解决ValueError: bad input shape (xxxx, x)
下面看一段机器学习代码:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import cross_val_score
iris=datasets.load_iris()
x_train,y_train,x_test,y_test = train_test_split(iris.data,iris.target,test_size=0.4,random_state=0)
clf=GaussianNB()
clf.fit(x_train,y_train)使用高斯朴素贝叶斯模型对鸢尾花数据集进行训练,但运行时出现以下问题:
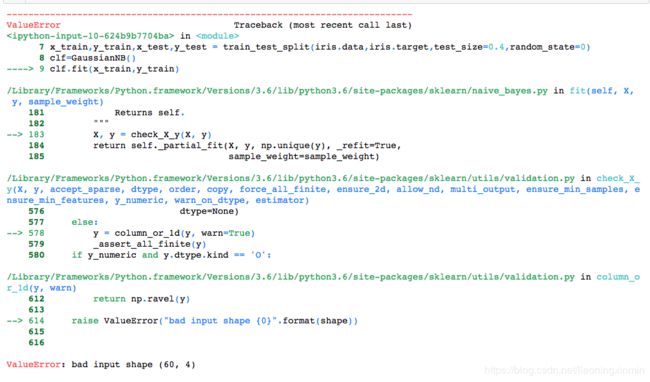
查看错误原因,提示为值错误,这个错误发生在模型训练位置,并且模型训练语句没有错误,那么就是传给模型训练的数据发生了错误(x_train,y_train)!!!我们返回去检查这两个数据集,发现使用train_test_split在分割数据集时,我们将数据集顺序写错了,正确的数据集顺序为:x_train,x_test,y_train,y_test,正是由于这个正确的顺序,才能分割正确的数据集与测试集,大部分人认为这个数据集没有顺序,下面看一下train_test_split的常规用法:
X_train,X_test, y_train, y_test =sklearn.model_selection.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
# train_data:所要划分的样本特征集
# train_target:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子。
因此千万不要忽略训练集与测试集的顺序!