用python操作浏览器的三种方式
第一种:selenium导入浏览器驱动,用get方法打开浏览器,例如:
import time
from selenium import webdriver
def mac():
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("http://huazhu.gag.com/mis/main.do")
第二种:通过导入python的标准库webbrowser打开浏览器,例如:
>>> import webbrowser
>>> webbrowser.open("C:\\Program Files\\Internet Explorer\\iexplore.exe")
True
>>> webbrowser.open("C:\\Program Files\\Internet Explorer\\iexplore.exe")
True
第三种:使用Splinter模块模块
一、Splinter的安装
Splinter的使用必修依靠Cython、lxml、selenium这三个软件。所以,安装前请提前安装
Cython、lxml、selenium。以下给出链接地址:
1)http://download.csdn.net/detail/feisan/4301293
2)http://code.google.com/p/pythonxy/wiki/AdditionalPlugins#Installation_no
3)http://pypi.python.org/pypi/selenium/2.25.0#downloads
4)http://splinter.cobrateam.info/
二、Splinter的使用
这里,我给出自动登录126邮箱的案例。难点是要找到页面的账户、密码、登录的页面元素,这里需要查看126邮箱登录页面的源码,才能找到相关控件的id.
例如:输入密码,密码的文本控件id是pwdInput.可以使用browser.find_by_id()方法定位到密码的文本框,
接着使用fill()方法,填写密码。至于模拟点击按钮,也是要先找到按钮控件的id,然后使用click()方法。
#coding=utf-8
import time
from splinter import Browser
def splinter(url):
browser = Browser()
#login 126 email websize
browser.visit(url)
#wait web element loading
time.sleep(5)
#fill in account and password
browser.find_by_id('idInput').fill('xxxxxx')
browser.find_by_id('pwdInput').fill('xxxxx')
#click the button of login
browser.find_by_id('loginBtn').click()
time.sleep(8)
#close the window of brower
browser.quit()
if __name__ == '__main__':
websize3 ='http://www.126.com'
splinter(websize3)
WebDriver简介
selenium从2.0开始集成了webdriver的API,提供了更简单,更简洁的编程接口。selenium webdriver的目标是提供一个设计良好的面向对象的API,提供了更好的支持进行web-app测试。从这篇博客开始,将学习使用如何使用python调用webdriver框架对浏览器进行一系列的操作
打开浏览器
在selenium+python自动化测试(一)–环境搭建中,运行了一个测试脚本,脚本内容如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
print(driver.title)
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.close()
webdriver是一个Web应用程序测试自动化工具,用来验证程序是否如预期的那样执行。
webdriver.Chrome():创建一个Chrome浏览器的webdriver实例
driver.get(“http://www.baidu.com“):打开”http://www.baidu.com“页面
driver.find_element_by_id(“kw”).send_keys(“selenium”)
找到id为“kw”的元素,在这个页面上为百度首页的搜索框,在其中输入“selenium”
driver.find_element_by_id(“su”).click():找到id为“su”的元素并点击,在这个页面上为百度首页的“百度一下”按钮
driver.close():退出浏览器
运行脚本的第一步是打开浏览器,使用webdriver.Chrome()打开谷歌浏览器,如果要指定其他浏览器,比如要使用Firefox或者IE浏览器,更换浏览器名称就可以了
driver = webdriver.Chrome() //打开Chrome浏览器
driver = webdriver.Firefox() //打开Firefox浏览器
driver = webdriver.Ie() //打开IE浏览器
第二步操作是打开页面,使用driver.get(url)方法来打开网页链接,例如脚本中打开百度首页
driver.get("http://www.baidu.com")
接下来是print(driver.title),使用driver.title获取当前页面的title,title就是在浏览器tab上显示的内容,例如百度首页的标题是“百度一下,你就知道”
浏览器前进后退
在当前页面打开一个新的链接后,如果想回退到前一个页面,使用如下driver.back(),相当于点击了浏览器的后退按钮
和back操作对应的是浏览器前进操作driver.forward(),相当于点击了浏览器的前进按钮
driver.back() //回到上一个页面
driver.forward() //切换到下一个页面
浏览器运行后,如果页面没有最大化,可以调用driver.maximize_window()将浏览器最大化,相当于点击了页面右上角的最大化按钮
driver.maximize_window() //浏览器窗口最大化
driver.set_window_size(800, 720) //设置窗口大小为800*720
浏览器截屏操作,参数是截屏的图片保存路径:
driver.get_screenshot_as_file("D:/data/test.png") 屏幕截图保存为***
driver.refresh() //重新加载页面,页面刷新
在测试脚本运行完后,一般会在最后关闭浏览器,有两种方法关闭浏览器,close()方法用于关闭当前页面,quit()方法关闭所有和当前测试有关的浏览器窗口
driver.close() //关闭当前页面
driver.quit() //关闭所有由当前测试脚本打开的页面
页面元素定位
要定位页面元素,需要找到页面的源码。
IE浏览器中,打开页面后,在页面上点击鼠标右键,会有“查看源代码”的选项,点击后就会进入页面源码页面,在这里就可以找到页面的所有元素
使用Chrome浏览器打开页面后,在浏览器的地址栏右侧有一个图标,点击这个图标后,会出现许多菜单项,选择更多工具里的开发者工具,就会出现页面的源码,不同版本的浏览器菜单选项可能不同,但是都会在开发者工具里找到页面的源码
Firefox浏览器打开页面后,在右键菜单里也可以找到“查看页面源代码”的选项。在Firefox中,可以使用浏览器自带的插件查看定位元素,在Firefox的附加组件里搜索firebug进行下载,安装firebug组件后会在浏览器的工具栏中多出一个小虫子的图标,点击这个图标就可以打开组件查看页面源码,打开后如下图所示
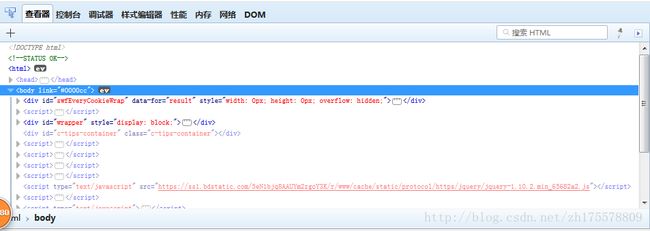
以百度首页搜索页面为例,看一下webdriver定位元素的八种方式
使用id定位
在页面源码中找到搜索输入框的元素定义
可以看到输入框有一个有一个id的属性,调用find_element_by_id()根据id属性来找到元素,参数为属性的值
input_search = driver.find_element_by_id("kw")
使用name定位
使用find_element_by_name()根据name属性找到元素,参数为name属性的值
搜索框有一个name=”wd”的属性,使用name查找搜索输入框元素
input_search = driver.find_element_by_name("wd")
使用className定位
使用find_element_by_class_name()根据className属性找到元素,参数为className属性的值
搜索框有一个class=”s_ipt”的属性,使用className查找元素
input_search = driver.find_element_by_class_name("s_ipt")
使用tagName定位
使用find_element_by_tag_name()根据tagName属性找到元素,参数为元素标签的名称
每个页面的元素都有一个tag,搜索框的标签为input,有时候一个页面里有许多相同的标签,所以用这种方法找到的元素一般都不准确,除非这个元素使用的标签在这个页面里是唯一的。一般不会使用这种方式来定位元素
input_search = driver.find_element_by_class_name("input")
使用link_text定位
页面上都会有一些文本链接,点击链接后会打开一个新的页面,这些可以点击的链接可以使用find_element_by_link_text来定位,百度首页上方有如下几个元素

例如要定位“新闻”,找到元素的代码,有一个href的属性,这是点击后打开的页面
新闻
使用link_text查找元素,参数为元素的文本信息
news = driver.find_element_by_link_text("新闻")
使用partial_link_text定位
这种方式类似于link_text的定位方式,如果一个元素的文本过长,不需要使用文本的所有信息,可以使用其中的部分文本就可以定位
使用partial_link_text查找百度首页的“新闻”元素,参数为文本信息,可以使用全部的文本,也可以使用部分文本
news = driver.find_element_by_link_text("新闻") //使用全部文本
news = driver.find_element_by_link_text("新") //使用部分文本
使用css selector定位
使用css属性定位元素有多种方法,可以使用元素的id、name、className,也可以使用元素的其他属性,如果一个元素没有上述的几种属性或者定位不到时,可以使用css来定位
还是使用百度搜索框的实例来说明css定位的用法
css使用元素的id定位
css属性使用id定位时,使用#号表示元素的id
input_search = driver.find_element_by_css_selector("#kw") //使用元素的id定位
css使用元素的class定位
css属性使用class定位时,使用.号表示元素的class
input_search = driver.find_element_by_css_selector(".s_ipt") //使用元素的class定位
css使用元素的tag定位
css属性使用tagName定位时,直接使用元素的标签
input_search = driver.find_element_by_css_selector("input") //使用元素的tagName定位
css使用元素的其他属性
除了上述3种属性,css属性可以使用元素的其他属性定位,格式如下
input_search = driver.find_element_by_css_selector("[maxlength='255']")
使用元素的maxlength属性定位
input_search = driver.find_element_by_css_selector("[autocomplete='off']")
使用元素的autocomplete属性定位
可以在参数中加入元素的标签名称
input_search = driver.find_element_by_css_selector("input#kw") //使用元素的id定位
input_search = driver.find_element_by_css_selector("input.s_ipt") //使用元素的class定位
driver.find_element_by_css_selector("input[maxlength='255']") //使用元素的maxlength属性定位
input_search = driver.find_element_by_css_selector("input[autocomplete='off']") //使用元素的autocomplete属性定位
css的层级定位
当一个元素使用自身的属性不容易定位时,可以通过它的父元素来找到它,如果父元素也不好定位,可以再通过上元素来定位,以此类推,一直找到容易定位的父元素为止,通过层级定位到需要查找的元素
通过Firefox的firebug组件查看百度首页的源码
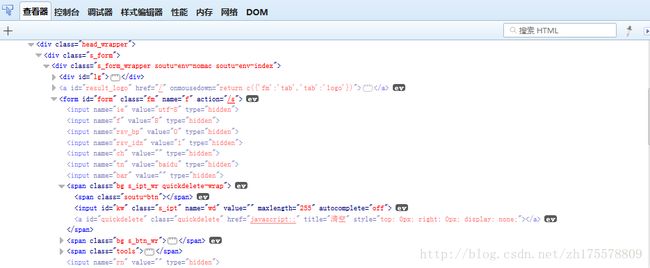
通过层级来定位搜索框
input_search = driver.find_element_by_css_selector("form#form>span:nth-child(1)>input")
input_search = driver.find_element_by_css_selector("form.fm>span:nth-child(1)>input")
搜索框的父元素为span标签,span的父元素为form,form有id和class属性,可以通过这两个属性来定位,找到form元素后,form下有多个span标签,所以要使用span:nth-child(1),表示form下的第一个span标签,这种用法很容易理解,表示第几个孩子,最后是span下的input标签,span下只有一个input,所以就可以定位到搜索框
css逻辑运算
用一个属性来定位元素时,如果有其他元素的属性和此元素重复,可以组合多个属性来功共同定位
组合多个属性定位元素定位百度搜索框
input_search = driver.find_element_by_css_selector("input[id='kw'][name='wd']")
在元素内定义的属性,都可以使用css来定位,使用其他几种方式无法定位到元素时,可以使用css,够强大!
使用xpath定位
XPath是一种在XML文档中定位元素的语言。因为HTML可以看做XML的一种实现,所以selenium用户可是使用这种强大语言在web应用中定位元素。xpath也可以通过元素的各种属性定位到元素
使用元素属性定位
input_search = driver.find_element_by_xpath("//*[@id='kw']") //通过元素id查找元素
input_search = driver.find_element_by_xpath("//*[@name='wd']") //通过元素name查找元素
input_search = driver.find_element_by_xpath("//*[@class='s_ipt']") //通过元素class查找元素
input_search = driver.find_element_by_xpath("//*[@maxlength='255']") //通过其他属性查找元素
input_search = driver.find_element_by_xpath("//*[@autocomplete='off']") //通过其他属性查找元素
前面的*号表示查找所有的标签元素,可以替换为标签名称,更准确的定位元素
input_search = driver.find_element_by_xpath("//input[@id='kw']") //通过元素id查找元素
input_search = driver.find_element_by_xpath("//input[@name='wd']") //通过元素name查找元素
input_search = driver.find_element_by_xpath("//input[@class='s_ipt']") //通过元素class查找元素
input_search = driver.find_element_by_xpath("//input[@maxlength='255']") //通过其他属性查找元素
input_search = driver.find_element_by_xpath("//input[@autocomplete='off']") //通过其他属性查找元素
xpath也可以通过层级来定位,定位方式
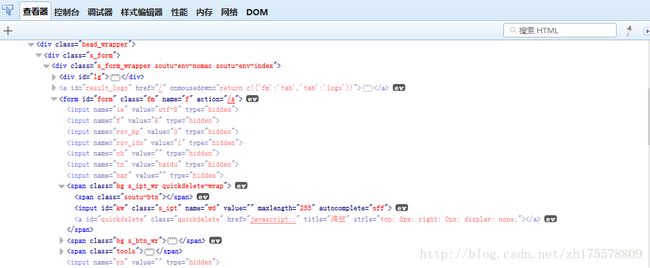
input_search =driver.find_element_by_xpath("//input[@id='form']//span[1]//input")
driver.find_element_by_xpath("//input[@class='fm']//span[1]//input")
查找效果和通过css的层级定位是相同的,意思是form元素下面的第一个span元素的input标签子元素
xpath的逻辑元素通过 and运算符 来组合元素属性
input_search = driver.find_element_by_xpath("//input[@id='kw' and name='wd']")
属性匹配
xpath中还有一种更强大的定位方式,通过模糊匹配元素的属性
news = driver.find_element_by_xpath("//a[contains(text(), '新闻')]")
查找text中包含"新闻"的元素
input_search = driver.find_element_by_xpath("//input[contains(@id, 'kw']")
查找id中包含"kw"的元素
input_search = driver.find_element_by_xpath("//input[starts-with(@id, 'k']")
查找id以"k"开头的元素
input_search = driver.find_element_by_xpath("//input[ends-with(@id, 'w']")
查找id以"w"结尾的元素
input_search = driver.find_element_by_xpath("//input[matchs(@id, 'k*']")
利用正则表达式查找元素
上面介绍了查找页面元素的八种方法,通过这些方式找到的都是单个元素,如果需要批量查找元素,还有和上面方式对应的八种复数形式
find_elements_by_id
find_elements_by_name
find_elements_by_class_name
find_elements_by_tag_name
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_css_selector
find_elements_by_xpath
这8种方法查找到的是一组元素,返回的是list,可以通过索引来操作元素
例如页面上的复选框和单选框,或者页面上有多个属相相同的输入框,这些属性相同的一组元素,可以批量获取,然后过滤出需要操作的元素,选择其中的一个或者多个进行操作
通过百度首页搜索“selenium”关键字,会出现许多搜索结果,这些搜索结果具有相同的属性,不同的是属性的值不同,定位这些元素时,可以使用批量定位的方法
看下面的代码
 这是搜索selenium关键字后的页面结果,每一个搜索结果都是可点击的链接,定位这些元素的方法:
这是搜索selenium关键字后的页面结果,每一个搜索结果都是可点击的链接,定位这些元素的方法:
search_results = driver.find_elements_by_css_selector("h.t>a")
search_results[3].click() //通过索引点击第4条搜索结果
第二个例子
checkbox
checkbox1
checkbox2
checkbox3
这个页面上有3个复选框,打开后如下图所示:
操作复选框
//查找所有的复选框并点击
checkboxs = driver.find_element_by_xpath('input[@type="checkbox"]')
返回一个list
for checkbox in checkboxs:
checkbox.click()
//点击最后一个复选框
checkboxs[2].click()
from selenium import webdriver
driver=webdriver.Firefox()
driver.get(r'http://www.baidu.com/')
print 'driver attributes:'
print dir(driver)
elem=driver.find_element_by_id('kw')
print 'WebElement attributes:'
print dir(elem)
浏览器属性:
driver attributes:
['NATIVE_EVENTS_ALLOWED', '__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_file_detector', '_is_remote', '_mobile', '_switch_to', '_unwrap_value', '_wrap_value', 'add_cookie', 'application_cache', 'back', 'binary', 'capabilities', 'close', 'command_executor', 'create_web_element', 'current_url', 'current_window_handle', 'delete_all_cookies', 'delete_cookie', 'desired_capabilities', 'error_handler', 'execute', 'execute_async_script', 'execute_script', 'file_detector', 'find_element', 'find_element_by_class_name', 'find_element_by_css_selector', 'find_element_by_id', 'find_element_by_link_text', 'find_element_by_name', 'find_element_by_partial_link_text', 'find_element_by_tag_name', 'find_element_by_xpath', 'find_elements', 'find_elements_by_class_name', 'find_elements_by_css_selector', 'find_elements_by_id', 'find_elements_by_link_text', 'find_elements_by_name', 'find_elements_by_partial_link_text', 'find_elements_by_tag_name', 'find_elements_by_xpath', 'firefox_profile', 'forward', 'get', 'get_cookie', 'get_cookies', 'get_log', 'get_screenshot_as_base64', 'get_screenshot_as_file', 'get_screenshot_as_png', 'get_window_position', 'get_window_size', 'implicitly_wait', 'log_types', 'maximize_window', 'mobile', 'name', 'orientation', 'page_source', 'profile', 'quit', 'refresh', 'save_screenshot', 'session_id', 'set_page_load_timeout', 'set_script_timeout', 'set_window_position', 'set_window_size', 'start_client', 'start_session', 'stop_client', 'switch_to', 'switch_to_active_element', 'switch_to_alert', 'switch_to_default_content', 'switch_to_frame', 'switch_to_window', 'title', 'w3c', 'window_handles']
调用说明:
driver.属性值
变量说明:
1.driver.current_url:用于获得当前页面的URL
2.driver.title:用于获取当前页面的标题
3.driver.page_source:用于获取页面html源代码
4.driver.current_window_handle:用于获取当前窗口句柄
5.driver.window_handles:用于获取所有窗口句柄
函数说明:
1.driver.find_element*():定位元素,
2.driver.get(url):浏览器加载url。
实例:driver.get("http//:www.baidu.com")
3.driver.forward():浏览器向前(点击向前按钮)。
4.driver.back():浏览器向后(点击向后按钮)。
5.driver.refresh():浏览器刷新(点击刷新按钮)。
6.driver.close():关闭当前窗口,或最后打开的窗口。
7.driver.quit():关闭所有关联窗口,并且安全关闭session。
8.driver.maximize_window():最大化浏览器窗口。
9.driver.set_window_size(宽,高):设置浏览器窗口大小。
10.driver.get_window_size():获取当前窗口的长和宽。
11.driver.get_window_position():获取当前窗口坐标。
12.driver.get_screenshot_as_file(filename):截取当前窗口。
实例:driver.get_screenshot_as_file('D:/selenium/image/baidu.jpg')
13.driver.implicitly_wait(秒):隐式等待,通过一定的时长等待页面上某一元素加载完成。
若提前定位到元素,则继续执行。若超过时间未加载出,则抛出NoSuchElementException异常。
实例:driver.implicitly_wait(10) #等待10秒
14.driver.switch_to_frame(id或name属性值):切换到新表单(同一窗口)。若无id或属性值,可先通过xpath定位到iframe,再将值传给switch_to_frame()
15.driver.switch_to.parent_content():跳出当前一级表单。该方法默认对应于离它最近的switch_to.frame()方法。
16.driver.switch_to.default_content():跳回最外层的页面。
17.driver.switch_to_window(窗口句柄):切换到新窗口。
18.driver.switch_to.window(窗口句柄):切换到新窗口。
19.driver.switch_to_alert():警告框处理。处理JavaScript所生成的alert,confirm,prompt.
20.driver.switch_to.alert():警告框处理。
21.driver.execute_script(js):调用js。
22.driver.get_cookies():获取当前会话所有cookie信息。
23.driver.get_cookie(cookie_name):返回字典的key为“cookie_name”的cookie信息。
实例:driver.get_cookie("NET_SessionId")
24.driver.add_cookie(cookie_dict):添加cookie。“cookie_dict”指字典对象,必须有name和value值。
25.driver.delete_cookie(name,optionsString):删除cookie信息。
26.driver.delete_all_cookies():删除所有cookie信息。
页面元素属性:
WebElement attributes:
['__class__', '__delattr__', '__dict__', '__doc__', '__eq__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_execute', '_id', '_parent', '_upload', '_w3c', 'clear', 'click', 'find_element', 'find_element_by_class_name', 'find_element_by_css_selector', 'find_element_by_id', 'find_element_by_link_text', 'find_element_by_name', 'find_element_by_partial_link_text', 'find_element_by_tag_name', 'find_element_by_xpath', 'find_elements', 'find_elements_by_class_name', 'find_elements_by_css_selector', 'find_elements_by_id', 'find_elements_by_link_text', 'find_elements_by_name', 'find_elements_by_partial_link_text', 'find_elements_by_tag_name', 'find_elements_by_xpath', 'get_attribute', 'id', 'is_displayed', 'is_enabled', 'is_selected', 'location', 'location_once_scrolled_into_view', 'parent', 'rect', 'screenshot', 'screenshot_as_base64', 'screenshot_as_png', 'send_keys', 'size', 'submit', 'tag_name', 'text', 'value_of_css_property']
调用说明:
driver.find_element*.属性值
或
element=driver.find_element*
element.属性值
变量说明:
1.element.size:获取元素的尺寸。
2.element.text:获取元素的文本。
3.element.tag_name:获取标签名称。
函数说明:
1.element.clear():清除文本。
2.element.send_keys(value):输入文字或键盘按键(需导入Keys模块)。
3.element.click():单击元素。
4.element.get_attribute(name):获得属性值
5.element.is_displayed():返回元素结果是否可见(True 或 False)
6.element.is_selected():返回元素结果是否被选中(True 或 False)
7.element.find_element*():定位元素,用于二次定位。
网页自动化最基本的要求就是要定位到各个元素,然后才能对该元素进行各种操作(输入,点击,清除,提交等)。
以百度搜索输入框为例,具体说明各个定位方式的用法:
(通过chrome浏览器查看元素或者搜狐浏览器的firebug查看,即可看到html源码)
注意点:第三行的元素是灰色的,该元素是不可定位到的,下方会说明。
1
2
3
4
5
6
7
8
1.通过id定位元素
如果id不是动态的,一个页面的id是唯一的。最简单的定位方式。
使用:find_element_by_id("id_vaule")
实例:find_element_by_id("kw")
注意点:有些id值是动态变化的,则不能使用该方法定位。如下:id就是动态的,每次进入页面,该id都会改变
邮箱帐号或手机号
2.通过class_name定位元素
classname有可能重复哦。
使用:find_element_by_class_name("class_name_vaule")
实例:find_element_by_class_name("s_ipt")
3.通过tag_name定位元素
标签名字最容易重复,不过,当定位一组数据时,可使用。
使用:find_element_by_tag_name("tag_name_vaule")
实例:find_element_by_tag_name("input")
注意点:当定位一组元素时:可勾选一组复选框。如下:
find_element_by_tag_name("input")

checkbox
checkbox1
checkbox2
checkbox3
4.通过name定位元素
name有可能会重复哦。
使用:find_element_by_name("name_vaule")
实例:find_element_by_name("wd")
5.通过link文字精确定位元素
登录
使用:find_element_by_link_text("text_vaule")
实例:find_element_by_link_text("登录")
6.通过link文字模糊定位元素
使用:find_element_by_partial_link_text("部分text_vaule")
实例:find_element_by_partial_link_text("登")
7.通过CSS定位元素
CSS(Cascading Style Sheets)是一种语言,它用来描述HTML和XML文档的表现。CSS可以较为灵活的选择控件的任意属性,一般情况下会比XPath快。且语法也比较简洁。
使用:find_element_by_css_selector("CSS")
实例:
7.1通过id属性定位元素
#号表示通过id属性来定位元素
find_element_by_css_selector("#kw")
7.2通过class属性定位元素
.号表示通过class属性来定位元素
find_element_by_css_selector(".s_ipt")
7.3通过标签名定位元素
find_element_by_css_selector("input")
7.4通过属性定位元素(挺常用的)
find_element_by_css_selector("[name='wd']")
find_element_by_css_selector("[maxlength='255']")
属性值包含某个值
属性值包含wd:适用于由空格分隔的属性值。
find_element_by_css_selector("[name~='wd']")
7.5父子定位元素
查找有父亲元素的标签名为span,它的所有标签名叫input的子元素
find_element_by_css_selector("span>input")
7.6组合定位元素
标签名#id属性值:指的是该input标签下id属性为kw的元素
find_element_by_css_selector("input#kw")
标签名.class属性值:指的是该input标签下class属性为s_ipt的元素
find_element_by_css_selector("input.s_ipt")
标签名[属性=’属性值‘]:指的是该input标签下name属性为wd的元素
find_element_by_css_selector("input[name='wd']")
父元素标签名>标签名.class属性值:指的是span下的input标签下class属性为s_ipt的元素
find_element_by_css_selector("span>input.s_ipt")
多个属性组合定位元素(挺常用的)
指的是input标签下id属性为kw且name属性为wd的元素
find_element_by_css_selector("input.s_ipt[name='wd']")
指的是input标签下name属性为wd且maxlength为255的元素
find_element_by_css_selector("input[name='wd'][maxlength='255']")
8.通过XPath定位元素
XPath是一种XML文档中定位元素的语言。该定位方式也是比较常用的定位方式。
使用:find_element_by_xpath("XPath")
8.1通过属性定位元素
find_element_by_xpath("//标签名[@属性='属性值']")
id属性:find_element_by_xpath("//input[@id='kw']")
class属性:find_element_by_xpath("//input[@class='s_ipt']")
name属性:find_element_by_xpath("//input[@name='wd']")
maxlength属性:find_element_by_xpath("//input[@maxlength='255']")
8.2通过标签名定位元素
指所有input标签元素 find_element_by_xpath("//input")
8.3父子定位元素
查找有父亲元素的标签名为span,它的所有标签名叫input的子元素
find_element_by_xpath("//span/input")
8.4根据元素内容定位元素(非常实用)
find_element_by_xpath("//p[contains(text(),'京公网')]")
京公网安备11000002000001号
注:contains的另一种用法
//input[contains(@class,'s')] 说明class属性包含s的元素。
8.5组合定位元素
//父元素标签名/标签名的属性值:指的是span下的input标签下class属性为s_ipt的元素
find_element_by_xpath("//span/input[@class='s_ipt']")
多个属性组合定位(挺常用的)
指的是input标签下id属性为kw且name属性为wd的元素
find_element_by_xpath("//input[@class='s_ipt' and @name='wd']")
指的是p标签下内容包含“京公网”且id属性为jgwab的元素
find_element_by_xpath("//p[contains(text(),'京公网') and @id='jgwab']")
比较懒惰的方法:
使用搜狐浏览器的firebug工具,复制XPath路径,不过这种方式对层级要求高,到时候自己再修改下。
9.通过By定位元素
使用:find_element(定位的类型,具体定位方式)
定位的类型包括By.ID,By.NAME,By.CLASS_NAME,By.TAG_NAME,By.LINK_TEXT,By.PARTIAL_LINK_TEXT,By.XPATH,By.CSS_SELECTOR
具体定位方式参考上方1-8的说明。
实例:find_element(By.ID,'kw')
注意:使用By定位方式,需先导入By类。
from selenium.webdriver.common.by import By
10.具体实例说明
下方例子是登陆126邮件,然后发送邮件。
1 # coding=utf-8
2 '''
3 Created on 2016-7-27
4 @author: Jennifer
5 Project:发送邮件
6 '''
7 from selenium import webdriver
8 import time
9
10 from test_5_2_public import Login #由于公共模块文件命名为test_5_2_public
11 driver=webdriver.Firefox()
12 driver.implicitly_wait(30)
13 driver.get(r'http://www.126.com/') #字符串加r,防止转义。
14 time.sleep(3)
15 driver.switch_to.frame('x-URS-iframe')
16 #调用登录模块
17 Login().user_login(driver)
18 time.sleep(10)
19 #发送邮件
20 #点击发件箱
21 #_mail_component_61_61是动态id,所以不能用于定位
22 #driver.find_element_by_css_selector('#_mail_component_61_61>span.oz0').click()
23 #不能加u"//span[contains(text(),u'写 信')]",否则定位不到。
24 #以下定位是查找span标签有个文本(text)包含(contains)'写 信' 的元素,该定位方法重要
25 driver.find_element_by_xpath("//span[contains(text(),'写 信')]").click()
26 #填写收件人
27 #driver.find_element_by_class_name('nui-editableAddr-ipt').send_keys(r'[email protected]')
28 driver.find_element_by_class_name('nui-editableAddr-ipt').send_keys(r'[email protected]')
29 #填写主题
30 #通过and连接更多的属性来唯一地标志一个元素
31 driver.find_element_by_xpath("//input[@class='nui-ipt-input' and @maxlength='256']").send_keys(u'自动化测试')
32 #填写正文
33 #通过switch_to_frame()将当前定位切换到frame/iframe表单的内嵌页面中
34 driver.switch_to_frame(driver.find_element_by_class_name('APP-editor-iframe'))
35 #在内嵌页面中定位邮件内容位置
36 emailcontext=driver.find_element_by_class_name('nui-scroll')
37 #填写邮件内容
38 emailcontext.send_keys(u'这是第一封自动化测试邮件')
39 #通过switch_to().default_content()跳回最外层的页面
40 #注:不要写成switch_to().default_content(),否则报AttributeError: SwitchTo instance has no __call__ method
41 driver.switch_to.default_content()
42 #driver.switch_to.parent_frame()
43 #点击发送
44 time.sleep(3)
45 #有可能存在元素不可见(查看元素是灰色的),会报ElementNotVisibleException错误
46 #包含发送二字的元素很多,所以还得再加上其他限制
47 #sendemails=driver.find_element_by_xpath("//span[contains(text(),'发送')]")
48 sendemails=driver.find_element_by_xpath("//span[contains(text(),'发送') and @class='nui-btn-text']")
49 time.sleep(3)
50
51 #校验邮件是否发送成功
52 try:
53 assert '发送成功' in driver.page_source
54 except AssertionError:
55 print '邮件发送成功'
56 else:
57 print '邮件发送失败'
58
59 #调用退出模块
60 Login().user_logout(driver)
元素定位说明:
1.代码22行,定位不到是因为id是动态的,所以需采取其他方式定位元素。
2.代码25行,是根据元素内容来定位的,具体用法详看8.4.
3.代码28行,是根据class名来定位元素的,由于该值在该页面上是唯一的,所以可以用它来定位。
4.代码31行,是使用逻辑运算符and连接更多的属性从而唯一的标志一个元素,具体用法详看8.5.
5.代码34行,由于使用内嵌的iframe框架,所以需要先使用switch_to_frame()移到该表单上,才能定位该表单上的元素,非常重要,否则无论怎么定位都会报“NoSuchElementException”,找不到该元素。
6.代码41行,跳出iframe框架,当框架内的动作操作完毕后,需要使用switch_to.default_content跳出iframe框架,非常重要。
7.代码47行,由于内容包括“发送”的元素中包含不可见元素(html查看元素可以看到此行是灰色的),这样有可能定位到不可见元素,会报“ElementNotVisibleException”。
8.代码48行,是使用逻辑运算符and连接更多的属性从而唯一的标志一个元素,具体用法详看8.5.这样可以排除掉那个不可见元素。
1.Frame/Iframe原因定位不到元素:
这个是最常见的原因,首先要理解下frame的实质,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,对那个页面里的元素进行定位。
解决方案:
如果iframe有name或id的话,直接使用switch_to_frame("name值")或switch_to_frame("id值")。
如下:
driver=webdriver.Firefox()
driver.get(r'http://www.126.com/')
driver.switch_to_frame('x-URS-iframe') #需先跳转到iframe框架
username=driver.find_element_by_name('email')
username.clear()
如果iframe没有name或id的话,则可以通过下面的方式定位:
#先定位到iframe
elementi= driver.find_element_by_class_name('APP-editor-iframe')
#再将定位对象传给switch_to_frame()方法
driver.switch_to_frame(elementi)
如果完成操作后,
可以通过switch_to.parent_content()方法跳出当前iframe,或者还可以通过switch_to.default_content()方法跳回最外层的页面。
2.Xpath描述错误原因:
由于Xpath层级太复杂,容易犯错。但是该定位方式能够有效定位绝大部分的元素,建议掌握。
解决方案:
2.1可以使用Firefox的firePath,复制xpath路径。该方式容易因为层级改变而需要重新编写过xpath路径,不建议使用,初学者可以先复制路径,然后尝试去修改它。
2.2提高下写xpath的水平。
如何检验编写的Xpath是否正确?编写好Xpath路径,可以直接复制到搜狐浏览器的firebug查看html源码,通过Xpath搜索:如下红色框,若无报错,则说明编写的Xpath路径没错。
find_element_by_xpath("//input[@id='kw']")
3.页面还没有加载出来,就对页面上的元素进行的操作:
这种情况一般说来,可以设置等待,等待页面显示之后再操作,这与人手工操作的原理一样:
3.1设置等待时间;缺点是需要设置较长的等待时间,案例多了测试就很慢;
3.2设置等待页面的某个元素出现,比如一个文本、一个输入框都可以,一旦指定的元素出现,就可以做操作。
3.3在调试的过程中可以把页面的html代码打印出来,以便分析。
解决方案:
导入时间模块。
import time
time.sleep(3)
4.动态id定位不到元素:
解决方案:
如果发现是动态id,直接用xpath定位或其他方式定位。 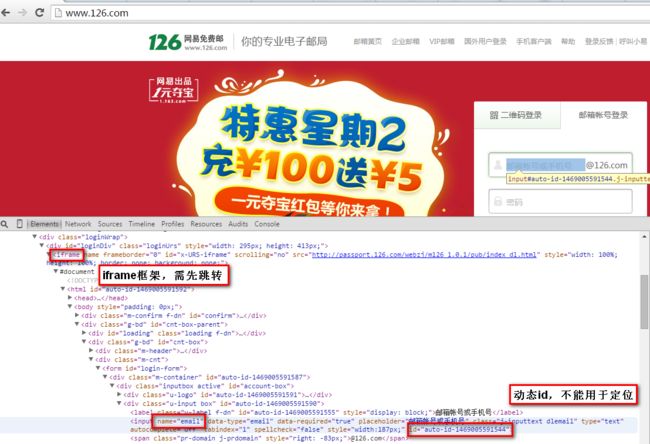
5.二次定位,如弹出框登录
如百度登录弹出框登录百度账号,需先定位到百度弹出框,然后再定位到用户名密码登录。
# coding=utf-8
'''
Created on 2016-7-20
@author: Jennifer
Project:登录百度账号
'''
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("http://www.baidu.com/")
time.sleep(3)
#点击登录:有些name为tj_login的元素为不可见的,点击可见的那个登录按钮即可。
#否则会报:ElementNotVisibleException
element0=driver.find_elements_by_name("tj_login")
for ele0 in element0:
if ele0.is_displayed():
ele0.click()
#在登录弹出框,需先定位到登录弹出框
#否则会报:NoSuchElementException
element1=driver.find_element_by_class_name("tang-content")
element11=element1.find_element_by_id("TANGRAM__PSP_8__userName")
element11.clear()
element11.send_keys("登录名")
element2=element1.find_element_by_id("TANGRAM__PSP_8__password")
element2.clear()
element2.send_keys("密码")
element3=element1.find_element_by_id("TANGRAM__PSP_8__submit")
element3.click()
element3.submit()
try:
assert "登录名" in driver.page_source
except AssertionError:
print "登录失败"
else:
print "登录成功"
time.sleep(3)
finally:
print "测试记录:已测试"
driver.close()
6.不可见元素定位
如上百度登录代码,通过名称为tj_login查找的登录元素,有些是不可见的,所以加一个循环判断,找到可见元素(is_displayed())点击登录即可。
转自 http://www.cnblogs.com/yufeihlf/p/5717291.html#test0
转自 http://blog.csdn.net/zh175578809/article/details/76376838
转自 https://blog.csdn.net/chengxuyuanyonghu/article/details/79154468