han模型理解
一、han模型有两个重要特征,第一是分层,word-level层与sentence-level层,符合文档结构;第二个就是使用注意力机制(在加权时,可以根据内容赋予动态权重);
二、han模型如下:
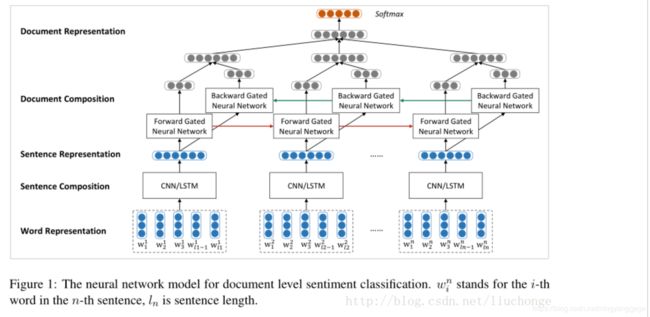
首先是one-hot的嵌入式表示,即embedding
然后再经过word-level编码层,这个有很多选择,论文中选择了双向GRU模型,得到每个word的编码
然后再经过注意力层计算出每个word编码的权值,用于线性加权;这里有个重点就是注意力层中Q,即图中的Uw,代表context vector,语义向量,是随机初始化的,不对应任何输入;V代表word的编码(GRU层输出的隐藏状态),K是将V经过一个FNN层的输出; 证明如原文的记录:
然后上面就完成了一个句子的编码;
然后多个句子组成输入,即基于sentence-level,经过编码层(双向GRU),(本质上和word-level一模一样),输出一个文档向量
最后,经过一个线性转换变成得分,再加softmax层输出分类概率值;如图所示(v是文档向量):

三、模型设置与训练:
a、先处理文本,分词化
b、使用word2vec模型训练得到word2vec矩阵;用于初始化han模型中嵌入层;嵌入层输出维度为200,编码层输出维度为100(每个方向各占50),语义向量维度也为100;
c、batchsize为64,动量值为0.9,学习率用grid search搜索得到;
四、han定义模型代码:
#coding=utf8
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.contrib import layers
def length(sequences):
used = tf.sign(tf.reduce_max(tf.abs(sequences), reduction_indices=2))
seq_len = tf.reduce_sum(used, reduction_indices=1)
return tf.cast(seq_len, tf.int32)
class HAN():
def __init__(self, vocab_size, num_classes, embedding_size=200, hidden_size=50):
self.vocab_size = vocab_size
self.num_classes = num_classes
self.embedding_size = embedding_size
self.hidden_size = hidden_size
with tf.name_scope('placeholder'):
self.max_sentence_num = tf.placeholder(tf.int32, name='max_sentence_num')
self.max_sentence_length = tf.placeholder(tf.int32, name='max_sentence_length')
self.batch_size = tf.placeholder(tf.int32, name='batch_size')
#x的shape为[batch_size, 句子数, 句子长度(单词个数)],但是每个样本的数据都不一样,,所以这里指定为空
#y的shape为[batch_size, num_classes]
self.input_x = tf.placeholder(tf.int32, [None, None, None], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name='input_y')
#构建模型
word_embedded = self.word2vec()
sent_vec = self.sent2vec(word_embedded)
doc_vec = self.doc2vec(sent_vec)
out = self.classifer(doc_vec)
self.out = out
def word2vec(self):
with tf.name_scope("embedding"):
embedding_mat = tf.Variable(tf.truncated_normal((self.vocab_size, self.embedding_size)))
#shape为[batch_size, sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.nn.embedding_lookup(embedding_mat, self.input_x)
return word_embedded
def sent2vec(self, word_embedded):
with tf.name_scope("sent2vec"):
#GRU的输入tensor是[batch_size, max_time, ...].在构造句子向量时max_time应该是每个句子的长度,所以这里将
#batch_size * sent_in_doc当做是batch_size.这样一来,每个GRU的cell处理的都是一个单词的词向量
#并最终将一句话中的所有单词的词向量融合(Attention)在一起形成句子向量
#shape为[batch_size*sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.reshape(word_embedded, [-1, self.max_sentence_length, self.embedding_size])
#shape为[batch_size*sent_in_doce, word_in_sent, hidden_size*2]
word_encoded = self.BidirectionalGRUEncoder(word_embedded, name='word_encoder')
#shape为[batch_size*sent_in_doc, hidden_size*2]
sent_vec = self.AttentionLayer(word_encoded, name='word_attention')
return sent_vec
def doc2vec(self, sent_vec):
with tf.name_scope("doc2vec"):
sent_vec = tf.reshape(sent_vec, [-1, self.max_sentence_num, self.hidden_size*2])
#shape为[batch_size, sent_in_doc, hidden_size*2]
doc_encoded = self.BidirectionalGRUEncoder(sent_vec, name='sent_encoder')
#shape为[batch_szie, hidden_szie*2]
doc_vec = self.AttentionLayer(doc_encoded, name='sent_attention')
return doc_vec
def classifer(self, doc_vec):
with tf.name_scope('doc_classification'):
out = layers.fully_connected(inputs=doc_vec, num_outputs=self.num_classes, activation_fn=None)
return out
def BidirectionalGRUEncoder(self, inputs, name):
#输入inputs的shape是[batch_size, max_time, voc_size]
with tf.variable_scope(name):
GRU_cell_fw = rnn.GRUCell(self.hidden_size)
GRU_cell_bw = rnn.GRUCell(self.hidden_size)
#fw_outputs和bw_outputs的size都是[batch_size, max_time, hidden_size]
((fw_outputs, bw_outputs), (_, _)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=GRU_cell_fw,
cell_bw=GRU_cell_bw,
inputs=inputs,
sequence_length=length(inputs),
dtype=tf.float32)
#outputs的size是[batch_size, max_time, hidden_size*2]
outputs = tf.concat((fw_outputs, bw_outputs), 2)
return outputs
def AttentionLayer(self, inputs, name):
#inputs是GRU的输出,size是[batch_size, max_time, encoder_size(hidden_size * 2)]
with tf.variable_scope(name):
# u_context是上下文的重要性向量,用于区分不同单词/句子对于句子/文档的重要程度,
# 因为使用双向GRU,所以其长度为2×hidden_szie
u_context = tf.Variable(tf.truncated_normal([self.hidden_size * 2]), name='u_context')
#使用一个全连接层编码GRU的输出的到期隐层表示,输出u的size是[batch_size, max_time, hidden_size * 2]
h = layers.fully_connected(inputs, self.hidden_size * 2, activation_fn=tf.nn.tanh)
#shape为[batch_size, max_time, 1]
alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1)
#reduce_sum之前shape为[batch_szie, max_time, hidden_szie*2],之后shape为[batch_size, hidden_size*2]
atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1)
return atten_output
五、训练代码:
#coding=utf-8
import tensorflow as tf
import time
import os
from data_helper import load_dataset
from HAN_model import HAN
# Data loading params
tf.flags.DEFINE_string("yelp_json_path", 'data/yelp_academic_dataset_review.json', "data directory")
tf.flags.DEFINE_integer("vocab_size", 46960, "vocabulary size")
tf.flags.DEFINE_integer("num_classes", 5, "number of classes")
tf.flags.DEFINE_integer("embedding_size", 200, "Dimensionality of character embedding (default: 200)")
tf.flags.DEFINE_integer("hidden_size", 50, "Dimensionality of GRU hidden layer (default: 50)")
tf.flags.DEFINE_integer("batch_size", 32, "Batch Size (default: 64)")
tf.flags.DEFINE_integer("num_epochs", 10, "Number of training epochs (default: 50)")
tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)")
tf.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("max_sent_in_doc", 30, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("max_word_in_sent", 30, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("evaluate_every", 100, "evaluate every this many batches")
tf.flags.DEFINE_float("learning_rate", 0.01, "learning rate")
tf.flags.DEFINE_float("grad_clip", 5, "grad clip to prevent gradient explode")
FLAGS = tf.flags.FLAGS
train_x, train_y, dev_x, dev_y = load_dataset(FLAGS.yelp_json_path, FLAGS.max_sent_in_doc, FLAGS.max_word_in_sent)
print "data load finished"
with tf.Session() as sess:
han = HAN(vocab_size=FLAGS.vocab_size,
num_classes=FLAGS.num_classes,
embedding_size=FLAGS.embedding_size,
hidden_size=FLAGS.hidden_size)
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=han.input_y,
logits=han.out,
name='loss'))
with tf.name_scope('accuracy'):
predict = tf.argmax(han.out, axis=1, name='predict')
label = tf.argmax(han.input_y, axis=1, name='label')
acc = tf.reduce_mean(tf.cast(tf.equal(predict, label), tf.float32))
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
global_step = tf.Variable(0, trainable=False)
optimizer = tf.train.AdamOptimizer(FLAGS.learning_rate)
# RNN中常用的梯度截断,防止出现梯度过大难以求导的现象
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), FLAGS.grad_clip)
grads_and_vars = tuple(zip(grads, tvars))
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
grad_summaries.append(grad_hist_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
loss_summary = tf.summary.scalar('loss', loss)
acc_summary = tf.summary.scalar('accuracy', acc)
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
feed_dict = {
han.input_x: x_batch,
han.input_y: y_batch,
han.max_sentence_num: 30,
han.max_sentence_length: 30,
han.batch_size: 64
}
_, step, summaries, cost, accuracy = sess.run([train_op, global_step, train_summary_op, loss, acc], feed_dict)
time_str = str(int(time.time()))
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, cost, accuracy))
train_summary_writer.add_summary(summaries, step)
return step
def dev_step(x_batch, y_batch, writer=None):
feed_dict = {
han.input_x: x_batch,
han.input_y: y_batch,
han.max_sentence_num: 30,
han.max_sentence_length: 30,
han.batch_size: 64
}
step, summaries, cost, accuracy = sess.run([global_step, dev_summary_op, loss, acc], feed_dict)
time_str = str(int(time.time()))
print("++++++++++++++++++dev++++++++++++++{}: step {}, loss {:g}, acc {:g}".format(time_str, step, cost, accuracy))
if writer:
writer.add_summary(summaries, step)
for epoch in range(FLAGS.num_epochs):
print('current epoch %s' % (epoch + 1))
for i in range(0, 200000, FLAGS.batch_size):
x = train_x[i:i + FLAGS.batch_size]
y = train_y[i:i + FLAGS.batch_size]
step = train_step(x, y)
if step % FLAGS.evaluate_every == 0:
dev_step(dev_x, dev_y, dev_summary_writer)代码来源:https://github.com/Irvinglove/HAN-text-classification/blob/master