Python爬虫(十)——股票定向爬虫
文章目录
- Python爬虫(十)——股票定向爬虫
- 候选网站
- 选择
- 程序的结构设计
- 步骤
- 方法
- getHTMLText(url, code='utf-8')
- getStockList(lst, stockUrl)
- getStockInfo(lst, stockUrl)
- 完整代码
Python爬虫(十)——股票定向爬虫
- 目标:获取上交所和深交所的所有股票的名称和交易信息
- 输出:保存到文件中
- 技术路线:requests-bs4-re
候选网站
新浪股票:http://finance.sina.com.cn/stock/
百度股票:http://gupiao.baidu.com/stock/
选择
- 选取原则:股票信息静态存在于HTML页面中,非js代码生成,没有Robots协议限制。
- 选取方法:通过开发者模式或查看源代码。
- 选取心态:多找几个网站尝试。
因此我们观察新浪的网页代码,发现股票的信息都是引用的js代码,然后百度股票已经关闭了网页版。所以我们在查阅了其他各种股票网站以后选择了中财网这个网站(http://quote.cfi.cn/)。
程序的结构设计
步骤
- 从东方财富网获取股票列表
- 根据股票列表逐个到中财网获取个股信息
- 将结果存储到文件
方法
getHTMLText(url, code=‘utf-8’)
在这里我们预设encoding为’utf-8’从而节省判断编码的时间。
代码:
def getHTMLText(url, code='utf-8'):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = code # 判断编码时间会消耗很多时间,所以我们提前去网站上了解编码类型
return r.text
except:
return ""
getStockList(lst, stockUrl)
我们先得到股票列表。通过观察网页源代码,我们发现上证和深证的股票编码可以用以下的正则表达式表示:
r'[s][hz]\d{6}'
然后我们查询网站的编码类型:

代码:
def getStockList(lst, stockUrl):
html = getHTMLText(stockUrl, 'GB2312') # 填上在网页代码中看到的编码方式
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}', href)[0][2:])
except:
continue
getStockInfo(lst, stockUrl)
最后我们对股票列表中的股票进行查询后提取股票的信息。这时我们需要在网页代码中找到我们需要的信息。我们发现整个股票的信息都在一个table中:
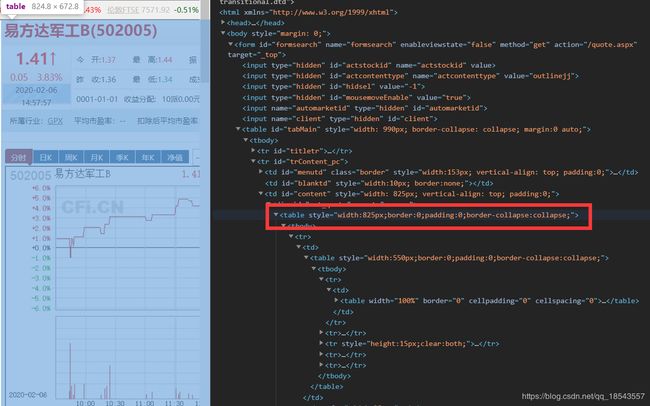
进一步观察发现股票名字在一个class='Lfont’的标签中:

而其他的信息都在一个class='Rlist’的标签中:
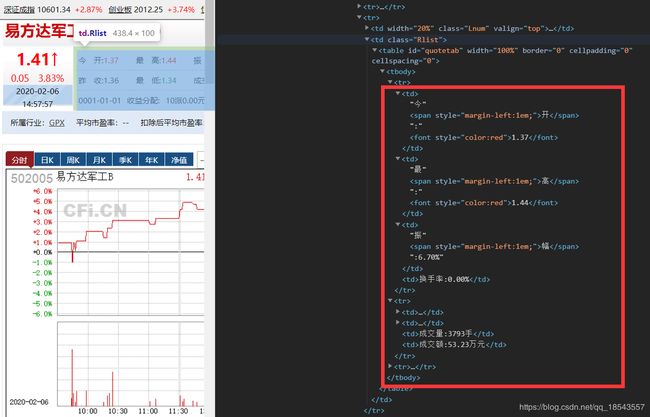
在充分了解相关信息的name和attrs后,我们利用BeautifulSoup提取出相关信息再将其存入excel表格中。
代码:
def getStockInfo(lst, stockUrl):
count = 0
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('股票')
ws.write(0, 0, label='股票名称')
ws.write(0, 1, label='信息')
for stock in lst:
url = stockUrl+stock+'.html' # 得到每个股票代码的网页
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('table', attrs={
'style': 'width:550px;border:0;padding:0;border-collapse:collapse;'})
if stockInfo:
name = stockInfo.find('div', attrs={'class': 'Lfont'})
infoDict.update({'股票名称': name.text})
table = stockInfo.find('td', attrs={'class': 'Rlist'})
keyList = table.find_all('td')
key = ''
for td in keyList:
key = key+(td.text+'\n')
infoDict['信息'] = key
count += 1
ws.write(count, 0, label=infoDict['股票名称'])
ws.write(count, 1, label=infoDict['信息'])
print('\r当前进度:{:.2f}&'.format(count*100/len(lst)),
end='') # /r能够将打印的光标提到行首
except:
print('\r当前进度:{:.2f}&'.format(count*100/len(lst)), end='')
traceback.print_exc()
continue
wb.save('股票.xls')
完整代码
import requests
from bs4 import BeautifulSoup
import traceback
import re
import xlwt
def getHTMLText(url, code='utf-8'):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = code # 判断编码时间会消耗很多时间,所以我们提前去网站上了解编码类型
return r.text
except:
return ""
def getStockList(lst, stockUrl):
html = getHTMLText(stockUrl, 'GB2312') # 填上在网页代码中看到的编码方式
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}', href)[0][2:])
except:
continue
def getStockInfo(lst, stockUrl):
count = 0
wb = xlwt.Workbook(encoding='utf-8') # 新建一个workbook
ws = wb.add_sheet('股票') # 新建一个worksheet
ws.write(0, 0, label='股票名称')
ws.write(0, 1, label='信息')
for stock in lst:
url = stockUrl+stock+'.html' # 得到每个股票代码的网页
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('table', attrs={
'style': 'width:550px;border:0;padding:0;border-collapse:collapse;'})
if stockInfo:
name = stockInfo.find('div', attrs={'class': 'Lfont'})
infoDict.update({'股票名称': name.text})
table = stockInfo.find('td', attrs={'class': 'Rlist'})
keyList = table.find_all('td')
key = ''
for td in keyList:
key = key+(td.text+'\n')
infoDict['信息'] = key
count += 1
ws.write(count, 0, label=infoDict['股票名称']) # 写入信息
ws.write(count, 1, label=infoDict['信息']) # 写入信息
print('\r当前进度:{:.2f}&'.format(count*100/len(lst)),
end='') # /r能够将打印的光标提到行首
except:
print('\r当前进度:{:.2f}&'.format(count*100/len(lst)), end='')
traceback.print_exc()
continue
wb.save('股票.xls') # 保存为股票.xls
stockListUrl = 'http://quote.eastmoney.com/stock_list.html'
stockInfoUrl = 'http://quote.cfi.cn/quote_'
slist = []
getStockList(slist, stockListUrl)
getStockInfo(slist, stockInfoUrl, fpath)
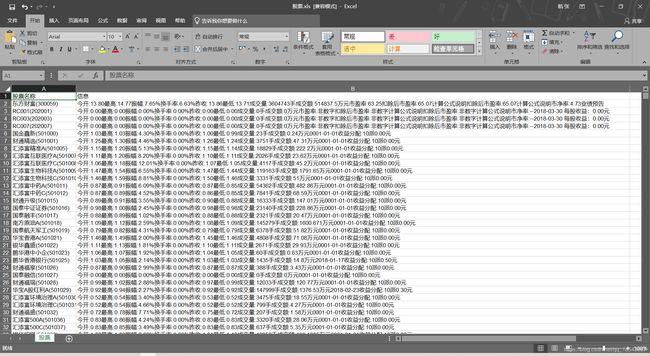
结果: