java部分基础知识
最近做完一个项目后,我忽然发现自己的基础并不怎么好,于是,重新翻看java编程思想这本书,发现这本书讲的确实好,不愧是编程界的畅销书。如下,便是自己的总结思考。
我们都知道,java当中的int是4字节,每字节占八位,也就是32位。这个位是什么意思呢?是针对二进制来说的。其取值为-2^(31)-2^(31)-1,你或许有一个疑问,为什么不是-2^(32)-2^(32)-1,如果,你学过计算机组成原理,你就会发现最高位是符号位,符号位的表示法:
| 符号位 | 解释 |
|---|---|
| 1 | 表示这个数是负数 |
| 0 | 表示这个数是正数 |
因而,不可能是-2^(-32)-2^(32)-1。当我们计算整数相加时,计算机内部是怎么计算的呢?计算机只认识0和1,因而,需要将整型数据转化为二进制,利用二进制的补码去计算,比如:
public static void main(String[] args) {
int firstNum=23;
int secondNum=44;
System.out.println("firstNum + secondNum = "+(firstNum+secondNum));
}
输出结果:
firstNum + secondNum = 67因而,计算机只认识0和1,我们将其转化为0和1,也就是二进制的原码。正数的补码和原码相同,负数的补码是原码的取反加1,这两个数都是正数,原码即为补码。因为firstNum 和 secondNum是int类型的,且是正数,4*8=32位,最高位为符号位,其原码、反码、补码是一样的,所以,其二进制和计算方式如图:

你我都很熟悉,每次编写完java代码,都要重新启动编译器。这是为了将java文件转化为字节码文件,然后编译相关的字节程序,最后以我们熟悉的方式输出到控制台。可以参考该链接:java编译字节码文件
如果我们将secondNum改为-44,这时二进制又该怎么计算呢?我有说过的,我们使用补码计算的,负数的补码是反码加1。当我们计算出来得到的补码,如果得到的结果为正数,我们就直接得到原码。如果得到的结果为负数,我们需要将补码取反减去1得到原码,再将原码转化为十进制,比如:
public static void main(String[] args) {
int firstNum=23;
int secondNum=-44;
System.out.println("firstNum + secondNum = "+(firstNum+secondNum));
}
得到的结果是 :firstNum + secondNum = -21我们来看其内不是如和计算的,如图所示:

这是模拟计算机内部操作,同理,其他计算也是如此的。我们常见的byte类型,1字节八位,这也是为什么取值范围是-2^7到2^7-1,即-128-127。short是两字节,即16位,最高位为符号位,取值范围是-2^15到2^15-1,为什么减1?你自己想想看。
按位符和移位符
按位符
| 符号名 | 中文名 | 条件 | 输出结果 |
|---|---|---|---|
| & | 按位与 | 当且仅当两个输入位同时1 | 其输出结果为1 |
| | | 按位或 | 两个输入位至少有一位是1 | 其输出结果为1 |
| ^ | 按位抑或 | 当且仅当两个输入位同时1 | 其输出结果为1 |
| ~ | 非 | 取反 | 数字取反 |
表格里的条件是什么意思呢?我举一个简单的例子就明白了,他们是针对二进制来判定的。
public static void main(String[] args) {
int i = 12;
int j = 23;
System.out.println("12&23的按位与的结果: \t" + (i & j));
System.out.println("12&23的按位与的结果: \t" + (i | j));
System.out.println("12&23的按位与的结果: \t" + (i ^ j));
}因为 i 和 j都是正数,其原码等于补码和反码,如果是负数,其补码等于原码取反加1,也就是负数的反码加1。因为,这都是对补码进行操作的,所以,我们在进行按位与、按位或、按位非操作时,需要将其转化为补码。以下就是数据运算。



我们学这些有什么用呢,请接下来看看移位运算符,移位运算符的效率远高于乘数,但其只针对乘2操作。移位运算符接近底层操作。当然,这也是针对补码来说的。如果是负数,补码即为原码取反加1,得到的结果也是补码,需要将补码减1再取反得到原码,原码转化为十进制,就是移位结果。左移移位乘以2,右移移位除以2。对于 byte 或者 short 类型数值,进行移位操作时,会先转换为 int 类型,然后进行移位(如果是 long 类型,则不变)。
| 符号 | 名称 | 含义 |
|---|---|---|
| << | 左移运算符 | 数值位向左移动指定位数,低位补0 |
| >> | 右移运算符 | 数字位向右移动指定位数(如果左操作数是正数,高位补 0 ;如果是负数,高位补 1) |
| >>> | 无符号右移 | 功能和右移运算符一样,不过无论正负,高位均补 0 |
public static void main(String[] args) {
int i = 12;
System.out.println("12左移3位\t"+(i<<3));
System.out.println("12*2*2*2\t"+i*2*2*2);
int k = -12;
System.out.println("-12左移3位\t"+(k<<3));
System.out.println("-12*2*2*2\t"+k*2*2*2);
// 输出结果为:
12左移3位 96
12*2*2*2 96
-12左移3位 -96
-12*2*2*2 -96
}对于 i 来说,左移3位,就相当于12*2^3,首先,计算出12的原码:0 0000000,00000000,0000000,00001100,因为补码和原码是一样的,所以,12的补码也是0 0000000,00000000,0000000,00001100,补码向右移3位的,0 0000000,00000000,0000000,01100000,计算出的十进制为2^6+2^5=64+32=96
对于 k 来说,左移3位,相当于-12*2^3,首先计算出-12的原码:1 0000000,00000000,0000000,00001100,原码取反得反码:0 1111111,11111111,11111111,11110011,反码加1得补码:0 1111111,11111111,11111111,11110100,此时将补码的数值位左移3位,但符号位不变得:0 1111111,11111111,11111111,10100000,但结果是补码,将结果的补码减1得:0 1111111,11111111,11111111,10011111,再取反的原码:1 0000000,00000000,00000000,01100000,计算得出的结果为:-(2^6+2^5)=-96
有人问了,我在工作中,并没有真正遇到移位运算符,但你在使用HashMap的时候,你是否去看过HashMap的put原码,如果没有看过,我现在写一个测试类
public static void main(String[] args) {
HashMap map = new HashMap<>();
Student student1 = new Student("张三", "浙江省杭州市下城区", 1L);
Student student2 = new Student("张三", "浙江省杭州市上城区", 1L);
System.out.println(student1.hashCode() == student2.hashCode());
map.put(student1, "买了3斤苹果,总计3元");
map.put(student2, "买了4斤苹果,总计3元");
System.out.println("sutdent1的信息:");
// 这种执行效率比较高
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey().getName() + " --> " + entry.getValue());
}
}
output:
false
sutdent的信息:
张三 --> 买了4斤苹果,总计3元
张三 --> 买了3斤苹果,总计3元
Entry是Map内部定义的接口,而map.entrySet()返回的Set>接口
/** @author Josh Bloch
* @see HashMap
* @see TreeMap
* @see Hashtable
* @see SortedMap
* @see Collection
* @see Set
* @since 1.2
*/
public interface Map {
Set> entrySet();
。。。
/**
* @see Map#entrySet()
* @since 1.2
*/
interface Entry {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
。。。
}
} 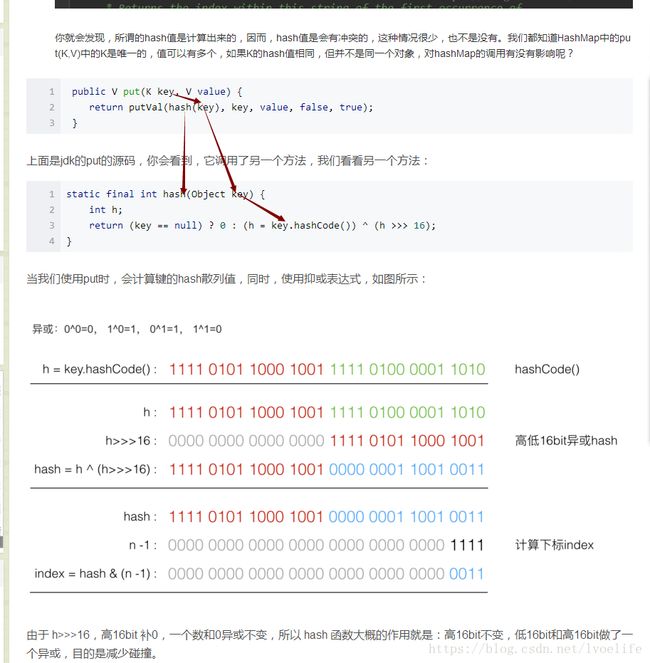
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
} 当我在执行map.put方法时,其内部会执行一个判断,判断当前key的hash散列值是否冲突的问题,所以,当你看到这段原码应该就比较熟悉了。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}也许,Map当中的put方法里的这个hash(Object key),你看不懂这个方法,我刚开始也不看懂这个步骤,但可以通过一个例子来看
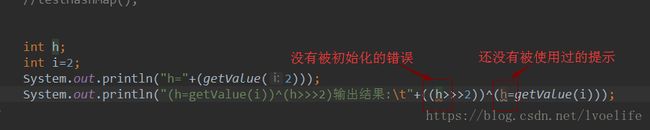
public static void main(String[] args) {
int h;
int i=2;
System.out.println("(h=getValue(i))^(h>>>2)输出结果:\t"+((h=getValue(i))^(h>>>2)));
}
/**
*
* @param i
* @return i<<1 即得到 i*2
*/
static int getValue(int i){
return i<<1;
}
output:(h=getValue(i))^(h>>>2)输出结果: 5我自己单独写了个方法,其输出结果是5,为什么是5呢,我们来计算一下哈:当方法执行到h=getValue(i)时, h就已经有值了,此时h的值是i左移一位后的值4,然后再进行抑或判断。

如果我们把 (h=getValue(i))^(h>>>2)中改为(h>>>2))^(h=getValue(i)),出现错误。
不得不佩服jdk的设计者,原来,代码也可以这样写。
byte和char
我们都知道byte是最小的数据大单位,其代表一个字节,即八位,因为最高位是符号位,取值范围是-2^7到2^7-1,char字符类型的,代表的是字符,而不是字符串,2字节,即16位,因最高位是符号位,取值范围是-2^15到2^15-1,short短整型,2字节,即16位,因最高位是符号位,取值范围是-2^15到2^15-1。
但当我们计算这三种数据类型,其内部在生成二进制时,首先将其转化为 int 类型的计算,最终生成的结果就是int类型的。
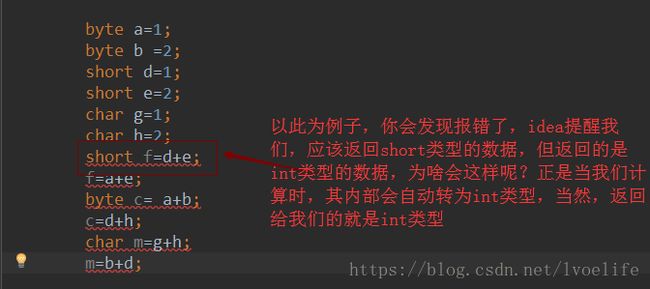
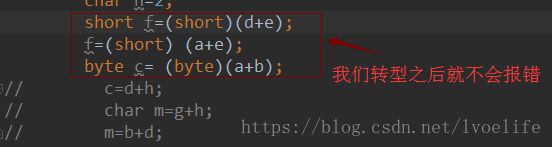
当我们想要返回时当前类型的数据,需要强制类型转换,就像 think in java 这本书提到的那样:
浮点型的默认类型是double,整型的默认类型是int
通常表达式中出现的最大的数据类型决定了表达式的最终结果的数据类型,如果将float值与一个double值相乘,结果就是double,如果讲一个int和一个long值相加,结果就是long。
我们有时候需要byte来操作字符串,文件等,比如当我们进行网络编程时,从前端传过来的值就是二进制的字节流,因而,byte是非常常用的类型,但我们平常见不到,为什么呢?因为我们要么使用ssm开发,要么使用ssh开发,根本不需要考虑byte,但如果我们学习了算法,就知道它非常实用。
比如,我们来计算一个字符串是不是有相同的字母或文字组成,我们该怎么计算呢?
/**
* Created by zby on 2018/08/30
*/
public class Test {
public static void main(String[] args) {
String s = "sss";
String s1 = "uzhzhuz";
System.out.println(isSameLetterComposition(s, s1));
}
/**
* 判断该两个字符串是否有相同的字母组成
*
* @param param1
* @param param2
* @return
*/
public static boolean isSameLetterComposition(String param1, String param2) {
if (isBlank(param1)) return false;
if (isBlank(param2)) return false;
byte[] bytes1 = param1.getBytes();
byte[] bytes2 = param2.getBytes();
int tmp1 = 0;
int tmp2 = 0;
for (byte b : bytes1) {
tmp1 += b;
}
for (byte b : bytes2) {
tmp2 += b;
}
return tmp1 == tmp2 ? true : false;
}
/**
* 字符串不为空
*
* @param params
* @return
*/
public static boolean isBlank(String params) {
return (params.equals("") || params == null || params.length() == 0) ? true : false;
}
}
我们再做一个综合的测试,在这个测试里面,你会用到左移运算符,也会用到char字符类型,当然,这有第一个版本。
package com.zby.service;
import java.util.Arrays;
/**
* @author zhubaoya
* @description ${DESCRIPTION}
* @time 2018年08月30日 20点04分
* @projectName test
*/
public class TestString {
public static void main(String[] args) {
String str="dddddddddddddddd";
int[] count=charLocation(str,'d');
for (int i : count) {
System.out.print(i+",");
}
}
/**
* 判断字符串是否为null
*
* @param str
* @return
*/
public static boolean isEmpty(String str) {
return str == null ? true : false;
}
/**
* 字符所在位置的集合
*
* @param str 字符串
* @param c 查找的字符
* @return
*/
public static int[] charLocation(String str, char c) {
int[] count = new int[5];
int size = 0;
if (isEmpty(str)) return count;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) == c) {
//如果下标越界,就扩容
if (count.length- 1 < size) {
// 左移一位,相当于乘以2
int newLength = (count.length << 1) + 2;
count = Arrays.copyOf(count, newLength);
} else
count[size++] = i;
}
}
return Arrays.copyOfRange(count, 0, size);
}
output:
0,1,2,3,4,6,7,8,9,10,11,12,14,15,你发现并没有5和13这个下标,为什么会这样呢?我们debug来看这上面的图片
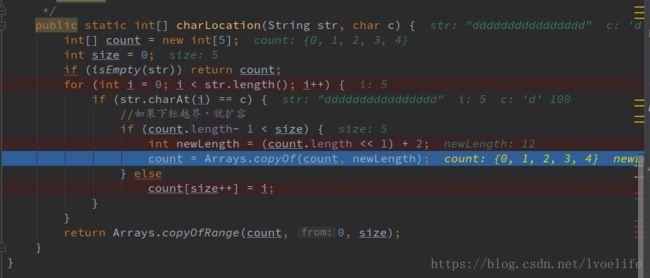
当我们执行到size=5的时候,count.length- 1 < size,进入到if分支,而这个分支里面并没有 count[size++] = i;,当 if 的生命周期结束,又跳回到外循环当中,并没有把i=5的数据放入到数组当中。而数组count已经扩容了,新数组的长度为12,大于size的数值,进入到else的分支当中。因而,我们需要调整代码,如下所示:
public static int[] charLocation(String str, char c) {
int[] count = new int[5];
int size = 0;
if (isEmpty(str)) return count;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) == c) {
//如果下标越界,就扩容
if (count.length - 1 < size) {
int newLength = (count.length << 1) + 2;
count = Arrays.copyOf(count, newLength);
}
// 去掉else,不乱扩不扩容,都执行这条语句
count[size++] = i;
}
}
return Arrays.copyOfRange(count, 0, size);
}
output:
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,
Process finished with exit code 0