爬取《全职高手之巅峰荣耀》的豆瓣影评,分析漫改电影的优劣好坏
周末去看了《全职高手之巅峰荣耀》的大电影。记得是看扫毒2还是更前一点的电影时。全职大电影的预告片就出来了,第一眼看中的时候,就决定必须去看这场电影了。(每周一场的电影,默认成为习惯了)
电影的好处在于,可以暂时脱离本身的角色设定,转而融入电影中的某个背景,感受不同的生活体验,精神感受,以及揣摩导演,制作者的一些小心思。理解电影想表达什么,理解制作者在某个小细节上的精彩处理,这也是看电影的一种另类收获。
电影相对于原作来说,可以更生动,更完美的表达出人物之间的关系。具体情境下的环境感受。有人在看到某个熟悉的场景时会情不自禁的代入。见过有在电影院痛哭流涕的,也有某个激动的场景,大家一起呐喊助威的。电影的魅力就在于此。
想起在看《毒液》时,前面有个小弟弟一直在眉飞色舞的给小伙伴解说人物关系,故事剧情(当时很想锤他一顿,O(∩_∩)O哈哈~)
<全职高手>作者是蝴蝶蓝,讲述的是一个荣耀新人叶不修,因为自身开挂太过严重,而导致被俱乐部封杀,结果又凑齐了各种挂壁一起殴打俱乐部,脚踏前妻的故事。故事很精彩,角色设定也很出色。是个值得一看的网瘾小说。
咳咳,还是先做正事要紧,鉴于对这部大电影的期待,决定爬取豆瓣的影评,分析分析这部电影的优劣好坏。
爬取豆瓣影评
找到电影的影评页面(一眼望去全是差评啊,我滴个乖乖)

确定我们需要的信息字段,分别是影评人,评论,评价,评价日期,以及点赞的人数。
评价在网页上显示的是星级,而在html文件中@title属性中是对应的标准。
如下所示:

四星 = ‘推荐’,一星=‘很差’,二星=‘较差’,三星=‘还行’,五星=‘力荐’.
豆瓣的整体页面结构算是简单的没有特别复杂的网页嵌套,我们就选用requests请求,这样的请求过程清晰简单,方便修改。
找到需要字段的xpath规则,也可以用css选择器,具体按自己需要来选择。

所有的影评内容都在id="comments"的div标签下,每一页有20条数据。
需要将20条信息每个都单独分开,就不能直接选择单条的xpath规则,需要先定位到20条整体的div标签上,再循环遍历获取单条的整体信息。
具体代码如下:
def get_default(self, ob):
"""
获取指定数据
:param ob:
:return:
"""
# 评论
yingping_xpath = "./p//text()"
yingping = ob.xpath(yingping_xpath).extract()
yingping = "".join(yingping).strip()
# print(yingping)
# 影评人
zuozhe_xpath = "./h3/span[2]/a/text()"
zuozhe = ob.xpath(zuozhe_xpath).extract_first()
# print(zuozhe)
# 获赞数
zan_xpath = "./h3/span[1]/span/text()"
zan = ob.xpath(zan_xpath).extract_first()
# print(zan)
# 星级
star_xpath = "./h3/span[2]/span[2]/@title"
star = ob.xpath(star_xpath).extract_first()
# 评论日期
date_xpath = "./h3/span[2]/span[@class='comment-time ']/text()"
date = ob.xpath(date_xpath).extract_first().strip()
# print(date)
return [yingping, zuozhe, zan, star, date]
def get_content(self, url):
"""
获取数据
:return:
"""
file_path = os.path.dirname(os.path.abspath(__file__)) + "/豆瓣影评.xlsx"
df = pd.read_excel(file_path, sheet_name="全职高手之巅峰荣耀", header=None)
print(url)
# url = "https://movie.douban.com/subject/26794435/comments?start=480&limit=40&sort=new_score&status=P&percent_type="
response = self.parse_url(url)
# 数据对象列表
obj_list_xpath = "//div[@id='comments']/div/div[@class='comment']"
obj_list = self.content_xpath(response, obj_list_xpath)
# 详情内容列表
content_list = list(map(self.get_default, obj_list))
函数get_default()是作为获取单条数据的处理函数。返回一条影评的全部信息。
获取的数据直接存入excel文件,方便后面的数据分析。这里创建Excel文件和数据存入Excel文件的操作都是借助Pandas第三方库来完成的。具体代码会在源码中展示。
生成的Excel文件如下:
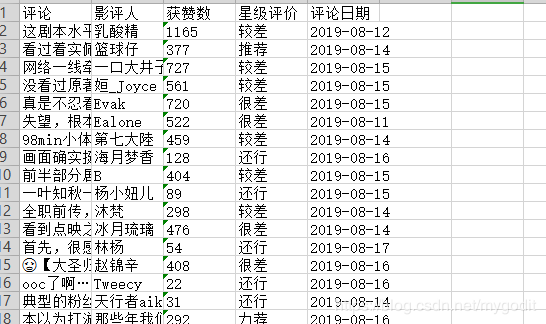
总计503条影评数据。
影评分析
所有的影评信息已经拿到了,接下来要做的就是整理所有的信息数据,分析影评的结果。
1.关于评论的分析。
1.1获取评论列表
评论的信息内容是一个文本字符串,需要分析大家评论的核心内容都是关于电影的哪一方面。
利用Pandas读取,整合影评的Excel文件内容。评论信息在第一行。
def read_excel(self):
"""
读取影评内容
:return:
"""
file_path = os.path.dirname(os.path.abspath(__file__)) + "/豆瓣影评.xlsx"
df = pd.read_excel(file_path, sheet_name="全职高手之巅峰荣耀", header=0)
# print(df.iloc[:, 0])
return df.iloc[:, 0]
读取excel内容用df.iloc[:,:],依据索引可以指定想要获取的某行某列数据,我们需要的评论信息是所有的第一行,所以函数返回的信息为df.iloc[:,0],第一个选择整体行,第二个0选择第一列。
返回的内容是一个评论列表,每一条影评为一个元素。
1.2词频统计
统计评论信息的词频需要使用Jieba中文分词库。
具体的实现方式有两种:
1.将所有的评论使用列表的join()方法拼接成一个大字符串,调用中文分词器对这个大字符串进行词频统计。
这个方法比较简单,代码简洁,比较担心的是,如果这个字符串特别大的时候,会不会影响词频统计的结果。
2.将每条评论作为单独的字符串去分词统计词频。每条评论表达的信息都是不同,这样的分词结果也不会出现大的异议。不用关心影评的数量大小。
具体代码如下:

返回的结果是一个列表,元素为字典,有两个键值对,第一个键值对是词的内容,第二个是词的数量,这里不存在去重的问题。
出现多次的词就会有多个字典,每次的count都为1。分词结束后,将word相同的count值取和就能得到每个词出现的词频了。
统计词频的代码如下:

调用pandas库的方法分组,排序,求和,返回词频数排名前100的词频。
1.3制作词云
根据生成的词语和词频,我们制作一个可视化的词云图,看看大家评论中的中心思想是什么。
制作可视化词云使用的是pyecharts第三方库。制作简单,效果出众。顺便打个广告,嘿嘿。
最终生成的效果词云图如下:

最主要的还是电影和剧情两个词,不过我猜是差评的电影和剧情,哈哈哈。评论中哈哈哈哈的也不少。
词云图只能看到评论的核心是讨论什么的,看不出来这个电影是差还是好呢。
接下来我们就来分析一下观众老爷们的星级评价。彻底揭露出漫改电影的原相。
星级评价分析
星级评价的分析需要读取Excel文件中的星级评价和获赞数,具体的星级评价只有五个,具体的影评有五百多条。
需要将相同的星级评价进行整合,并且每种评价的获赞数也是代表了评价。
1.读取数据,合并数据
第一步利用Pandas库来读取星级评价的内容和获赞数。根据索引读取的方法为df.iloc[:,2,4]。
第二步 合并 星级评价和赞数的数据。
具体是做法是选用字典数据类型,星级评价只有五个会重复不能作为键,以获赞数作为键,星级评价作为值。
赋值一个空字典,判断value值是否在这个字典中,反转键值对,值value叠加。
生成的新字典就是以星级评价为key,获赞的总数量为值的。(这个方法有个小问题是,如果获赞数出现重复的话会对丢失数据。)
有更好方法的话,后面会再更新。
具体代码如下:

第三步生成星级评价的百分比图和漏斗图。
效果图展示:
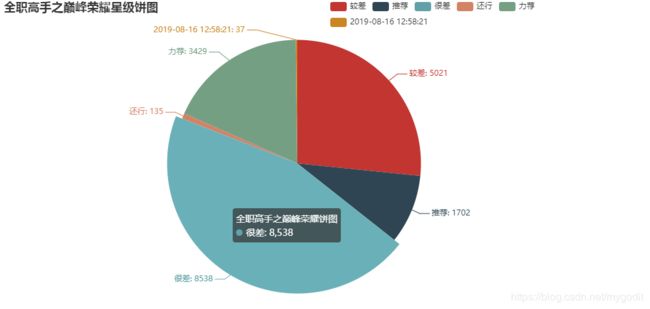
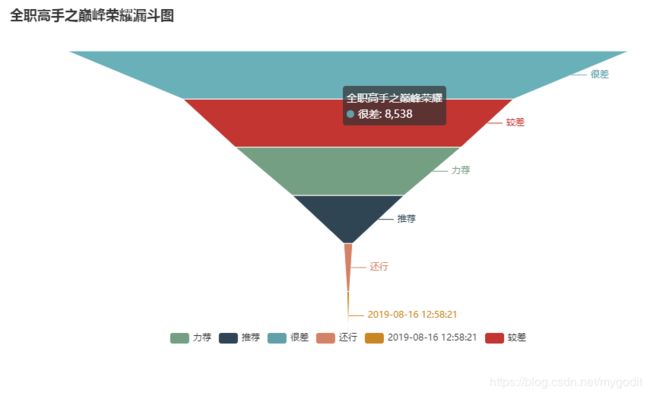
通过百分比图和漏斗图的直观展示,可以看出《全职高手之巅峰荣耀》大电影的星级评价还真是惨不忍睹啊。。。。。
一星和二星的差评占比达到了百分之七十左右。
说实话这部电影的槽点太多了,剧情碎裂,战斗画面切转莫名其妙,整体的剧情速度感觉有点赶时间,后面怕是有狼在追着制片方似的。
沐橙的年龄也是一个很大的槽点,沐橙比叶修也就小三岁,再怎么说也是个元气满满的青春美少女了,电影里的沐橙最多也就一个小学三年级的萝莉。
暗无天日的转折加入一脸懵逼,前面做了那么多的铺垫,按理来说,最后的转折加入,至少也要在一个比较关键的时刻出现吧,结果刚出来就露个面摆个poss,就被扫地焚香吊着打了,完全一副路人甲的姿态啊喂。
还有最后决战的七阶斗者意志的变身,影评里有人说像是圣斗士的战斗变身,噗,哈哈哈。忍不住了,感觉变身有点夸张了,变身的服装效果直接就抢了角色的重点,变成普通动画水平了。其实做个光环效果就差不多了,类似于火影中的八门遁甲的颜色变化,或者超级赛亚人的光效(想了想那个画面,还是八门遁甲吧)。
不过,就算是有这些槽点,全职粉还是有看头的。
开篇第一场一叶知秋和大漠孤烟的沙漠对决,动作对打加上超燃的音乐,心情瞬间就被带动起来了。(再吐槽一下,电影中和叶修相爱相杀的韩文清镜头也忒少了吧)。大漠孤烟和一叶知秋在加入职业之前可都是竞技场的大神啊。怎么电影了完全就成了路人甲了呢。原著党表示不服。
苏沐秋和叶修的伦理联系也得到了答案。至于苏沐秋的巧合车祸,逻辑上说的通就不存在勉强了。重要的是能接上剧情。
刚开始接触到全职是因为动漫版的第一话,叶修出了俱乐部的门,走在大街上,雪花零零散散的落在他的衣帽上,叶修缩缩肩膀,拉了一下帽子,说“好冷”。那一刻的叶修,身上就是深深的孤独。就这一个场景,促使我必须追完整个动漫。了解他的故事,体会他的感受。
“荣耀。从来就不是一个人的游戏。”
《全职高手之巅峰荣耀》这部大电影就当做一个番外,真正的荣耀第二季动漫见。
《全职高手》小说采集
最后在做个全职小说的采集。让你了解真正的荣耀。
效果如下:

想要源码的小伙伴可以私信我。
我是北房有佳人,金屋藏娇的那个。O(∩_∩)O哈哈~