BERT Word Embeddings 教程
本篇文章译自 Chris McCormick
的BERT Word Embeddings Tutorial
在这篇文章,我深入研究了由Google的Bert生成的word embeddings,并向您展示了如何通过生成自己的word embeddings来开始Bert。
这篇文章有两种形式——一种是博客文章,另一种是colab的notebook。
介绍
历史
2018年是NLP取得突破性进展的一年。迁移学习,特别是像Allen-AI的ELMO、OpenAI的Open-GPT和Google的BERT这样的模型,使研究人员能够以最小的特定于任务的微调来粉碎多个基准点,并为NLP社区的其他人提供更容易(使用更少的数据和更短的计算时间)微调的预训练模型。进行微调并实现,以产生最先进的结果。不幸的是,对于许多在NLP起步的人,甚至对一些有经验的实践者来说,这些强大的模型的理论和实际应用还没有被很好地理解。
什么是BERT?
BERT(Transformers的双向编码器表示)于2018年底发布,是我们将在本教程中使用的模型,旨在为读者更好地理解和指导在NLP中使用迁移学习模型。BERT是一种预训练语言表示的方法,是NLP实践者可以免费下载和使用的模型。您可以使用这些模型从文本数据中提取高质量的语言功能,也可以在特定任务(分类、实体识别、问题解答等)上使用自己的数据对这些模型进行微调,以生成最新的预测。
为什么是BERT?
在本教程中,我们将使用bert从文本数据中提取特征,即单词和句子embedding vectors(嵌入向量)。我们可以用这些单词和句子的嵌入向量做什么?首先,这些嵌入对于关键字/搜索扩展、语义搜索和信息检索很有用。例如,如果您希望匹配客户问题或针对已回答问题或有良好文档记录的搜索,这些表示将帮助您准确地检索与客户意图和上下文含义匹配的结果,即使没有关键字或短语重叠。
其次,也许更重要的是,这些向量被用作下游模型的高质量特征输入。像lstms或cnns这样的nlp模型需要以数字向量的形式输入,这通常意味着将词汇和部分演讲等特征转换为数字表示。在过去,单词要么被表示为唯一的索引值(独热编码),要么更有用地表示为神经单词嵌入,其中词汇单词与固定长度的特征嵌入相匹配,这是由Word2Vec或FastText等模型产生的。Bert比Word2vec等模型更具优势,因为每个单词在Word2vec下都有一个固定的表示,而不管单词出现在什么上下文中,Bert都会生成由它们周围的单词动态inform的单词表示。例如,给出两个句子:
“The man was accused of robbing a bank.”
“The man went fishing by the bank of the river.”
word2vec将在两个句子中为单词“bank”生成相同的词嵌入,而在BERT 下,“bank”的单词嵌入对于每个句子都是不同的。除了捕获明显的差异(如多义),上下文通知的单词嵌入还捕获其他形式的信息,这些信息会导致更精确的特征表示,进而导致更好的模型性能。
安装和导入
通过Hugging Face为BERT安装pytorch接口。(该库包含其他预训练语言模型的接口,如OpenAI的GPT和GPT-2)我们选择了pytorch接口,因为它在高级API(易于使用但不提供具体如何工作)和tensorflow代码(其中包含许多细节,但经常会让我们陷入关于张量流的课程,当这里的目的是BERT时)之间取得了很好的平衡 。
如果您在Google Colab上运行此代码,则每次重新连接时都必须安装此库; 以下单元格将为您处理。
! pip install pytorch-pretrained-bert
现在让我们导入pytorch,预训练的BERT model和BERT tokenizer。 我们将在后面的教程中详细解释BERT模型,这是由Google发布的预训练模型,该模型在维基百科和Book Corpus上运行了许多小时,这是一个包含不同类型的+10,000本书的数据集。 该模型(稍作修改)在一系列任务中击败NLP各项基准。 Google发布了一些BERT型号的变体,但我们在这里使用的是两种可用尺寸(“base” 和 “large”))中较小的一种并且忽略了 casing,因此是 “uncased.”
import torch
from pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM
# OPTIONAL: if you want to have more information on what's happening, activate the logger as follows
import logging
#logging.basicConfig(level=logging.INFO)
import matplotlib.pyplot as plt
% matplotlib inline
# Load pre-trained model tokenizer (vocabulary)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
100%|██████████| 231508/231508 [00:00<00:00, 2386266.84B/s]
输入格式
由于bert是一个预训练模型,它期望输入数据采用特定格式,因此我们需要:
- special tokens to mark the beginning ([CLS]) and separation/end of sentences ([SEP])
- tokens that conforms with the fixed vocabulary used in BERT
- token IDs from BERT’s tokenizer
- mask IDs to indicate which elements in the sequence are tokens and which are padding elements
- segment IDs used to distinguish different sentences
- positional embeddings used to show token position within the sequence
幸运的是,这个接口为我们处理了一些输入规范,因此我们只需要手动创建其中的一些(我们将在另一个教程中重新访问其他输入)。
特殊的Tokens
BERT可以将一个或两个句子作为输入,并期望特殊tokens标记每个句子的开头和结尾:
2个句子的输入:
[CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
1个句子的输入:
[CLS] the man went to the store [SEP]
text = "Here is the sentence I want embeddings for."
text = "After stealing money from the bank vault, the bank robber was seen fishing on the Mississippi river bank."
marked_text = "[CLS] " + text + " [SEP]"
print (marked_text)
[CLS] After stealing money from the bank vault, the bank robber was seen fishing on the Mississippi river bank. [SEP]
我们已经引入一个BERT指定的tokenizer库,让我们看一眼输出:
Tokenization
tokenized_text = tokenizer.tokenize(marked_text)
print (tokenized_text)
['[CLS]', 'after', 'stealing', 'money', 'from', 'the', 'bank', 'vault', ',', 'the', 'bank', 'robber', 'was', 'seen', 'fishing', 'on', 'the', 'mississippi', 'river', 'bank', '.', '[SEP]']
注意“embeddings”这个词是如何表示的:
[‘em’, ‘##bed’, ‘##ding’, ‘##s’]
原始单词已被拆分为较小的子词和字符。这些子字之前的两个哈希符号只是我们的tokenizer表示该子字或字符是较大字的一部分并且前面是另一个子字的方式。因此,例如‘##bed’ 这个token和 ‘bed’ 这个token不同,第一个被使用每当子词'bed'出现在一个较大的单词中时,第二个被明确用于当独立token'你睡觉的东西'出现时。
为什么看起来像这样?是因为BERT的tokenizer是使用WordPiece模型创建的。这个模型贪婪地创建了一个最适合我们的语言数据的固定数量的单个字符,子词和单词的词汇表,由于我们的BERT标记器模型的词汇限制大小为30,000,因此WordPiece模型生成的词汇表包含所有英文字符以及在模型训练的英语语料库中找到的~30,000个最常见的单词和子词。 这个词汇表包含四件事:
- 整个词
- 在单词的前面或单独出现的子词(在“embeddings”中的“em”被赋予与独立的“em”字符序列相同的向量,如“go get em”中所示)
- 不在单词前面的子词,前面有'##'表示这种情况
- 单个字符
要在此模型下对单词进行tokenize,tokenizer 首先检查整个单词是否在词汇表中。 如果没有,它会尝试将单词分解为词汇表中包含的最大可能子词,并作为最后的手段将单词分解为单个字符。 请注意,正因为如此,我们总是可以将一个单词表示为其各个字符的集合。
因此,不是将不在词汇表中的单词分配给像'OOV'或'UNK'这样的全能标记,而是将不在词汇表中的单词分解为子字和字符标记,然后我们可以为其生成嵌入。
因此,我们不是将“embeddings”和每一个不在词汇表中其他词汇分配一个重载的未知词汇表token,而是将其分为子词token['em','##bed','##ding','## s' ]这将保留原始单词的一些上下文含义。我们甚至可以平均这些子字嵌入向量以生成原始单词的近似向量。
以下是我们词汇表中包含的令token的一些示例。 以两个哈希开头的标记是子字或单个字符。
list(tokenizer.vocab.keys())[5000:5020]
['knight',
'lap',
'survey',
'ma',
'##ow',
'noise',
'billy',
'##ium',
'shooting',
'guide',
'bedroom',
'priest',
'resistance',
'motor',
'homes',
'sounded',
'giant',
'##mer',
'150',
'scenes']
接下来,我们需要调用tokenizer来将token与tokenizer词汇表中的索引进行匹配:
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
for tup in zip(tokenized_text, indexed_tokens):
print (tup)
('[CLS]', 101)
('after', 2044)
('stealing', 11065)
('money', 2769)
('from', 2013)
('the', 1996)
('bank', 2924)
('vault', 11632)
(',', 1010)
('the', 1996)
('bank', 2924)
('robber', 27307)
('was', 2001)
('seen', 2464)
('fishing', 5645)
('on', 2006)
('the', 1996)
('mississippi', 5900)
('river', 2314)
('bank', 2924)
('.', 1012)
('[SEP]', 102)
Segment ID
BERT接受过句子对的训练,期望使用1和0来区分这两个句子。也就是说,对于“tokenized_text”中的每个标token,我们必须指定它属于哪个句子:句子0(一系列0)或句子1(一系列1)。出于我们的目的,单句输入只需要一系列1,因此我们将为输入句中的每个token创建一个1的向量。如果要处理两个句子,请将第一个句子中的每个单词再加上'[SEP]'token分配为0,将第二个句子的所有token分配为1。
segments_ids = [1] * len(tokenized_text)
print (segments_ids)
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
运行我们的示例
接下来,我们需要将数据转换为torch张量并调用BERT模型。 BERT PyTorch接口要求数据在torch张量而不是Python列表中,因此我们在此处转换列表-这并不会改变形状或数据。
model.eval()将我们的模型置于评估模式而不是训练模式。 在这种情况下,评估模式关闭在训练中使用的dropout正则化。
调用from_pretrained将从互联网上获取模型。当我们加载bert-base-uncased时,我们会看到在logging记录中打印的模型的定义。该模型是一个12层的深度神经网络!解释网络层及其作用超出了本文的范围,您现在可以跳过此输出。
# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# Load pre-trained model (weights)
model = BertModel.from_pretrained('bert-base-uncased')
# Put the model in "evaluation" mode, meaning feed-forward operation.
model.eval()
output:
100%|██████████| 407873900/407873900 [00:06<00:00, 61266351.38B/s]
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1)
)
(encoder): BertEncoder(
(layer): ModuleList(
...
省略output
...
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
接下来,让我们获取网络的隐藏状态。
Torch.no_Grad关闭梯度计算,节省内存,并加快计算速度(我们不需要梯度或反向传播,因为我们只是向前传播)
# Predict hidden states features for each layer
with torch.no_grad():
encoded_layers, _ = model(tokens_tensor, segments_tensors)
输出
存储在对象encoded_layers中的该模型的完整隐藏状态有点令人眼花缭乱。 此对象具有四个维度,顺序如下:
- The layer number (12 layers)
- The batch number (1 sentence)
- The word / token number (22 tokens in our sentence)
- The hidden unit / feature number (768 features)
这是202,752个唯一值,只是为了代表我们的一句话!第二个维度,即批量大小,在一次向模型提交多个句子时使用; 但是,在这里,我们只有一个例句。
print ("Number of layers:", len(encoded_layers))
layer_i = 0
print ("Number of batches:", len(encoded_layers[layer_i]))
batch_i = 0
print ("Number of tokens:", len(encoded_layers[layer_i][batch_i]))
token_i = 0
print ("Number of hidden units:", len(encoded_layers[layer_i][batch_i][token_i]))
Number of layers: 12
Number of batches: 1
Number of tokens: 22
Number of hidden units: 768
让我们快速浏览一下给定网络层和token的值范围。
您会发现,对于所有层和token,范围都相当相似,其中大部分值介于-2、2之间,少量值在-10左右。
# For the 5th token in our sentence, select its feature values from layer 5.
token_i = 5
layer_i = 5
vec = encoded_layers[layer_i][batch_i][token_i]
# Plot the values as a histogram to show their distribution.
plt.figure(figsize=(10,10))
plt.hist(vec, bins=200)
plt.show()

image.png
按层对值进行分组对于模型来说是有意义的,但是为了我们的目的,我们希望它按token进行分组。
下面的代码只是调整值的形状,以便我们可以将其保存在表单中:
[# tokens, # layers, # features]
# Convert the hidden state embeddings into single token vectors
# Holds the list of 12 layer embeddings for each token
# Will have the shape: [# tokens, # layers, # features]
token_embeddings = []
# For each token in the sentence...
for token_i in range(len(tokenized_text)):
# Holds 12 layers of hidden states for each token
hidden_layers = []
# For each of the 12 layers...
for layer_i in range(len(encoded_layers)):
# Lookup the vector for `token_i` in `layer_i`
vec = encoded_layers[layer_i][batch_i][token_i]
hidden_layers.append(vec)
token_embeddings.append(hidden_layers)
# Sanity check the dimensions:
print ("Number of tokens in sequence:", len(token_embeddings))
print ("Number of layers per token:", len(token_embeddings[0]))
Number of tokens in sequence: 22
Number of layers per token: 12
从隐藏状态创建单词和句子向量
现在,我们如何处理这些隐藏的状态? 我们希望为每个token获取单独的向量,或者可能是整个句子的单个向量表示,但是对于我们输入的每个token,我们有12个单独的向量,每个向量的长度为768
为了获得单个向量,我们需要组合一些层向量......但哪个层或层组合提供了最佳表示? BERT作者通过将不同的向量组合作为输入特征输送到用于命名实体识别任务的BiLSTM并观察得到的F1分数来测试这一点。
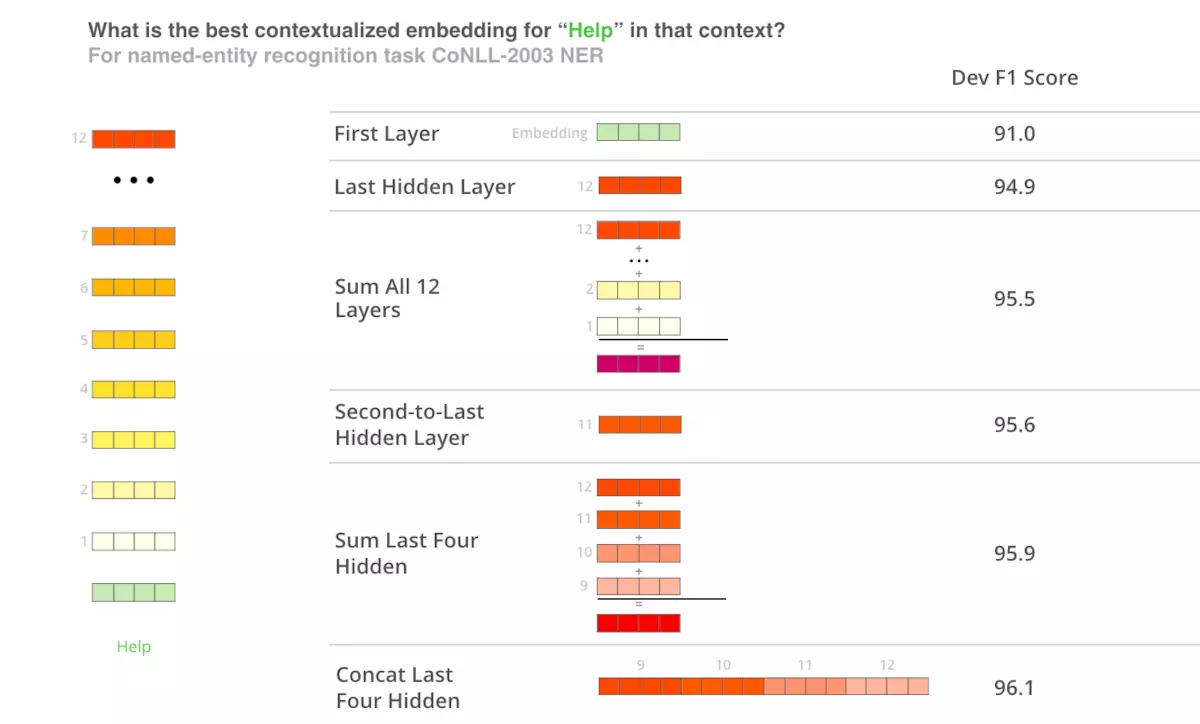
image.png
虽然最后四层的连接在这个特定任务上产生了最好的结果,但许多其他方法紧随其后,一般来说,建议为您的特定应用测试不同的版本:结果可能会有所不同。通过注意BERT的不同层编码非常不同类型的信息来部分地证明这一点,因此适当的池化策略将根据应用而改变,因为不同的层编码不同类型的信息。
注意到bert的不同层编码的信息种类非常不同,因此适当的池化策略将根据应用而改变,因为不同层编码的信息种类不同。韩晓对这一主题的讨论是相关的,他们的实验也是如此,他们的实验研究了在新闻数据集上训练的不同层次的PCA可视化,并从不同的池化策略中观察四类分离的差异:

image.png

image.png
结果是,正确的池化策略(平均值,最大值,连接数等)和使用的层(最后四个,全部,最后一层等)取决于应用。 这种对池化策略的讨论既适用于整个句子嵌入,也适用于类似ELMO的token嵌入。
词向量
为了给您提供一些示例,让我们使用最后四层的串联和求和来创建单词向量:
concatenated_last_4_layers = [torch.cat((layer[-1], layer[-2], layer[-3], layer[-4]), 0) for layer in token_embeddings] # [number_of_tokens, 3072]
summed_last_4_layers = [torch.sum(torch.stack(layer)[-4:], 0) for layer in token_embeddings] # [number_of_tokens, 768]
句向量
为了获得整个句子的单个向量,我们有多个依赖于应用的策略,但是一个简单的方法是平均每个token的倒数第二层,产生一个768长度向量。
sentence_embedding = torch.mean(encoded_layers[11], 1)
print ("Our final sentence embedding vector of shape:"), sentence_embedding[0].shape[0]
Our final sentence embedding vector of shape:
(None, 768)
确认上下文相关的向量
为了确认这些向量的值实际上是上下文相关的,让我们来看下一句话的输出(如果您想尝试这个方法,您必须从顶部单独运行这个例子,用下面的句子替换原始句子):
print (text)
After stealing money from the bank vault, the bank robber was seen fishing on the Mississippi river bank.
for i,x in enumerate(tokenized_text):
print (i,x)
0 [CLS]
1 after
2 stealing
3 money
4 from
5 the
6 bank
7 vault
8 ,
9 the
10 bank
11 robber
12 was
13 seen
14 fishing
15 on
16 the
17 mississippi
18 river
19 bank
20 .
21 [SEP]
print ("First fifteen values of 'bank' as in 'bank robber':")
summed_last_4_layers[10][:15]
First fifteen values of 'bank' as in 'bank robber':
tensor([ 1.1868, -1.5298, -1.3770, 1.0648, 3.1446, 1.4003, -4.2407, 1.3946,-0.1170, -1.8777, 0.1091, -0.3862, 0.6744, 2.1924, -4.5306])
print ("First fifteen values of 'bank' as in 'bank vault':")
summed_last_4_layers[6][:15]
First fifteen values of 'bank' as in 'bank vault':
tensor([ 2.1319, -2.1413, -1.6260, 0.8638, 3.3173, 0.1796, -4.4853, 3.1215, -0.9740, -3.1780, 0.1046, -1.5481, 0.4758, 1.1703, -4.4859])
print ("First fifteen values of 'bank' as in 'river bank':")
summed_last_4_layers[19][:15]
First fifteen values of 'bank' as in 'river bank':
tensor([ 1.1295, -1.4725, -0.7296, -0.0901, 2.4970, 0.5330, 0.9742, 5.1834, -1.0692, -1.5941, 1.9261, 0.7119, -0.9809, 1.2127, -2.9812])
正如我们所看到的,这些都是不同的向量。虽然“bank”这个词是相同的,但在我们句子的每一个案例中,它都有不同的含义,有时意义却截然不同。在这句话中我们有三种不同的“银行”用法,其中两种应该几乎相同。 让我们检查余弦相似度,看看是否是这种情况:
from sklearn.metrics.pairwise import cosine_similarity
# Compare "bank" as in "bank robber" to "bank" as in "river bank"
different_bank = cosine_similarity(summed_last_4_layers[10].reshape(1,-1), summed_last_4_layers[19].reshape(1,-1))[0][0]
# Compare "bank" as in "bank robber" to "bank" as in "bank vault"
same_bank = cosine_similarity(summed_last_4_layers[10].reshape(1,-1), summed_last_4_layers[6].reshape(1,-1))[0][0]
print ("Similarity of 'bank' as in 'bank robber' to 'bank' as in 'bank vault':", same_bank)
Similarity of 'bank' as in 'bank robber' to 'bank' as in 'bank vault': 0.94567525
print ("Similarity of 'bank' as in 'bank robber' to 'bank' as in 'river bank':", different_bank)
Similarity of 'bank' as in 'bank robber' to 'bank' as in 'river bank': 0.6797334
其他:特殊token,OOV词和相似性指标
特殊的tokens
应该注意的是,尽管“[CLS]”充当分类任务的“聚合表示”,但这不是高质量句子嵌入向量的最佳选择。 根据BERT作者Jacob Devlin的说法:
“我不确定这些向量是什么,因为BERT不会生成有意义的句子向量。 似乎这是在对单词标记进行平均汇总以获得句子向量,但我们从未建议这将产生有意义的句子表示。“
(但是,如果对模型进行了微调,则[CLS]token确实有意义,其中此token的最后一个隐藏层用作序列分类的“句子向量”。)
词汇表外的词
对于由多个句子和字符级embeddings组成的词汇外单词,关于如何最好地恢复此embeddings,还有一个更进一步的问题。 对embeddings进行平均是最直接的解决方案(在类似的embeddings模型中依赖的一个,具有子字词汇表,如fasttext),但是对于子词embeddings的和以及简单地采用最后一个token的embeddings(请记住向量是上下文敏感的)是可接受的替代策略。
相似度量
值得注意的是,单词级的相似性比较不适合于bert embeddings,因为这些嵌入是上下文相关的,这意味着单词向量会根据它出现的句子而变化。这就允许了一些奇妙的事情,比如说,你的表示编码河流“bank”而不是一个金融机构“bank”,使得直接的字词相似度比较不那么有价值。但是,对于句子embeddings的相似性比较仍然有效,例如,可以针对其他句子的数据集查询单个句子,以便找到最相似的句子。根据所使用的相似度度量,由于许多相似度度量对向量空间(例如,等量加权维)进行假设,而这些向量空间不适用于768维,因此产生的相似度值将比相似度输出的相对排名信息更少。
实现
您可以使用此notebook中的代码作为您自己的应用程序的基础,从文本中提取BERT功能。 然而,官方的tensorflow和备受好评的pytorch实现已经存在,为您做到这一点。 此外,bert-as-a-service是专为高性能运行此任务而设计的出色工具,也是我推荐用于生产应用程序的工具。 作者在该工具的实现中非常谨慎,并提供了优秀的文档(其中一些用于帮助创建本教程),以帮助用户了解用户面临的更细微的细节,如资源管理和池化策略。
作者:夕宝爸爸
链接:https://www.jianshu.com/p/a41392ece1ba
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。