Windows下Caffe的学习与应用(一)——训练自己的数据模型(GoogleNet)
前言
之前有用OpenCv的SUFT特征提取和SVM、BOW做过按图像里的内容进行分类的相关项目,耗时长,准确率又不是很高,各种优化之后准确率也只有百分七十到八十,所以一直想用caffe试试。
一、系统环境
1.windows 7 64位
之前一直在linux下(Ubuntu 16.04 64位)使用过caffe,然后也有在win7 32位试过,能编译,但是在训练过程中出现各种小问题,所有就换64位系统,在训练没有遇到什么问题。
2.Anaconda3
安装Anaconda3尽量装3.4,这样就不用再把python的版本降到3.5。
3.caffe CPU
caffe我使用的是CPU版本。
二、数据收集与处理
1.收集数据
图像数据是从ZOL壁纸网站下载,里面有分类好的壁纸,可以整个系列下载。下载之后新建文件夹放同类型的图像,我收集了四个类型的然后手工分类放到相关的文件夹里,每个种类收集了差不多150张图像。

比如我这里把动漫人物放到这个文件夹下:
2.更改文件名
但下载下来的文件的文件名很混乱,所以要更改成与文件夹对应的文件名,方便之后训练使用,编写python脚本更改整个文件夹的文件名,每个类型的文件夹运行一次
rename.ipynb
import os
def rename():
path="E:/caffe/4/" #文件路径
ex = 4
filelist = os.listdir(path) #该文件夹下的所有文件
count = 0
for file in filelist: #遍历所有文件 包括文件夹
Olddir = os.path.join(path,file)#原来文件夹的路径
if os.path.isdir(Olddir):#如果是文件夹,则跳过
continue
filename = os.path.splitext(file)[0] #文件名
filetype = ".jpg"#os.path.splitext(file)[1] 文件扩展名
p = str(count).zfill(3)
Newdir = os.path.join(path,str(ex)+p+filetype) #新的文件路径
os.rename(Olddir,Newdir) #重命名
count += 1
rename()
得到统一递增的文件名,文件名前缀是当前的文件夹名,生成训练文件名列表是以文件名前缀打上标签。
3.统一图像大小
下载下来的图像文件大小有很多用类型的,编写python脚本把每个文件夹下的图像改成统一大小的像素的,该脚本把所有图像改成宽384和高256的图像。
resize.ipynb
from PIL import Image
import glob, os
w,h = 384,256 #更改成的分辨率
def timage():
for files in glob.glob('E:/caffe/5/*.jpg'): #原文件路径
filepath,filename = os.path.split(files)
filterame,exts = os.path.splitext(filename)
opfile = r'E:/caffe/data/5/' #保存的文件路径
if (os.path.isdir(opfile)==False):
os.mkdir(opfile)
im=Image.open(files)
im_ss=im.resize((int(w), int(h)))
try:
im_ss.save(opfile+filterame+'.jpg')
except:
print (filterame)
os.remove(opfile+filterame+'.jpg')
if __name__=='__main__':
timage()
4.可以从这里下载我分好类的正样本和测试样本,下载地址:https://download.csdn.net/download/matt45m/11044661
三、准备训练
1.创建数据文件夹
(1)在caffe-windows/data路径下创建一个自己存放数据的文件夹,这里起名为classify,在classify创建两个文件夹,分别为train和test,如下图:
(2)把要训练的图像文件放到train文件夹下,这里每个类别选了120张照片放进来,剩下的图像放到test文件夹里面,如下图:
(3)test文件夹里放着测试用的图像,如下图:
2.得到数据集文件名列表
(1)编写python代码,得到train与test文件夹下的文件列表并标记
getFileNameList.ipynb
import os
if __name__ == "__main__":
data_dir = 'E:/LIB/caffe-windows/data/classify/test/' #要遍历的文件夹
fid = open("E:/LIB/caffe-windows/data/classify/test.txt","w") #保存的文件列表
files = os.listdir(data_dir)
index = 0
for ii, file in enumerate(files,1):
fid.write("{0}{1} {2}\n".format("",file, int(file[0])-2))
index = index + 1
if index%100 == 0:
print("{0} images processed!".format(index))
print("All images processed!")
fid.close()
运行之后在classify文件夹生成两个train.txt和test.txt

(2)得到的train.txt和test.txt文件内容如下:
test.txt的一部分内容,后面数字为类型标记
train.txt的内容,后面数字为类型标记
四、转换数据
在caffe-windows/data/classify文件夹下编写脚本,把图像数据改成Leveldb格式
data_convention.bat
E:/LIB/caffe-windows/build/tools/Release/convert_imageset.exe --shuffle --resize_height=256 --resize_width=256 --shuffle --backend=leveldb E:/LIB/caffe-windows/data/classify/train/ E:/LIB/caffe-windows/data/classify/train.txt E:/LIB/caffe-windows/data/classify/train_leveldb
E:/LIB/caffe-windows/build/tools/Release/convert_imageset.exe --shuffle --resize_height=256 --resize_width=256 --shuffle --backend=leveldb E:/LIB/caffe-windows/data/classify/test/ E:/LIB/caffe-windows/data/classify/test.txt E:/LIB/caffe-windows/data/classify/test_leveldb
pause
其中resize_height和resize_width表示将原图像更改为相应的大小,这里改成256是因为选取的网络(ImageNet)的要求,shuffle是将数据随机打乱的意思,backend表示将数据转换的格式,这里选择Leveldb。
出现下面的窗口代表转换成功

注:Caffe生成的数据分为2种格式:Lmdb和Leveldb,它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。lmdb的内存消耗是leveldb的1.1倍,但是lmdb的速度比leveldb快10%至15%,更重要的是lmdb允许多种训练模型同时读取同一组数据集。因此之后lmdb取代了leveldb成为Caffe默认的数据集生成格式。但上面还是使用Leveldb数据类型。
2.运行之后在caffe-windows/data/classify生成两个文件夹,test_leveldb和train_leveldb两个文件夹:
test_leveldb文件夹下内容
train_leveldb文件夹下内容

五、生成均值文件
在caffe-windows/data/classify文件夹下编写脚本,点击运行,生成均值文件
data_mean.bat
E:/LIB/caffe-windows/build/tools/Release/compute_image_mean.exe E:/LIB/caffe-windows/data/classify/train_leveldb --backend=leveldb E:/LIB/caffe-windows/data/classify/train_mean.binaryproto
E:/LIB/caffe-windows/build/tools/Release/compute_image_mean.exe E:/LIB/caffe-windows/data/classify/test_leveldb --backend=leveldb E:/LIB/caffe-windows/data/classify/test_mean.binaryproto
pause
其中backend的参数要与上面转换时的格式保持一致,运行完成后,会在caffe-windows/data/classify文件夹下生成train_mean.binaryproto和test_mean.binaryproto文件
出现以下窗口代表生成成功
在caffe-windows/data/classify生成两个均值文件,如下:

六、训练数据
1.将caffe-windows/models/bvlc_reference_caffenet文件夹下的deploy.prototxt、solver.prototxt和train_val.prototxt拷贝到caffe-windows/data/classify下。
bvlc_reference_caffenet文件夹:
复制到classify文件夹下:

2.更改solver.prototxt
#训练样本为480张图像,batch_size = 60,480 / 60 = 8 那么test_interval(测试间隔)的值要大于或者等于8,即处理完一次所有的训练数据后,才去进行测试.
#如果想训练100代,max_iter 则最大迭代次数为800。
#测试数据为100张图像,batch_size = 25,100 / 25 = 4 那么test_interval(测试间隔)的值要大于或者等于4,即需要4次才能完整的测试一次。
#stepsize(学习率变化规律)置为随着迭代次数的增加,慢慢变低。总共迭代800次,我们将变化5次,所以stepsize设置为800/5=160,即每迭代160次,就要降低一次学习率。
net: "data/classify/train_val.prototxt" #训练或者测试配置文件
test_iter:4 #完成一次测试需要的迭代次数
test_interval: 8 #测试间隔
base_lr: 0.001 #基础学习率
lr_policy: "step" #学习率变化规律
gamma: 0.1 #学习率变化指数
stepsize: 160 #学习率变化频率 (stepsize不能太小,如果太小会导致学习率再后来越来越小,达不到充分收敛的效果)
display: 20 #屏幕显示间隔
max_iter: 800 #最大迭代次数
momentum: 0.9 #动量
weight_decay: 0.0005 #权重衰减
snapshot: 5000 #保存模型间隔
snapshot_prefix: "data/classify/caffenet_train" #保存模型的前缀
solver_mode: CPU #使用GPU或者CPU
3.更改train_val
对trian_val文件进行修改,更改source路径,batch_size,backend和mean_file,其中batch_size看计算机的配置,计算机配置较高,可以设大一点,训练的结果准确率会有些提升。
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data" #输出数据
top: "label" #输出标签
include {
phase: TRAIN #训练阶段
}
transform_param {
mirror: true #映射是否开启
crop_size: 227 #图的尺寸
mean_file: "data/classifyCPP/train_mean.binaryproto" #均值文件路径
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "data/classifyCPP/train_lmdb" #训练集的lmdb数据路径
batch_size: 60 #每一批的大小
backend: leveldb #数据格式leveldb
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST #测试阶段
}
transform_param {
mirror: false #映射是否开启
crop_size: 227 #测试图的尺寸
mean_file: "data/classifyCPP/test_mean.binaryproto" #测试集的均值文件
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "data/classifyCPP/test_lmdb" #测试集的lmdb数据路径
batch_size: 25 #测试图像个数
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4 #训练的种类
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
4.编写训练脚本
trainSc.bat
cd ../../
"E:/LIB/caffe-windows/build/tools/Release/caffe.exe" train --solver=data/classify/solver.prototxt
pause
点击运行
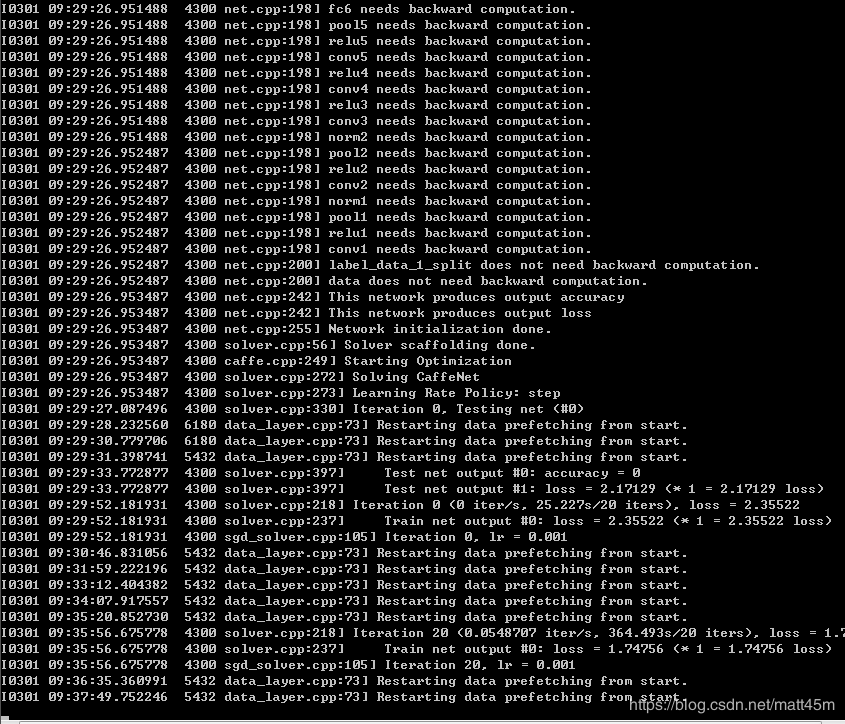
等待运行结束,在classify会多出两个训练好的模型
所有训练完成,之后就是如何测试和使用模型。
七.测试模型
1.修改caffe-windows/data/classify/deploy.prototxt文件,训练是4个类型的数据,那么这里要改成4,注意看行数,不要改前面。

2.编写脚本data_test.bat,运行classification.exe,如果报错,手动查找classification.exe这个文件,脚本里改成它所在的位置,运行。
E:\LIB\caffe-windows\build\examples\cpp_classification\Release\classification.exe ..\..\data\classifyCPP\deploy.prototxt ..\..\data\classifyCPP\caffenet_train_iter_800.caffemodel ..\..\data\classifyCPP\test_mean.binaryproto ..\..\data\classifyCPP\labels.txt ..\..\data\classifyCPP\test\5136.jpg
pause
3.运行结果,有些特征类似的图像还是不能很好的判断,这个要去更改相关配置,重新训练。
(1)测试图像

运行结果:
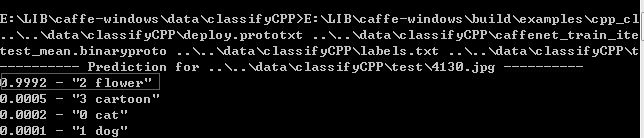
(2)测试图像

运行结果:
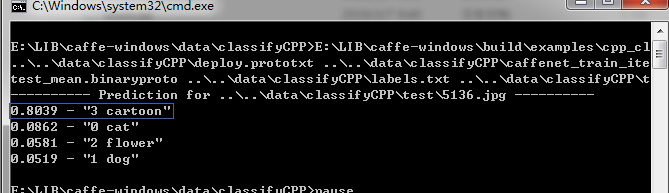
(3)测试图像

运行结果:

这个结果是判断错误的。
后记:
1.以上只是训练成模型的部分,是于如何在win7下编译caffe的办法,现在没有时间去整理,如果有需要问的可以私信我一起探讨。
2.关于python的几个脚本,不熟悉python的,也可用C++实现,C++要使用boost库读取文件操作相对简单一些。
3.之后有时间会写caffe的fine tuning和使用opnecv调用caffe训练好的模型。
4.有兴趣讨论学习可以加群:487350510。