利用PFLD算法模型和flask搭建的人脸检测项目
最近做的人脸检测项目,模型用PFLD算法,利用flask框架搭建的工程,用post接口请求,接收base64图片数据。环境依赖为:
python3.6、redis: 统一缓存、opencv 4.1、flask 、pytorch、gunicorn、meinheld。
1.接口说明:
版本: 1.0
描述:传入base64编码的二进制图片数据,进行人脸关键点检测
请求方式:post
请求链接:XXXXXXXXX/ai/v1/FaceLandmarkDetect
图片要求:
图片格式:JPG(JPEG),PNG
图片像素尺寸:最小 200*200 像素,最大 2048*2048像素
2.接口设计:
接口请求参数:
| 参数名 |
必选 |
类型 |
说明 |
|---|---|---|---|
|
是 |
String | 图片的base64值 |
| requestId | 是 | String | 用于区分每一次请求的唯一的字符串id |
| token | 是 | String | 服务鉴权标识,AI组统一分配 |
| userId | 否 | String | 用户id |
接口返回结果示例:
{
"code": 0,
"msg": "success",
"data": {
"requestId": "100022" ,
"faceLandmarkRes": {'0': {'x': 65, 'y': 187}, '1': {'x': 68, 'y': 213}, '2': {'x': 70, 'y': 242}, '3': {'x': 72, 'y': 273}, '4': {'x': 74, 'y': 297}, ....}
}
}WFLW数据人脸关键点信息Landmark说明(98点)如下: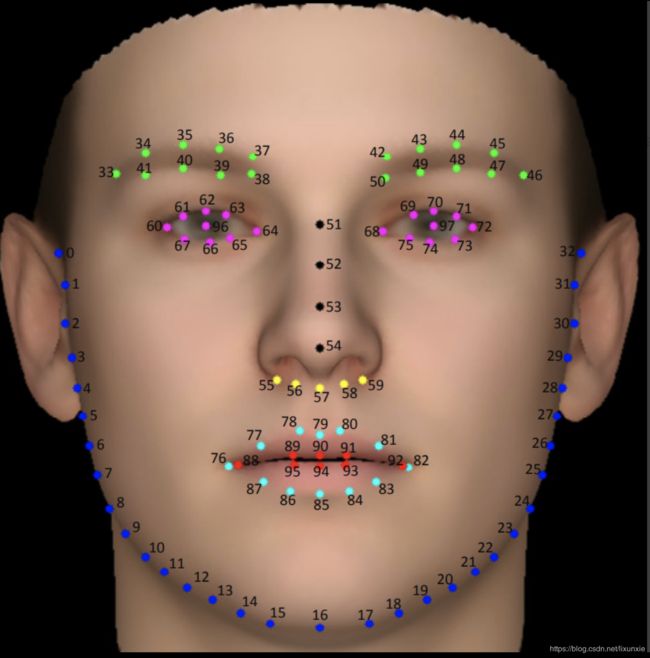
接口返回参数说明:
| 参数名 |
类型 |
说明 |
|---|---|---|
| 参数名 |
类型 |
说明 |
|
String | 用户请求唯一表示 |
|
Object | 检测出的人脸关键点信息的坐标数组 注:如果没有检测出人脸则为空数组 |
|
Int | 整个请求所花费的时间,单位为毫秒 |
接口状态码code:
| 状态码 |
状态说明 |
|---|---|
| 0 | 成功 |
| 2 | 未检测出人脸 |
| 3 | 鉴权失败 |
| 4 | 参数无效 |
| 5 | 图片尺寸不符合超出范围 |
| 6 | 请求异常 |
结果示例如下:
代码如下:
# encoding:utf-8
from meinheld import server
import numpy as np
import cv2
import time
import logging
from logging.handlers import TimedRotatingFileHandler
import json
import base64
from conf import config
from app.FaceLandmarkModel import FaceLandmarkModel
from flask import Flask, request
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
app = Flask(__name__)
model_path = "./checkpoint/snapshot/checkpoint_epoch_1000.pth.tar"
faceLandMark = FaceLandmarkModel(model_path)
def setLog():
log_fmt = '%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s'
formatter = logging.Formatter(log_fmt)
fh = TimedRotatingFileHandler(
filename="log/run_facelandmark_server" + str(time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())) + ".log",
when="H", interval=1,
backupCount=72)
fh.setFormatter(formatter)
logging.basicConfig(level=logging.INFO)
log = logging.getLogger()
log.addHandler(fh)
setLog()
@app.route('/ai/v1/FaceLandmarkDetect', methods=['POST'])
def faceLandMarkPredictMethod():
try:
start_time = time.time()
resParm = request.data
# 转字符串
resParm = str(resParm, encoding="utf-8")
resParm = eval(resParm)
requestId = resParm.get('requestId')
# 服务鉴权
token = resParm.get('token')
if not token:
res = {'code': 3, 'msg': 'token fail'}
logging.error("code: 3 msg: token fail ")
return json.dumps(res)
# 按照debase64进行处理
modelImg_base64 = resParm.get("inputImage")
if not modelImg_base64:
res = {'code': 4, 'msg': ' picture param invalid'}
logging.error("code: 4 msg: picture param invalid")
return json.dumps(res)
modelImg = base64.b64decode(modelImg_base64)
recv_time = time.time()
logging.info(f"recv image cost time: {str(recv_time - start_time)}")
modelImg_data = np.fromstring(modelImg, np.uint8)
modelImg_data_1 = cv2.imdecode(modelImg_data, cv2.IMREAD_COLOR)
cv2.imwrite("modelImg.jpg", modelImg_data_1)
# 判定图片尺寸
if modelImg_data_1.shape[0] > config.size or modelImg_data_1.shape[1] > config.size :
res = {'code': 5, 'msg': ' picture size invalid'}
logging.error("code: 5 msg: picture size invalid")
return json.dumps(res)
logging.info(f" modelImg_data_1 shape: {str(modelImg_data_1.shape)} size: {str(modelImg_data_1.size)}")
time_predict = time.time()
landMark = faceLandMark.faceLandMarkDetect(modelImg_data_1)
logging.info(f"landmarkDetect predict cost Time is: {str(time.time() - time_predict)} ")
logging.info(f"the landmark points is: {str(landMark)}")
if landMark is None or len(landMark) < 1:
data = {'requestId': requestId, 'faceLandmarkRes': {}, 'timeUsed': str(time.time() - start_time)}
res = {'code': 2, 'msg': 'not detect faces', 'data': data}
logging.error("code: 2 msg: landmarkDetect except, not detect faces")
return json.dumps(res)
landMarkDict = {}
for i, point in enumerate(landMark):
landMarkDict[str(i)] = {"x": int(point[0]), "y": int(point[1])}
timeUsed = time.time() - start_time
data = {'requestId': requestId, 'faceLandmarkRes': landMarkDict, 'timeUsed': str(timeUsed)}
res = {'code': 0, 'msg': 'success', 'data': data}
logging.info(f"code:0 msg:success landmark Detection cost Time is: {str(timeUsed)} ")
return json.dumps(res)
except Exception as e:
logging.exception(e)
res = {'code': 6, 'msg': 'request exception'}
return json.dumps(res)
if __name__ == "__main__":
logging.info('Starting the server...')
server.listen(("0.0.0.0", 7775))
server.run(app)
# app.run(host='0.0.0.0', port=18885, threaded=True)
# landMark = faceLandMark.faceLandMarkDetect(img)
FaceLandmarkModel类如下,存于app下的FaceLandmarkModel.py# encoding: utf-8
import argparse
import time
import numpy as np
import torch
import torchvision
from torchvision import transforms
import cv2
import logging
from models.pfld import PFLDInference, AuxiliaryNet
from mtcnn.detector import detect_faces, show_bboxes
from mtcnn.FaceDetector import FaceDetector
class FaceLandmarkModel:
def __init__(self, modelPath):
self.model_path = modelPath
self.checkpoint = torch.load(self.model_path)
self.plfd_backbone = PFLDInference().cuda()
self.plfd_backbone.load_state_dict(self.checkpoint['plfd_backbone'])
self.plfd_backbone.eval()
self.plfd_backbone = self.plfd_backbone.cuda()
self.transform = transforms.Compose([transforms.ToTensor()])
self.detector = FaceDetector()
def faceLandMarkDetect(self, image):
height, width = image.shape[:2]
pre_landmark = []
pre_time1 = time.time()
bounding_boxes, landmarks = self.detector.detect_faces(image)
logging.info(f"detect_faces cost time: {str(time.time() - pre_time1)}")
logging.info(f"landmarks is: {str(landmarks)}")
logging.info(f"bounding_boxes is: {str(bounding_boxes)}")
if landmarks is None or len(landmarks) < 1 or bounding_boxes is None or len(bounding_boxes) < 1:
return pre_landmark
for box in bounding_boxes:
score = box[4]
x1, y1, x2, y2 = (box[:4] + 0.5).astype(np.int32)
w = x2 - x1 + 1
h = y2 - y1 + 1
size = int(max([w, h]) * 1.1)
cx = x1 + w // 2
cy = y1 + h // 2
x1 = cx - size // 2
x2 = x1 + size
y1 = cy - size // 2
y2 = y1 + size
dx = max(0, -x1)
dy = max(0, -y1)
x1 = max(0, x1)
y1 = max(0, y1)
edx = max(0, x2 - width)
edy = max(0, y2 - height)
x2 = min(width, x2)
y2 = min(height, y2)
cropped = image[y1:y2, x1:x2]
if (dx > 0 or dy > 0 or edx > 0 or edy > 0):
cropped = cv2.copyMakeBorder(cropped, dy, edy, dx, edx, cv2.BORDER_CONSTANT, 0)
cropped = cv2.resize(cropped, (112, 112))
input = cv2.resize(cropped, (112, 112))
input = cv2.cvtColor(input, cv2.COLOR_BGR2RGB)
input = self.transform(input).unsqueeze(0).cuda()
start_time = time.time()
_, landmarks = self.plfd_backbone(input)
logging.info(f"self.plfd_backbone(input) PFLD cost time : {str(time.time() - start_time)}")
pre_landmark = landmarks[0]
pre_landmark = pre_landmark.cpu().detach().numpy().reshape(-1, 2) * [size, size]
pre_landmark[:, 0] = pre_landmark[:, 0] + x1
pre_landmark[:, 1] = pre_landmark[:, 1] + y1
# for index, (x, y) in enumerate(pre_landmark.astype(np.int32)):
# print(f"\n {str(index)} ---- {str(x)},{str(y)} ---- {str(x1)}, {str(y1)}")
# if index == 96:
# cv2.circle(image, (x, y), 1, (0, 255, 255), 1)
# elif index == 1:
# cv2.circle(image, (x, y), 1, (255, 0, 0), 1)
#
# elif index == 97:
# # cv2.circle(image, (x1 + x, y1 + y), 2, (0, 255, 0), -1)
# cv2.circle(image, (x, y), 1, (0, 255, 0), -1)
# cv2.circle(image, (x1, y1), 2, (0, 0, 255), 1)
# cv2.circle(image, (x2, y2), 2, (0, 0, 255), 1)
# else:
# cv2.circle(image, (x, y), 1, (0, 0, 255), -1)
# # image = cv2.putText(image, str(index), (x, y), 1, 1, (255, 0, 255))
# cv2.imwrite("test_pfld_facelandmark3.jpg", image)
return pre_landmark