user=0.42 sys=0.00, real=0.42 secs]
[Full GC (Allocation Failure) [Tenured: 349568K->349568K(349568K), 0.4118220 secs] 506815K->506815K(506816K), [Metaspace: 3240K->3240K(1056768K)], 0.4118646 secs] [Times: user=0.40 sys=0.00, real=0.41 secs]
[Full GC (Allocation Failure) [Tenured: 349568K->349567K(349568K), 0.4089358 secs] 506815K->506815K(506816K), [Metaspace: 3240K->3240K(1056768K)], 0.4089639 secs] [Times: user=0.41 sys=0.00, real=0.41 secs]
.....
- 如上我们模拟内存申请,每毫秒打印,如果有一段时间不输出就是在GC中,如上日志中,1.977-2.715-3.777,这个过程中一直在fullGC,虽然只用几毫秒,但是频繁的中断打印线程
GC对系统新能影响
- 同样用一个DEMO说明GC对程序运行时间上的影响:
public class GCTimeTest {
static HashMap map = new HashMap();
public static void main(String[] args) {
long beginTime = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
if (map.size() * 512 / 1024 / 1024 >= 400) {
map.clear();
System.out.print("clean up");
}
byte[] b1;
for (int j = 0; j < 100; j++) {
b1 = new byte[512];
map.put(System.nanoTime(), b1);
}
}
long endTime = System.currentTimeMillis();
System.out.println(endTime - beginTime);
}
}
| 回收器 | 耗时ms |
|---|---|
| -Xmx512M -Xms512M -XX:+UseParNewGC | 1326 |
| -Xmx512M -Xms512M -XX:+UseParallelOldGC -XX:ParallelGCThreads=8 | 1565 |
| -Xmx512M -Xms512M -XX:+UseSerialGC | 1530 |
| -Xmx512M -Xms512M -XX:+UseConcMarkSweepGC | 1687 |
- 无奈,开始用20M堆测试和预期结果相反但是耗时差不多,推测应该是数量太小,GC需要清理的总内存也就那么多,得不出多月的结果,我们调节更大的对内存,清理时间必然更大应该就能得到对应的预期信息。
GC相关参数总结
- 与串型GC相关参数
- -XX:UseSerialGC:年轻代老年代都用串型收集器
- -XX:SurvivorRatio:设置eden区域和survivor区域的比例
- -XX:PretenureSizeThreshold:奢姿大对象进入老年代的阀值,当对象大小超过这个值,直接进入老年代
- -XX:MaxTernuringThreshold:设置对象进入老年代年龄最大值,每次MinorGC后,对象年龄+1,任何大于这个年龄的对象都进入老年代。
- 与并行相关参数
- -XX:+UseparNewGC:新生代使用并行收集
- -XX:+UseParallelOldGC:老年代使用并行回收收集器
- -XX:parallelGCThreads:设置用于垃圾回收的线程,通常情况和CPU一样,多核心CPU设置小的值也没错
- -XX:MaxGCPauseMillis:设置最大垃圾收集停顿时间,此时JVM自动调节对内存大小或者其他参数,控制时间在设置时间以内
- -XX:GCTimeRatio:设置吞吐量,如果设置N,那么系统话费不超过1/(1+n)的时间用于GC
- -XX:+UseAdaptiveSizePolicy: 打开自适应GC,此时新生代eden和survivor比例,晋升老年代对象年龄等参数都回被自动分配以达到堆大小,吞吐量和停顿时间的平衡
- 与CMS回收器相关参数
- -XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串型收集器
- -XX:ParallelGCThreads:设置CMS的线程数量
- -XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发,默认68%
- -XX:+UseCMSCompactAtFullCollection:设置CMS收集器在完成垃圾收集后师傅要进行一次内存碎片整理
- -XX:CMSFullGCsBeforeCompaction:设定进行多少次CMS垃圾回收后,进行一次内存压缩
- -XX:+CMSClassUnloadingEnabled:允许堆类元数据进行回收
- -XX:+CMSParallelRemarkEnable:启动并行重标记
- -XX:+CmsInitiatingPermOccupancyFraction:当永久区占用率达到这百分比时候,启动CMS回收(前提是CMSClassUnloadingEnabled 激活了)
- -XX:+CMSIncrementalMode:使用增量模式,比较适合单CPU
- 与G1相关的参数
- -XX:+UseG1GC:使用G1回收器
- -XX:+UnlockExperimentalVMOptions:允许使用试验性参数
- -XX:MaxGCPauseMillis:设置最大垃圾收集停顿时间
- -XX:GCPauseIntervalMillis:设置停顿时间间隔
- 其他参数
- -XX:+DisableExplicitGC:禁用显示GC
常用调优方案和方法
将对象预留在新生代
- 因为FullGC成本是全堆内存的清理,MinorGC是年轻代的GC,后者成本底,因此我们可以合理的设置新生代的内存大小,尽量将对象放在年轻代。如下Demo
public class PutInEden {
public static void main(String[] args) {
byte[] b1,b2,b3,b4,b5;//5M内存分配
b1 = new byte[1024*1024];
b2 = new byte[1024*1024];
b3 = new byte[1024*1024];
b4 = new byte[1024*1024];
b5 = new byte[1024*1024];
}
}
- 我们首先使用JVM参数 -XX:+PrintGCDetails -Xmx20M -Xms20M,可以看的如下GC日志,eden,from,to 年轻代三部分中分配占用5M,0.5M,0.5M空间,老年代13M内存,我们分配5M内存,其中eden使用1M,就是说只有b5在eden,其他的在from和old
PSYoungGen total 6144K, used 1633K [0x00000007bf980000, 0x00000007c0000000, 0x00000007c0000000)
eden space 5632K, 20% used [0x00000007bf980000,0x00000007bfa9c470,0x00000007bff00000)
from space 512K, 96% used [0x00000007bff00000,0x00000007bff7c010,0x00000007bff80000)
to space 512K, 0% used [0x00000007bff80000,0x00000007bff80000,0x00000007c0000000)
ParOldGen total 13824K, used 4104K [0x00000007bec00000, 0x00000007bf980000, 0x00000007bf980000)
object space 13824K, 29% used [0x00000007bec00000,0x00000007bf002040,0x00000007bf980000)
Metaspace used 3103K, capacity 4494K, committed 4864K, reserved 1056768K
class space used 343K, capacity 386K, committed 512K, reserved 1048576K
- 修改JVM参数:-XX:+PrintGCDetails -Xmx20M -Xms20M -Xmn9M,可以看的所有对象都在eden区域,增大来年轻代的大小,使其不必在老年代分配空间存储,同样的参数类型有-XX:NewRatio(新生代与老年代比值)
PSYoungGen total 8192K, used 6463K [0x00000007bf700000, 0x00000007c0000000, 0x00000007c0000000)
eden space 7168K, 90% used [0x00000007bf700000,0x00000007bfd4ff00,0x00000007bfe00000)
from space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)
to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)
ParOldGen total 11264K, used 0K [0x00000007bec00000, 0x00000007bf700000, 0x00000007bf700000)
object space 11264K, 0% used [0x00000007bec00000,0x00000007bec00000,0x00000007bf700000)
Metaspace used 3102K, capacity 4494K, committed 4864K, reserved 1056768K
class space used 343K, capacity 386K, committed 512K, reserved 1048576K
- 案例二
public class PutInEden {
public static void main(String[] args) {
byte[] b1,b2,b3,b4,b5;
b1 = new byte[1024*512];
b2 = new byte[1024*1024*4];
b3 = new byte[1024*1024*4];
b3=null;
b3 = new byte[1024*1024*4];
}
}
- 使用JVM参数 -XX:+PrintGCDetails -Xmx20M -Xms20M -Xmn10M
- 对内存20M,新生代10M,从GC日志中看出,eden区8M内存,在b3被分配时候,eden超过一般,触发gc将b1,b2 移动到了old区域,显然是不合理,期望的结果应该是到from,我们通过JVM参数调整from区大小,
PSYoungGen total 9216K, used 6123K [0x00000007bf600000, 0x00000007c0000000, 0x00000007c0000000)
eden space 8192K, 74% used [0x00000007bf600000,0x00000007bfbfae40,0x00000007bfe00000)
from space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)
to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)
ParOldGen total 10240K, used 8192K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)
object space 10240K, 80% used [0x00000007bec00000,0x00000007bf400020,0x00000007bf600000)
Metaspace used 3178K, capacity 4494K, committed 4864K, reserved 1056768K
class space used 353K, capacity 386K, committed 512K, reserved 1048576K
- JVM参数调节from区域:-XX:+PrintGCDetails -Xmx20M -Xms20M -Xmn10M -XX:SurvivorRatio=2,设置eden:from=2,实际是5120:2560符合预期设置,调整了from区域的大小使其能够存储下b1,如下from区占用40%,b2最终在old区,符合预期
PSYoungGen total 7680K, used 5274K [0x00000007bf600000, 0x00000007c0000000, 0x00000007c0000000)
eden space 5120K, 83% used [0x00000007bf600000,0x00000007bfa26858,0x00000007bfb00000)
from space 2560K, 40% used [0x00000007bfb00000,0x00000007bfc00010,0x00000007bfd80000)
to space 2560K, 0% used [0x00000007bfd80000,0x00000007bfd80000,0x00000007c0000000)
ParOldGen total 10240K, used 8200K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)
object space 10240K, 80% used [0x00000007bec00000,0x00000007bf402020,0x00000007bf600000)
Metaspace used 3178K, capacity 4494K, committed 4864K, reserved 1056768K
class space used 353K, capacity 386K, committed 512K, reserved 1048576K
大对象进入老年代
- 一般情况我们应该提倡对象在eden区域,但是如果一个大对象占用整个年轻代,其他对象不得不分配在old区域,这和堆GC相当不利,我们用-XX:PretenureSizeTHreshold来设置进入老年代的阀值,当对象大小超过设置直接在老年代分配内存。
- 例如-XX:PretenureSizeThreshold=1000000 ,设置阀值1M
设置对象进入老年代年龄
- JVM参数-XX:MaxTenuringThreshold设置进入老年代年龄默认是15,eden中对象经一次GC依然存活,进入from年龄记1,每经一次GC增加一,直到年龄等于设置的值则进入old区
- 并不是设置10 就一定10次GC才进入,因为对内存空间有限制,如果内存不足回提前进入old区,所以实际上对象进入old区的年龄是虚拟机更具内存大小动态计算的一个值和 设置的值中取最小值。
稳定与震荡的堆大小
- 一般我们设置堆内存-Xms,-Xmx,最大最小堆设置相同值得到一个稳定的堆内存空间,这样可以减少GC的次数,但是每次GC的时间都是比较长的(和小堆内存比较)
- 但是有一些特殊的业务,比如在某个时间段才需要1G的对内存,其他时间都只需要300M内存,这样每次GC需需要清理的控制仍然会是1G,此时我们可以利用如下两个参数
- -XX:MinHeapFreeRatio:设置堆内存最小空闲比例默认40。当堆内存空间空闲区域小于40%时候自动扩大堆内存
- -XX:MaxHeapFreeRatio:设置堆内存最大空闲比例默认70,当堆内存空间空闲区域大于70%时候自动缩小堆内存
- 注意用这两个参数必须设置-Xms与-Xmx不一样才能生效
吞吐量优先案例
- 现在服务器都是多核服务器,吞吐量优先情况我们优先考虑并行回收收集器,如下参数
java -Xmx3800M -Xms3800 -Xmn2G
-Xss128k //减少线程栈大小可以支持更多线程
-XX:+UseParallelGC //年轻代用并行回收收集器
-XX:ParallelGCThreads=20 //设置用于GC线程的数量
-XX:+UseParallelOldGC //老年代使用并行回收收集器
使用大页案例
- 在Solaris系统(Sun Microsystems研发的计算机操作系统。)JVM支持大页使用,使用大的内存分页可以增强CPU的内存寻址能力,从而提升系统新能。
- JVM参数使用-XX:LargePageSizeInBytes
降低停顿案例
- 降低GC耗时就能降低停顿,首先考虑关注系统停顿的CMS收集器,其次减少FullGC尽量将对象预留在新生代,使用Minor GC成本更小。我们有如下JVM参数
java -Xms2506M -Xmx2506M -Xmn1536M -Xss128k
-XX:ParallelGCThread=20 //并行回收收集线程20个
-XX:+UseConcMarkSweepGC //老年代使用CMS收集器
-XX:+UseParNewGC //年轻代使用并行回收器
-XX:SurvivorRatio=8 //年轻代eden:from=8:1
-XX:TargetSurvivorRatio=90 //设置survivor可食用的百分比90%,默认50%超过则进入老年代
-XX::MaxTenuringThreshold=31 //晋升老年代年龄31次GC,默认15
实用JVM参数
堆快照(堆Dump)
- 通过使用如下JVM参数可以使得到程序在OOM的时候将堆Dump信息输出到固定的目录中:
- -XX:+HeapDumpOnOutOfMemoryError 指定OOM的时候到处应用程序当前Dump
- -XX:HeapDumpPath 指定保存位置
Java VisualVM使用教程
- 以MAC为案例进行分析其他基本一致:
-
进入java_home目录下,控制态输入:/usr/libexec/java_home 可以获取java_home地址,
-
进入bin目录找到jvisualVM运行即可,可以看到如下:
-
执行需要监控的代码可以在本地目录下看到以及在运行的项目,双击既可到监控页面:
-
- 本次案例:
//JVM参数:-XX:+PrintGCDetails -Xmx5M -Xms5M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/jiamin
public class PutInEden {
public static void main(String[] args) throws InterruptedException {
Map<Object,Object> map = new HashMap<>();
byte[] b1;
for (int i = 0; i < Integer.MAX_VALUE; i++) {
b1 = new byte[100];
map.put(System.nanoTime(), b1);
Thread.sleep(100);
}
}
}
-
分配4M堆,指定dump文件目录,每一毫秒分配100B内存观察堆内存占用,GC次数一次每次GC时候堆内存变化,线程数量等新能指标,
-
以上堆空间循环上升按规律下降可以看出每一毫秒分配一个byte对象,并且加入map中,一定时间后回触发GC应为堆内存只有4M,也可手动执行GC,查看线程,当前内存信息,CPU信息呢,可从一下入口:
-
可以dump出当前堆快照查看当前时刻各个性能指标等功能。自动生成Dump文件,同样左边控制台上查看,并且支持OQL查询功能
错误处理
- 系统OOM,内存占满,CPU,带宽等资源应某种不可预知方式占用异常可能导致程序假死,我们可以设置某个情况触发运行第三方脚本来解除这种状态,如下:
- JVM参数:-XX:OnOutOfMemoryError=c:/reset.bat, 每当oom的时候我们执行这个第三方脚本
Jvisual对OQL的支持
- 堆内存快照分析时候,因为信息太多,我们可能一时查不到需要的类信息,你们OQL就提供了对象查询语言的支持
VisualVM的OQL基本语法
- 基本语法如下所示
select <javascript expression to select>
[
from [instanceof] <class name> <identifier>
[where <javaScript boolean expression to filter>]
]
- 三部分组成:
- select子句:指定查询结果要线上的内容
- from子句:指定查询范围,可指定类名,如java.lang.String,char[],
- where子句:指定查询条件
- 支持javascript语法处理较复杂的查询逻辑,select 中可以使用类似JSON的语法,输出多个例,from中可以使用instanceof关键字,将给定的子类也包括到输出中,如下案例中可以直接访问对象的属性和部分方法:
select s from byte[] s where s.length>=10
-
如下查询语句,还是PutInEden 案例来查询byte数组大于10 的对象信息,执行语句如下图结果信息:
-
上面案例是最基础查询方式,解析我们用JSON语法进行查询
select {instance:s, content:s.toString()} from java.lang.String s where /^\d{2}$/(s.toString))
- 上面用的JSON语法指定输出两例String对象,已经String.toString的输出,where正则匹配指定符合条件的字符串
- 查询文件路径已经文件对象,其中调用了类的toString方法:
select {content:file.path.toString(), instance:file} from java.io.File file
- 利用instance查询所有ClassLoader,包括子类
select c1 from instanceof java.lang.ClassLoader c1
内置heap对象
- heap对象是Visual VM OQL的内置对象,通过heap可以实现强大OQL功能:
- forEachClass():对每一个class对象执行一个回调操作,他的使用方法类似heap.forEachClass(callback),其中callback为javascript函数。
- findClass():查找指定名称的类对象,返回类的方法和属性,类似:heap.findClass(className);
- objects():返回对快照中所有对象集合,使用方法:heap.objects(clazz,[includeSubtypes], [filter])其中clazz指定类名称,includeSubtypes指定是否选出子类,filter为过滤器指定筛选规则,includeSubtypes和filter可以省略。
- livepaths:返回指定对象的存活路径,即显示哪些对象直接或者间接引用类给定对象。
- roots:这个堆的根对象使用方法 heap.roots()
//查找demo中指定名称对应的类
select heap.findClass("com.ljm.jvm.PutInEden").superclasses()
//查找IO包下的对象
select filter(heap.classes(), "java.io")
对象函数
- VIsualVM中OQL还提供类对象为操作目标的设置函数如下:
- classof函数:返回给定java对象类,调用方法如下,返回属性如下
- 有如下属性
- name:类名
- superclass:父类
- statics:类的静态变量的名称和值
- fields:类的域信息。
- class拥有以下方法
- isSubclassOf():是否是指定类的子类
- isSuperclassOf():是否是指定类的父类
- subclasses():返回所有子类
- superclasses():返回所有父类
select classof(v) from instanceof java.util.Vector v
- objectid函数:返回对象ID
select objectid(v) from java.util.Vector v
- reachables函数:返回给定对象的可达对象集合,使用方法如下:
reachables(obj,[filter])
//返回56 这个String对象的所有可达对象
select reachables(s) from java.lang.String s
where s.toString == '56'
- referees函数:返回给定对象的直接引用对象集合: referees(obj)
//返回FIle对象的静态成员变量引用
select referees(heap.findClass("java.io.File"))
- sizeof函数:返回指定对象大小,不包括对象的引用对象,因此sizeof的返回值由对象的类型决定,和对象具体内容无关
//返回所有byte数组的大小以及对象
select {size:sizeof(o), Object:o} from byte[] o
- rsizeof函数:返回对象及其引用对象的大小综合,即,深堆(Retained Size)不仅与类本身有关,还与对象当前数据内容有关
select {size:sizeof(o), rsize:rsizeof(o)}
from java.util.Vector o
集合统计函数
- contains函数:判断给定集合是否包含满足给定表达式的对象:contains(set, boolexpression)
- 内置对象:
- it:当前访问对象
- index:当前对象索引
- array:当前迭代的数组/集合
//返回被File对象引用的String对象的集合,先通过referrers得到所有引用String对象的对象集合,使用contains函数以及布尔等式将contains的筛选条件设置为类名是java.io.File的对象
select s.toString() from java.lang.String s where
contains(referrers(s), "classof(it).name == 'java.io.File'")
- count函数:返回指定集合内满足给定布尔表达式的对象数量。:count(set, [boolexpression]),boolexpression是布尔条件表达式同上面一样三个内置对象
select count(heap.classes(),"java.io")
- filter函数:返回给定集合中满足某一个布尔表达式的对象子集合
- length函数:返回给定集合的数量
- map函数:将结果集中的每一个元素按照特定规则转换,以方便输出显示。
- max函数:计算病得到给定集合的最大元素
- min函数:计算病得到给定集合的最小元素
- sort函数:堆指定集合进行排序
- top函数:在给定集合中,按照特定顺序排序的前几个对象
- sum函数:用于计算给定集合的累计值
程序化OQL
- VisualVM可以通过OQL相关的JAR包将OQL查询程序化,从而获得更加灵活的查询功能。实现堆快照分析的自动化。
- 略
取得GC信息
- 有如下JVM参数来获取GC信息
- -XX:+PrintGCDetails:打印GC总体情况,并且输出新生代,来年的格子GC以及耗时
- -XX:+PrintTenuringDistribution:查看新生对象晋升老年代实际阀值
- -XX:+PrintHeapAtGC:打印堆使用情况,比第一个更加详细包括两部分:GC前堆信息,GC后堆信息
- -XX:+PrintGCApplicationStoppedTime:显示应用程序在GC时候停顿时间
- -XX:+PrintGCApplicationConcurrentTime:显示应用程序在GC停顿期间执行时间
- -Xloggc 指定GC日志输出位置:-Xloggc:C:\gc.log
类与对象跟踪
- JVM参数中提供类用来观察类加载写在的参数
- -XX:+TraceClassLoading:类加载情况
- -XX:+TraceClassUnloading:类卸载情况
- -verbos:class:同时打开类加载卸载
控制GC
- JVM参数中:-XX:+DisableExplicitGC,用于禁止显示的GC也就是我们在代码中System.gc,这种操作,这做的原因在于JVM认为应该相信他的判断会在恰当时候发起GC
- 类回收问题:因为在绝大多数情况,不需要进行类的回收,因为类回收性价比太低,元数据被载入后基本回持续整个程序,进行类回收基本上释放不了多少空间。JVM参数通过 -Xnoclassgc 参数来控制在GC过程中不会发生类回收,间接提升GC性能
- -Xincgc:这个JVM参数让系统进行增量式GC,意思是用特定算法让GC线程和应用程序线程交叉执行,从而减少应用程序因为GC产生的停顿时间。
选择类校验器
- JDK1.6后默认用新的类校验器,参数:-XX:-UseSplitVerifier 用来关闭新校验器,开启旧校验器
- -XX:-FailOverToOldVerifier 关闭再教育功能:作用在于当新校验器校验失败,可以开启老校验器进行再次校验,但是时间增加
压缩指针
- 64位操作系统比32位版本内存占用大(1.5倍左右),因为64位拥有更宽的寻址空间,与32位比,指针长度翻倍,我们用如下JVM参数解决:
- -XX:+UseCompressedOops:打开后可以堆以下进行压缩:
- class属性指针(静态成员变量)
- 对象属性指针
- 普通对象数组的每个元素指针
- -XX:+UseCompressedOops:打开后可以堆以下进行压缩:
实战JVM调优
Tomcate简介与启动加速
- 首先增加打印GC参数,在catalina.sh增加配置参数如下,每次启动后都会生成一个GC日志问题:
JAVA_OPTS=" -Xloggc:/Users/jiamin/work_soft/tomcat7.0/apache-tomcat-7.0.77/gc.$$.log"
- 我们配置堆内存,病通过观察GC日志来堆Tomcat启动情况进行分析,配置如下参数:
JAVA_OPTS="-Xms32m -Xmx32m -Xloggc:/Users/jiamin/work_soft/tomcat7.0/apache-tomcat-7.0.77/gc.$$.log -XX:+DisableExplicitGC"
- 启动Tomcat并且查看GC日志信息
CommandLine flags: -XX:+DisableExplicitGC -XX:InitialHeapSize=33554432 -XX:MaxHeapSize=33554432 -XX:MaxNewSize=16777216 -XX:NewSize=16777216 -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
0.449: [GC (Allocation Failure) 12288K->3206K(30720K), 0.0054239 secs]
0.730: [GC (Allocation Failure) 15494K->5902K(30720K), 0.0059441 secs]
0.931: [GC (Allocation Failure) 18190K->8205K(30720K), 0.0049580 secs]
1.086: [GC (Allocation Failure) 20493K->10396K(30720K), 0.0067136 secs]
1.215: [GC (Allocation Failure) 22684K->12239K(30720K), 0.0054546 secs]
1.332: [GC (Allocation Failure) 24527K->14135K(24576K), 0.0048293 secs]
1.405: [GC (Allocation Failure) 20279K->15202K(27648K), 0.0049688 secs]
1.462: [GC (Allocation Failure) 21346K->15679K(27648K), 0.0027720 secs]
1.465: [Full GC (Ergonomics) 15679K->13990K(27648K), 0.0583449 secs]
141.964: [Full GC (Ergonomics) 20134K->9003K(27648K), 0.0463495 secs]
- 以上日志显示经过8次MinorGC两次FullGC,我们通设置新生代老年代比值的参数来扩大新生代减少FUllGC,如下:
JAVA_OPTS="-Xms32m -Xmx32m -Xloggc:/Users/jiamin/work_soft/tomcat7.0/apache-tomcat-7.0.77/gc.$$.log -XX:+DisableExplicitGC -XX:NewRatio=2"
- 得到gc日志信息
CommandLine flags: -XX:+DisableExplicitGC -XX:InitialHeapSize=33554432 -XX:MaxHeapSize=33554432 -XX:NewRatio=2 -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
0.311: [GC (Allocation Failure) 8704K->2424K(31744K), 0.0041321 secs]
0.617: [GC (Allocation Failure) 11128K->4419K(31744K), 0.0042971 secs]
0.835: [GC (Allocation Failure) 13123K->6160K(31744K), 0.0060738 secs]
0.983: [GC (Allocation Failure) 14864K->8129K(31744K), 0.0051707 secs]
1.072: [GC (Allocation Failure) 16833K->9418K(31744K), 0.0044853 secs]
1.193: [GC (Allocation Failure) 18122K->11046K(26624K), 0.0066215 secs]
1.238: [GC (Allocation Failure) 14630K->12013K(29184K), 0.0043997 secs]
1.298: [GC (Allocation Failure) 15597K->12212K(29184K), 0.0023517 secs]
1.334: [GC (Allocation Failure) 15794K->12356K(29184K), 0.0025246 secs]
1.356: [GC (Allocation Failure) 15940K->12762K(29184K), 0.0029685 secs]
1.390: [GC (Allocation Failure) 16346K->12849K(29184K), 0.0024812 secs]
1.453: [GC (Allocation Failure) 16433K->13049K(29184K), 0.0011466 secs]
1.512: [GC (Allocation Failure) 16633K->13312K(29184K), 0.0010865 secs]
1.531: [GC (Allocation Failure) 16896K->13693K(29184K), 0.0011136 secs]
1.557: [GC (Allocation Failure) 17277K->13926K(29184K), 0.0012882 secs]
1.578: [GC (Allocation Failure) 17510K->14371K(29184K), 0.0012781 secs]
- FullGC以及不存在,我们通过将新生代内存扩大方式减少FUllgc用MinorGC来替代。继续优化可以使用新生代并行回收收集器,因为大多都是MinorGC,这样可以将GC的影响尽可能缩小。
JAVA_OPTS="-Xms32m -Xmx32m -Xloggc:/Users/jiamin/work_soft/tomcat7.0/apache-tomcat-7.0.77/gc.$$.log -XX:+DisableExplicitGC -XX:NewRatio=2 -XX:+UseParallelGC"
- 优化结果Tomcat启动速度快来100来毫秒,以上是针对一个裸的tomcat我们可以通过JVM参数进行优化启动速度,如果有项目部署到上面,我们需要更具具体情况具体分析
Web项目调优情况
- 还是用刚才的Tomcat,我们用一个最简单的Blog项目,做试验,利用Jmeter来做压力测试与性能测试(JMeter是一个开源软件,能方便的堆Web应用程序尽量压力与性能测试),我们逐步用如下参数进行优化压测:
第一次:
JAVA_OPTS="-Xms512m -Xmx512m -XX:PermSize=32M -XX:MaxPermSize=32M -XX:+DisableExplicitGC"
第二次:
JAVA_OPTS="-Xms512m -Xmx512m -XX:PermSize=32M -XX:MaxPermSize=32M -XX:+PrintGCDetails -XVerify:none -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:ParallelGcThreads=8 -XX:+DisableExplicitGC"
第三次:
JAVA_OPTS="-Xms512m -Xmx512m -XX:PermSize=32M -XX:MaxPermSize=32M -XX:+PrintGCDetails -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:ParallelCMSTHreads=8, -XX:+UseCMSCOmpactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0(设定进行多少次CMS垃圾回收后,进行一次内存压缩)
-XX:CMSInitiatingOccupancFraction=78
-XX:SoftRefLRUPolicyMSPerMB=0
-XX:+CMSParallelRemarkEnabled
-XX:SurvivorRatio=1
-XX:+UseParNewGC"
- 如上参数分别测试:
- 第一次:用JMeter测试GC总次数下降到39次,TOmcat吞吐量上升到47.9/是,可以看到堆内存大小堆系统性能影响,如需要进一步提高吞吐量,可以使用并行回收收集器
- 第二三次,年轻代,老年代都使用并行回收收集器吞吐量在次提升51/s,谁我们还可以使用CMS收集器测试。同时我们还设置来一个较大都survivor区,将对象尽量留在年轻代,通过将FullGC触发的阀值设置为78%,即老年代占用达到78%时候才触发,
- 结论:JVM调优主要流程:
- 确定堆内存大小(-Xmx, -Xms)
- 合理分配新生代老年代(-XX:NewRatio,-Xmn,-XX:SurvivorRatio)
- 确定永久区大小(-XX:Permsize, -XX:MaxPermSize)
- 选择垃圾收集器,堆垃圾收集器进行合理设置,禁用显示GC(-XX:+DeisableExplicitGC),禁用类元数据回收(-Xboclassgc),禁用类验证(-XVerify:none)
Java性能调优工具
Linux命令行工具
- top命令是linux下常用的性能分析工具,能够实时显示各个进程的资源占用状态。如下图
- top中信息分两部分,上面是系统统计信息,后面是进程信息
- 第一部分中信息
- 第一行是分五对了,结果等于uptime命令,左到右依次表示:系统当前时间,系统运行时间,当前登陆用户数,最后的load average 表示系统平均负载,即任务队列的平均长度,这三个值分别表示1分钟,5分钟,15分钟到现在的平均值
- 第二行进程统计信息,分别有正在运行的,睡眠的进程,停止的进程,僵尸进程数量
- 第三行是CPU统计信息,us表示用户空间CPU占用,SY表示内核空间CPU占用,NI表示用户进程空间改变过优先级的进程CPU占用,id表示空间CPU占用,wa表示等待输入输出的CPU时间百分比,hi表示硬件中断请求,si表示软件中断请求
- Men行中,从左到右依次表示物理内存总量,已使用物理内存,空闲物理内存,内核缓冲使用量
- Swap行依次表示交换区总量,空闲交换区大小,缓冲交换区大小
- 第二部分是进程信息区,显示系统中各个进程的资源使用情况:
- PID:进程id
- PPID:父进程ID
- REUSEF:Real user name
- UID:进程所有这的用户id
- USER:进程所有者用户名
- GROUP:进程所有者组名
- TTY:启动进程的终端名称,不是从终端启动则显示“?”
- NI:nice值,优先级,负数表示优先级高,
- P:最后使用的CPU禁止多CPU环境下有意义
- %CPU:上次更新到现在CPU时间占用百分比
- TIME:进程使用CPU总时间
- TIME+:进程使用CPU时间总计单位:1/100秒
- %MEM:进程使用物理内存百分比
- VIRT:进程使用虚拟内存总量 单位KB VIRT=SWAP+RES
- SWA:进程使用虚拟内存中被换出的大小
- RES:进程使用的,未被换出的物理内存大小,RES=CODE+DATA
- CODE:可执行代码占用物理内存大小
- DATA:可执行代码以外的部分占用物理内存大小
- SHR:共享内存大小
- S:进程状态 D表示不可终端的睡眠, R表示运行, S表示睡眠,T表示跟踪/停止, Z表示僵尸进程
- TOP命令下还可以进一步执行,按f可进行列选择
- h:显示帮助信息
- K:终止一个进程
- q:推出
- c:切换显示命令和完整命令行
- M:根据主流内存大小进行排序
- P:更具CPU使用辈分比进行大小排序
- T:更具时间/累计时间进行排序
- 数字1:显示所有CPU负载情况
sar命令
- Linux 命令sar作用在周期性对内存和CPU使用情况进行采样基本语法:
sar [options] [<interval> [count]]
-
interval:采样周期 和 count:采样数量。option选项可以指定sar命令对那些性能数据进行采样
- -A:所有报告的总和
- -u:CPU利用率
- -d:IO情况
- -q:查看队列长度
- -r:内存使用统计信息
- -n:网络信息统计
- -o:采样结果输出到文件
-
以下案例统计CPU使用情况,每秒采样一次,共五次 sar -u 1 5

-
获取内存使用情况 sar -r 1 5
-
获取IO信息 sar -b 1 5
vmstat 命令
-
vmstat也是一个功能齐全的性能检测工具,统计CPU,内存使用情况,swap使用情况等信息,同样周期采样,格式雷同
-
vmstat 1 5 没秒一次共五次
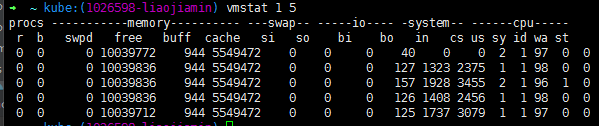
-
输出中各项意义:
- procs:
- r:等待运行的进程数
- b:处于非中断睡眠状态的进程数
- memory
- swpd:虚拟内存使用情况,单位KB
- free:空闲内存,单位KB
- buff:被用来最为呼延村的内存数,单位:KB
- swap
- si:从磁盘交换到内存的交换页数量,单位KB/秒
- so:从内存交换到磁盘的交换页数量,单位kb/秒
- io
- bi:发送到块设备的块数,单位:块/秒
- bo:从块设备接收到块数,单位:块/秒
- System
- in:每秒中断数,包括时钟中断
- cs:每秒上下文切换次数
- CPU
- us:用户CPU使用时间
- sy:内核CPU系统使用时间
- id:空闲时间
- procs:
-
总结:vmstat工具可以查看内存,交互分区,IO操作,上下文切换,时钟中断以及CPU的使用情况
iostat命令
-
iostat可以提供详细的IO信息,基本使用也雷同上几个:iostat 1 5

-
以上命令每秒采样一次持续五次,展示了CPU使用和磁盘IO的信息,如果只需要磁盘IO信息iostat -d 1 5
-
-d标识输出磁盘使用情况,结果各参数含义如下:
- tps:该设备每秒传输次数
- KB_read/s:每秒从设备读取的数据量
- KB_wrtn/s:每秒向设备写入的数据量
- KB_read:读取的总数据量
- KB_wrtn:写入的总数据量
-
iostat可以快速定位系统是否产生了大量IO操作‘
pidstat工具
- pidstat是一个功能强大的性能监控工具,也是Sysstat组件之一,pidstat不仅可以监视进程性能,也可以监视线程的性能。
CPU使用监控
- 如下demo
public class HoldCPUMain {
public static class HoldCpuTesk implements Runnable{
@Override
public void run() {
while (true){
double a = Math.random()* Math.random();
}
}
}
public static class LazyTask implements Runnable{
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
new Thread(new HoldCpuTesk()).start();
new Thread(new LazyTask()).start();
new Thread(new LazyTask()).start();
new Thread(new LazyTask()).start();
}
}
-
以上demo中跑四个线程,其中一个占用CPU资源,其他空闲,先使用jps找出java程序的PID, 接着使用pidstat命令输出程序CPU使用情况, pidstat -p 1187 -u 1 3

-
如上图所示,我们先用jps找到Java程序的PID,然后pidstat命令输出CPU使用情况
-
pidstat参数 -p 用来指定进程ID,-u指定值需要CPU的信息,最后1,3表示每秒一次,打印三次,从输出看出,CPU占用最后能达到100%,idstat功能还可以监控线程信息,如下命令:
pidstat -p 1187 1 3 -u -t

- 参数解析: -t参数将系统性能的监控细化到线程级别。如上图中看,java引用程序之所以占用如此之高CPU,是因为线程1204的缘故。我们使用以下命令导出指定Java应用的所有线程:
jstack -l 1187 >/temp/thread.txt

- 如上图片信息,线程HoldCPUTask类他的nid(native ID)为0x4b4,转为10进制后 1024,
- 通过pidstat分析就很容易去获取到java应用程序中大量占用CPU的线程。
IO使用监控
-
磁盘也是常见性能瓶颈之一,pidstat也可以监控IO情况,如下排查流程:
-
top命令查看基础系统资源信息如下,可以看到如下图中PID=10580 的java进程占用VIRT(虚拟内存)%CPU(上次结束CPU占比)都居于第一,资源消耗厉害,
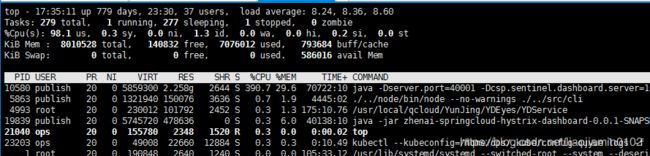
-
获取到pid后,用如下命令获取对应详细线程信息,如下图所示
pidstat -p 10580 -d -t 1 3

- 如下结果看出,进程10580中线程 10582,10583,10584,10585线程产生了大量IO操作,通过jstack命令来查一下10585线程,可以定位到具体的线程信息。
内存监控
- 使用pidstat命令还可以监控指定进程的内存使用情况,我们用如下命令,得出如下图中的结果:
pidstat -r -p 10580 1 5

- 输出结果中各列含义如下:
- minflt/s:该进程每秒minor faults(不需要从磁盘中调出内存页)的总数
- majflt/s:该进程每秒major faults(需要从磁盘中调出内存页)的总数
- VSZ:标识该进程使用的虚拟内存大小,单位KB
- RSS:标识该进程占用物理内存大小,单位KB
- %MEM:标识占用内存比率
- 如上图中可以看到,改进程占用虚拟内存5G, 占用物理内存3G,内存占用比率29.56%
总结pidstat是一款多合一工具,可以同时监控CPUI(-u),IO(-d),线程(-t),内存(-r),同时在定位具体线程的时候基本上可以找到出问题的点,方便引用程序的故障派查。
windows工具
- 最常用的Windows任务管理器
- perfmon性能监控工具:Windows下专业级的监控工具,并且windows中自带的一个工具,在“运行”对话宽中输入perfmon,或者控制面包中性能快捷方式都可以打开。
- Process Explorer:一个进程管理工具,可以替代Windows的任务管理器
- Pslist命令行:windows下的一个命令行工具,他可以显示进程乃至线程的详细信息,类似pidstat
JDK命令行工具
- 用的最多的java.exe,javac.exe,这些都在jdk的bin目录下面,所有的可执行文件的实现都在tools.jar中实现。
JPS命令
- jps类似linux下的ps命令,直接jps可以列出java程序的进程ID以及Main函数的名称
jiamindeMacBook-Pro:~ jiamin5$ jps
75712 AppMain
75664 RemoteMavenServer
75737 Jps
75711 Launcher
75454
- Jps还提供类一系列参数来指定输出内容
- -q:jps -q 只输出进程ID,不输出类的短名称
- -m:用于输出传递给Java进程(主函数)的参数
- -l:用于输出主函数的完整路径
- -v:可以显示传递给JVM的参数
jstat命令
- 一个可以用来观察java应用程序运行时信息的工具,功能强大,可以查看堆信息
jstat -<option> [-t] [-h<lines>] <vmid> [<interval>] [<coune>]
- Option可以由以下构成,
- class:显示ClassLoader相关信息
- compiler:显示JIT变异的相关信息
- gc:显示与GC相关的堆信息
- gccapacity:显示各个代的容量以及使用情况
- gccause:显示垃圾收集相关信息同-gcutil, 同时显示最后一次或当前正在发生的GC的诱发原因
- gcnew:显示新生代信息
- gcnewcapacity:显示新生代大小与使用情况
- gcold:显示老年代和永久代信息
- gcoldcapacity:显示老年代大小
- gcutil:显示垃圾收集信息
- printcompiliation:输出JIT变异的方法信息
- -t参数可以在输出信息前加timestamp列,
- interval用来指定统计数据周期
- count指定统计次数
- 如下案例
jstat -gccapacity -t 78305 1000 2 //显示各个代的容量以及使用情况,
jstat -class -t 78305 1000 2 //每一秒统一一次类加载信息,总共统计两次
jstat -gc -t 80800 1000 100 //打印堆内存各个区域使用情况,GC情况,如下输出:
Timestamp S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
89.9 512.0 512.0 0.0 496.0 1024.0 892.5 4096.0 40.0 4864.0 3194.5 512.0 353.9 1 0.001 0 0.000 0.001
90.9 512.0 512.0 0.0 496.0 1024.0 892.5 4096.0 40.0 4864.0 3194.5 512.0 353.9 1 0.001 0 0.000 0.001
91.9 512.0 512.0 0.0 496.0 1024.0 913.1 4096.0 40.0 4864.0 3194.5 512.0 353.9 1 0.001 0 0.000 0.001
- 以上含义从S0C开始依次为:
- s0C:s0from的大小
- S1C:s1from的大小
- S0U:s0from已使用空间
- S1U:s1from已使用空间
- EC:eden大小
- EU:eden区已使用空间
- OC:old区大小
- OU:old区已使用空间
- PC:永久代大小
- PU:永久代已使用空间
- YGC:新生代GC次数
- YGCT:新生代GC耗时
- FGC:fullGC次数
- FGCT:fullGC耗时
- GCT:GC总耗时
jinfo命令
- 用了查看正在运行的java应用程序的扩展参数,甚至支持运行是修改部分参数,语法
jinfo <option> <pid>
- option操作有如下:
- -flag:打印指定JVM参数值
jmap
- 生成java应用程序的堆快照和对象的统计信息。
- 通过jmap -histo 83009 >/Users/jiamin/s.txt 可以得到运行的java程序在内存中实例数量和合计
- 另外一个功能是生成当前堆快照:
- jmap -dump:format=b,file=/Users/jiamin/dump.hprof 83009 生成dump文件可以用visualVM查看,这个也是JDK自带的工具,上面有对应说明
jhat命令
- 用于分析java应用程序堆快照信息,上文中dump问及就可以用这个命令分析,如下:
jhat dump.hprof
jiamindeMacBook-Pro:~ jiamin5$ jhat dump.hprof
Reading from dump.hprof...
Dump file created Thu May 07 22:06:52 CST 2020
Snapshot read, resolving...
Resolving 13100 objects...
Chasing references, expect 2 dots..
Eliminating duplicate references..
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
- 如上运行后可以在Http://127.0.0.1:7000中看到结果信息

- 如上图中因为堆快照信息非常大,信息太多,jhat还支持使用OQL语句最下面Query Language功能,用来查询当前Java程序中所有java.io.File对象的路径如下:select file.path.value.toString() from java.io.FIle PutInEden
jstack命令
- 用于到处java引用程序的线程堆栈,语法如下
- jstck [-l]
- -l 选项用了答应锁的附加信息,jstack工具回在控制台输出程序中所有的锁信息,可以使用重定向将输出保存文件
jstack -l 83183 > /Users/jiamin/deadlock.txt
//死锁输出如下
Found one Java-level deadlock
。。。。。。
- jstack输出中很容易找到死锁信息,并同时显示发生死锁的两个线程以及死锁线程持有对象和等待对象,帮助开发人员解决死锁问题。
jstatd命令
-
之前都是本机java程序的监控,jstatd是远程监控,jstatd是一个RMI服务员端程序,相当于一个代理服务器,建立本地与被监控计算机的监控工具的通信,jstatd服务器将本机的java引用程序信息传递到远程计算机如下图:
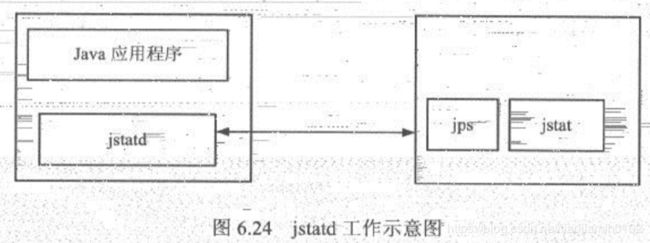
-
测试demo如下
public class HoldCPUMain {
public static class HoldCpuTesk implements Runnable{
@Override
public void run() {
while (true){
double a = Math.random()* Math.random();
}
}
}
public static class LazyTask implements Runnable{
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
new Thread(new HoldCpuTesk()).start();
new Thread(new LazyTask()).start();
new Thread(new LazyTask()).start();
new Thread(new LazyTask()).start();
}
}
hprof工具
- hprof也不是独立的监控工具,只是一个java agent工具,可以用于监控java应用程序运行时CPU信息和堆信息。使用java -agentlib:hprof=help可以查询hprof帮助文档
- 使用hprof可以查看程序中各个函数的CPU占用时间,
JConsole工具
- JDK自带的图形化性能监控工具,通过JConsole可以查看java引用程序的运行概况,监控堆内存,永久区,类加载等
JConsole连接java程序
- jdk的bin目录下运行jconsole.exe 就可以直接启动,在本地连接窗口选择需要监控的进程id就可以。
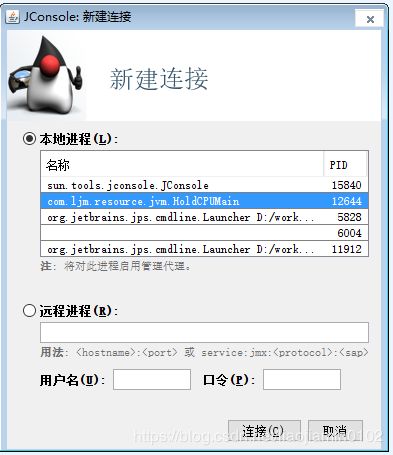
java程序概况
- 以下基本情况监控包括,堆内存,系统线程,类加载数量,CPU使用

内存监控
- 切换内存监控,JConsole对堆内存监控精确到每一个区域,包括eden,survivor,老年代,同时非堆区域的监控也存在。提供强制FullGC功能。
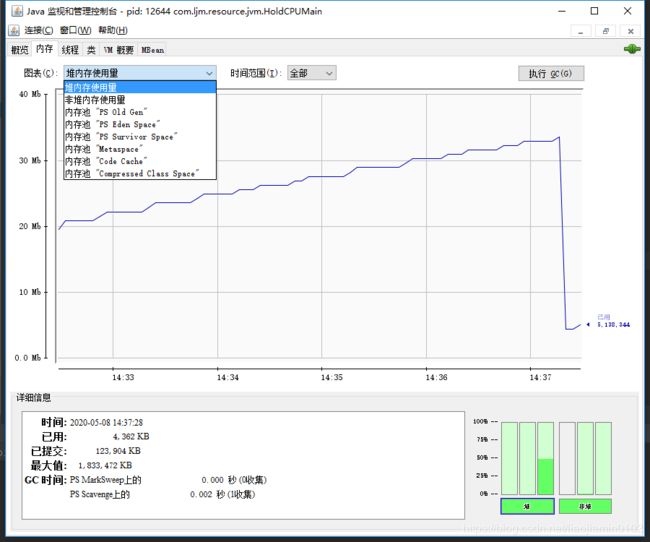
线程监控
- 还是上面所提到的demo代码,对应的线程监控,其中有Thread0,2,3,其中只有Thread-0是runable状态,其他是TIMED_WAITING,并且提供检测死锁按钮,可以很好帮助研发人员获取死锁信息。
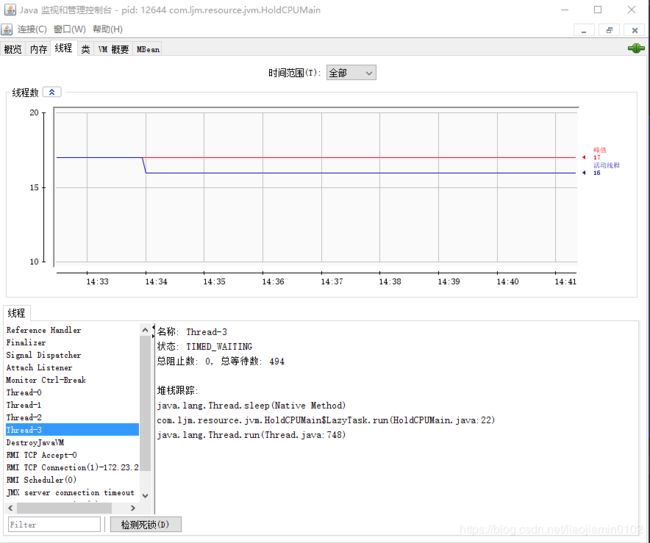
虚拟机监控
- 针对虚拟机的监控是对整体数据的一个监控,其中包括线程,堆,操作系统概况信息,包括虚拟机版本,类型等。
MBean管理
- MBean页面运行通过JConsole进行MBean的管理,包括查看或者设置MBean的属性,运行MBean的方法等。
使用插件
- 除了基本功能,JConsole还支持插件,JDK安装目录下就自带了一个插件,位于JAVA_HOME/demo/management/JTop下面,用如下命令启动,可以让JConsole加载插件并启动
jconsole -pluginpath %JAVA_HOME%/demo/management/JTop/JTop.jar
- 链接任意java程序,进入JTop页面,JTop插件按CPU占用时间排序
Visual VM 多合一工具
- Visual VM是一个多功能组合的性能监控可视化工具,集成了多种性能统计工具的功能,可以替代上面提到的:jstat,jmap,jhat,jstack,甚至JConsole在JDK6,7以后,VIsualVM作为JDK一部分发布,开源。
- VIsualVM 可以查询应用程序基本情况,比如进程ID, MainClass,启动参数等,
- Monitor页面可见CPU,堆,永久区,类加载,线程数的总体情况,可手动执行FullGC
- ThreadDump和分析,可一键生成当前堆内存ThreadDump,可以导出当前所有线程的堆栈信息
- 可以统计调用时长,但是无法给出调用堆栈,因此VisualVM还是无法确认一个函数被调用了多少次
- 右边菜单中HeapDump命令可以立刻获取当前内存快照进行分析
- MBean管理和JConsole是完全一样的。
TDA
- TDA是Thread Dump Analyzer的缩写,是一款线程快照分析工具,当使用jstack或者VisualVM等工具取得线程快照文件后,通过文本编辑器查看分析线程快照文件是一件困难的事情,而TDA办证分析线程,抓取快照,
BTrace介绍
- 略
MAT内存分析工具(这东西说是免费的)
- Memory analyzer的简称,一款功能强大的java堆内存分析工具,有类似VisualVM的功能,并且在堆内存的功能上更加详细
深堆浅堆
- 浅堆表示一个对象结构所占用堆内存大小
- 深堆表示一个对象被GC回收后可以真实释放的内存大小(或者说指只能通过该对象直接或者间接访问到的对象的浅堆只和)
- 如下案例解析:
public class Point {
private int x;
private int y;
public Point(int x, int y){
this.x = x;
this.y = y;
}
}
public class Line {
private Point startPoint;
private Point endPoint;
public Line(Point startPoint, Point endPoint){
this.startPoint = startPoint;
this.endPoint = endPoint;
}
public static void main(String[] args) {
Point a = new Point(0,0);
Point b = new Point(0,0);
Point c = new Point(0,0);
Point d = new Point(0,0);
Point e = new Point(0,0);
Point f = new Point(0,0);
Point g = new Point(0,0);
Line aLine = new Line(a,b);
Line bLine = new Line(a,c);
Line cLine = new Line(d,e);
Line dLine = new Line(f,g);
a=null;
b=null;
c=null;
d=null;
e=null;
}
}
-
如上demo中,引用关系如下图所示,其中a,b,c,d,e对象用完就被赋null
-
更加Point类结构,使用MAT得到内存快照得到每个point浅堆和深堆大小都是16字节
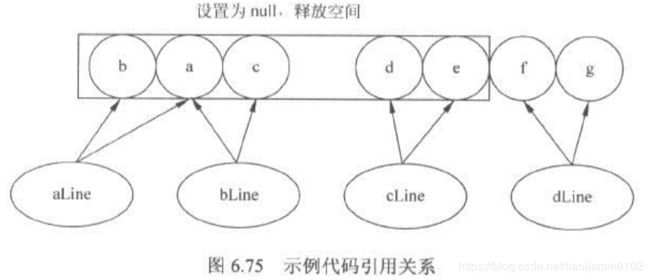
-
如上图引用dLine对象的两个点f,g,没有被null,引用不被回收所以dline被回收后f,g并不会被回收因此能释放的就是本身的16字节,所以深堆是16
-
cLine的d和e被赋值null,并且仅仅被Cline引用,所以cline被释放,d,e必然被释放所以深堆16*2+16=48
-
aLine和bLine两个均持有对方一个点,所以aLine被回收,只有b是只被aline引用所以b被回收,a因为还在bLine中被引用所以不被回收,深堆是16+16=32,bLine同理
垃圾回收根
- 在java系统中,作为GC的根节点可能是以下对象之一:
- 系统类:被bootstrap/system ClassLoader加载的类,如在rt.jar包中的所有类
- JNI局部变量:本地代码中局部变量,如,用户自定义的JNI代码或者JVM内部代码
- JNI全局变量:本地代码中全局变量
- 正在使用的锁:作为锁对象,比如掉了wait或者notify方法的对象,或调用了synchronized(Object)操作的对象
- java局部变量:如函数中输入参数以及方法中局部变量
- 本地栈:本地代码中输入输出参数。比如用户自定义的JNI代码或者JVM内部代码
- Finalizer:在等待队列中将要被执行析构函数的对象
- unfinalized:拥有析构函数,单没有被析构,且不再析构队列中的对象
- 不可达对象:从任何一个根对象,无法达到的对象,但为了能够在MAT中分析,被MAT标为根
- 未知对象:
最大对象报告
查找支配者
线程分析
集合使用情况分析
JProfile简介
- JProfile是一款商业化的软件,功能全面,主要有内存分享,CPU分享,线程分析,JVM性能信息收集等