图像分割之 deeplab v1,v2,v3,v3+系列解读
DeepLabv1:
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
ICLR 2015
官网:https://bitbucket.org/deeplab/deeplab-public.
优点:
- 速度快,带空洞卷积的基于VGG16基础结构的DCNN,可以达到8fps,而后处理的全连接CRF只需要0.5s。
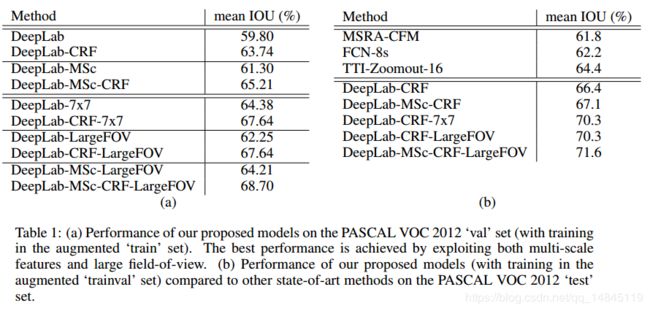
- 准确,取得了PASCAL VOC第一名的结果,高于第二名7.2%个点,在PASCAL VOC-2012测试集上达到71.6%的IOU准确性
- 简单,整个系统只包含DCNN和CRF两部分
空洞卷积(atrous conv):
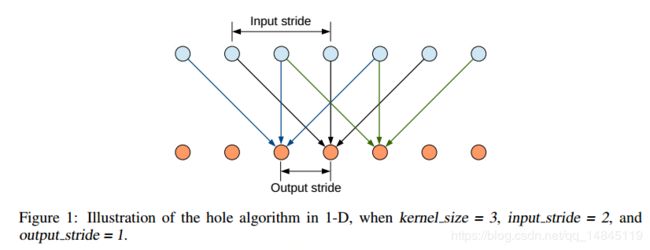
条件随机场CRF:
条件随机场可以优化物体的边界,平滑带噪声的分割结果,去掉物体中间的预测的孔洞,使得分割结果更加准确。
recovering object boundaries at a level of detail that is well beyond the reach of existing methods conditional random fields (CRFs) have been employed to smooth noisy segmentation maps

x是像素的标签分配。
P(xi)是像素i处的标签分配概率。
第一项θi是对数概率。
第二项,θij,它是一个滤波器。当xi != xj时,μ= 1。当xi = xj时,μ= 0。
在括号中,它是两个内核的加权和。第一个核取决于像素值差和像素位置差,这是一种双边的filter。双边滤波器具有保留边缘的特性。可以促使具有相似颜色和位置的像素具有相同的label预测。第二个内核仅取决于像素位置差异,这是一个高斯滤波器,可以促进更加平滑的预测。那些σ(高斯核大小)和w(权重),通过交叉验证找到。迭代次数为10。

多尺度预测:
多尺度预测也可以提升精度,但是没有CRF后处理提升的多
整体流程:

DeepLabv2:
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
TPAMI 2018
官网:http://liangchiehchen.com/projects/DeepLab.html
相对deeplab v1的主要改进:
1.使用ResNet101替代vgg16,做基础网络的改进,可以得到更好的准确性。

2.提出atrous spatial pyramid pooling (ASPP)来替代多尺度预测,可以大大增加感受野,感受野从普通卷积的k*k增大到(k + (k - 1)(r - 1))*(k + (k - 1)(r - 1))

3.PASCAL VOC-2012 测试集达到了79.7%的mIOU准确性

4.deeplab v2和deeplab v1一样,都有全连接的CRF后处理模块。
DeepLabv3:
Rethinking Atrous Convolution for Semantic Image Segmentation
Github:https://github.com/leonndong/DeepLabV3-Tensorflow
相对deeplab v2的主要改进:
1.网络变得更深,对Resnet101进行改进,在第4个block后面,重复的堆叠了3个第四个block模块,形成了block5, block6,block7模块。同时对网络结构的下采样率进行了调整,原始的Resnet101进行了5次下采样,而修改后的deeplab v3只进行了4次下采样,从第三个block之后,就不需要进行下采样操作。

2.增加了基于cascade的spp模块。也就是block4, block5, block6,block7模块。
3.修改了ASPP模块,去掉了deeplab v2中ASPP模块中的rate=24的3*3卷积,增加了1*1卷积和全局pooling模块。也可以理解为将原始的rate=24的3*3卷积模块替换为1*1卷积模块。
为什么需要这样做呢?因为随着空洞卷积采样率变大,空洞卷积的权值就会变得稀疏,例如3*3的卷积核中,只有中间位置的权值有效,其余的都变的很小,都不发挥作用了。因此效果上也就等价于1*1卷积了,所以可以使用1*1卷积替代rate=24的3*3空洞卷积。
as the sampling rate becomes larger, the number of valid filter weights (i.e., the weights that are applied to the valid feature region, instead of padded zeros) becomes smaller

4.去掉了DenseCRF后处理模块
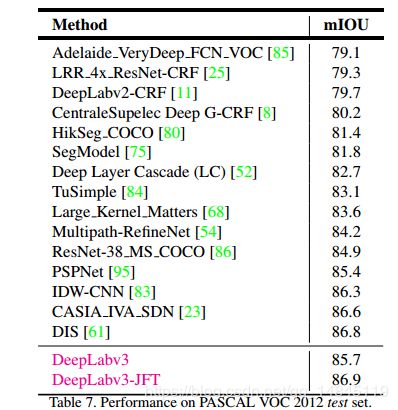
5.PASCAL VOC-2012 测试集达到了86.9%的mIOU准确性
DeepLabv3+:
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Github:https://github.com/tensorflow/models/tree/master/research/deeplab
https://github.com/rishizek/tensorflow-deeplab-v3-plus
相对deeplab v3的主要改进:
1.网络结构增加了decoder模块,整体结构变成Encoder-Decoder模块。

a图为deeplab v2的结构,b图为Encoder-Decoder结构,c图将a,b图的结构进行了整和,也就是deeplab v3的结构。
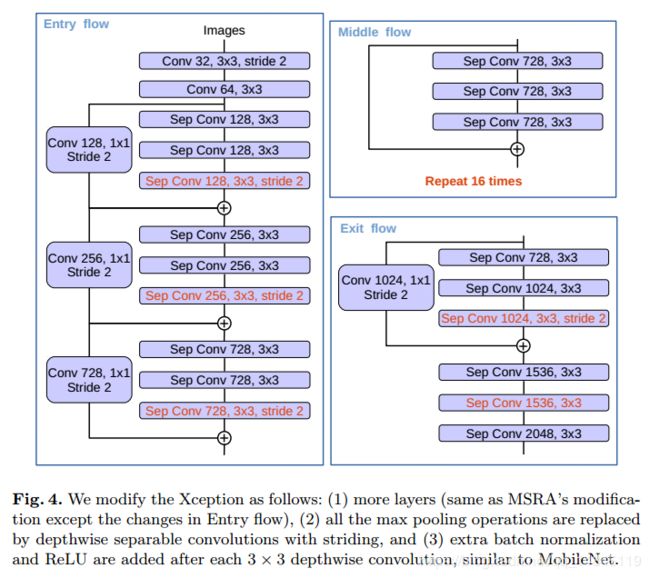
2.基础结构从Resnet101修改为Xception,这样引入了深度可分离卷积的思想,同时对其进行改进,将深度可分离卷积替代为空洞深度可分离卷积。可以获得比Resnet101更好的效果,更快的速度。
In particular, we explore the Xception model [26], similar to [31] for their COCO 2017 detection challenge submission, and show improvement in terms of both accuracy and speed for the task of semantic segmentation.

对Xception结构的改进主要有
a.深度进行了加深,Middle Flow从原始的重复8次变为重复16次
b.Max pooling换成了stride=2的深度可分离卷积
c.在3*3的深度可分离卷积后面增加BN+Relu
3.和v3版本一样,没有DenseCRF后处理模块。
4.PASCAL VOC-2012 测试集达到了89.0%的mIOU准确性。

整体结构:

另外,好多分割的框架中,数据增强这块都会有一个_IGNORE_LABEL = 255的问题,这个是为什么呢?
因为语义分割的时候,背景类别也是一个类别,网络训练的时候一般都是固定输入大小的,数据增强有crop,resize,padding操作,padding的时候补的是0,并且padding的像素是不希望计算loss的。因此,为了达到这个目的,实际操作的时候,首先,将label-_IGNORE_LABEL,然后再做padding=0操作,然后再label+_IGNORE_LABEL,这样就可以通过忽略255的像素值,达到忽略padding的像素的目的。
def random_crop_or_pad_image_and_label(image, label, crop_height, crop_width, ignore_label):
"""Crops and/or pads an image to a target width and height.
Resizes an image to a target width and height by rondomly
cropping the image or padding it evenly with zeros.
Args:
image: 3-D Tensor of shape `[height, width, channels]`.
label: 3-D Tensor of shape `[height, width, 1]`.
crop_height: The new height.
crop_width: The new width.
ignore_label: Label class to be ignored.
Returns:
Cropped and/or padded image.
If `images` was 3-D, a 3-D float Tensor of shape
`[new_height, new_width, channels]`.
"""
label = label - ignore_label # Subtract due to 0 padding.
label = tf.to_float(label)
image_height = tf.shape(image)[0]
image_width = tf.shape(image)[1]
image_and_label = tf.concat([image, label], axis=2)
image_and_label_pad = tf.image.pad_to_bounding_box(
image_and_label, 0, 0,
tf.maximum(crop_height, image_height),
tf.maximum(crop_width, image_width))
image_and_label_crop = tf.random_crop(
image_and_label_pad, [crop_height, crop_width, 4])
image_crop = image_and_label_crop[:, :, :3]
label_crop = image_and_label_crop[:, :, 3:]
label_crop += ignore_label
label_crop = tf.to_int32(label_crop)
return image_crop, label_crop整体总结:
提升分割精度的方法,
- 空洞卷积提高感受野(large field-of-view,LargeFOV)
- 多尺度预测(MSc)
- 条件随机场(CRF)
- 基于并行或者cascade的空洞空间金字塔(ASPP),可以获得不同尺度的更丰富的纹理信息。
- 更深的网络结构,Xception比resnet101效果更好,速度更快,
- Encoder-Decoder结构,decoder模块可以获得更好的边界分割效果