xv6源码分析(四):内存管理
xv6通过页表机制实现了对内存空间的控制。页表使得 xv6 能够让不同进程各自的地址空间映射到相同的物理内存上,还能够为不同进程的内存提供保护。 除此之外,我们还能够通过使用页表来间接地实现一些特殊功能。xv6 主要利用页表来区分多个地址空间,保护内存。另外,它也使用了一些简单的技巧,即把不同地址空间的多段内存映射到同一段物理内存(内核部分),在同一地址空间中多次映射同一段物理内存(用户部分的每一页都会映射到内核部分),以及通过一个没有映射的页保护用户栈。
预备知识
前面已经说过,在x86体系下,有三种地址,程序中各种符号地址为虚拟地址,CPU实际访问的内存地址为物理地址,x86体系下三种地址有以下关系:
虚拟地址-------->线性地址-------->物理地址
分段 分页在xv6中,除了每个CPU独立的数据具有非零的段基址外,其余包括内核数据段,内核代码段,用户数据段,用户代码段都是段基址为0的描述符,这样大大简化了地址转换操作和程序的编程,因为分段机制是由程序员控制,而分页机制是由操作系统负责的,在xv6中,可以简化为以下地址映射:
虚拟地址-------->物理地址
分页分页机制是通过页表来进行转换的,具体转换关系如图:

x86中所有的虚拟地址都经过页表来完成地址转换,页表由cr3寄存器指定的物理地址来表示,内存地址转换单元mmu通过查找页表来确定最后的物理地址,通过给cr3赋值便能实现不同进程拥有不同的页表,也就是不同进程拥有不同的地址空间。
页表由一级的页目录项和二级的页表项组成,每个页目录项下级有1024个连续的页表项(每个页表项4Byte,刚好占用4K空间,也就是一页),页目录项同时也是连续的,一共有1024个页目录项,由于32位系统地址线只有32位,所以最高支持4G的地址空间,页目录项也是连续的,所以页目录刚好也占用一页。
每个页目录项和页表项由下一级的物理地址和相关标志位组成,页目录项拥有下一级页表的物理地址,页表项拥有实际物理地址的部分,通过设置权限位可以实现内核和用户进程代码和数据的保护。
具体转换过程如图所示,虚拟地址前十位作为页目录的偏移找到页目录项,找到页表基地址,接下来十位作为页表项的偏移找到页表项,最后将页表项的基址+最后12位偏移得到实际的物理地址。
xv6内存初始化
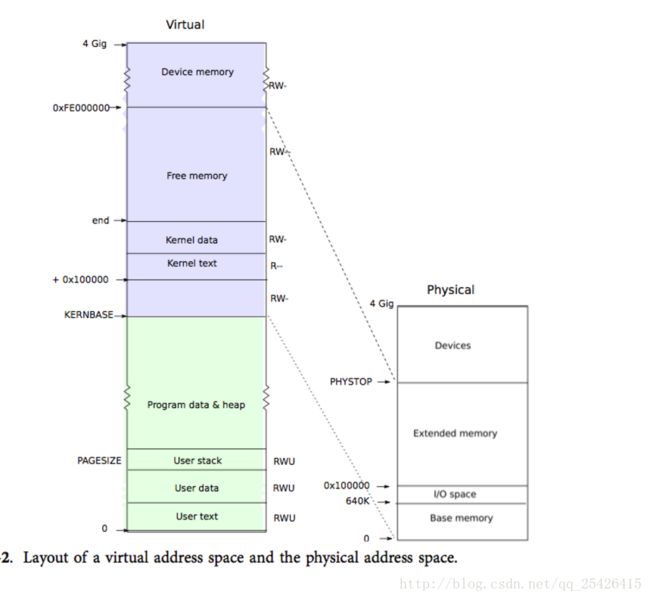
在初始化main函数最开始处,xv6具有以下的内存布局:
内核代码存在于物理地址低地址的0x100000处,页表为main.c文件中的entrypgdir数组,其中虚拟地址低4M映射物理地址低4M,虚拟地址 [KERNBASE, KERNBASE+4MB) 映射到 物理地址[0, 4MB)。可见现在内核实际能用的虚拟地址空间显然是不足以完成正常工作的,所以初始化过程中需要重新设置页表。
1.物理内存的初始化
xv6在main函数中调用kinit1和kinit2来初始化物理内存,kinit1初始化内核末尾到物理内存4M的物理内存空间为未使用
kinit1(end, P2V(4*1024*1024)); // phys page allocatorkinit2初始化剩余内核空间到PHYSTOP为未使用
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()两者的区别在于kinit1调用前使用的还是最初的页表(也就是是上面的内存布局),所以只能初始化4M,同时由于后期再构建新页表时也要使用页表转换机制来找到实际存放页表的物理内存空间,这就构成了自举问题,xv6通过在main函数最开始处释放内核末尾到4Mb的空间来分配页表,由于在最开始时多核CPU还未启动,所以没有设置锁机制。
initlock(&kmem.lock, "kmem");
kmem.use_lock = 0;
freerange(vstart, vend);kinit2在内核构建了新页表后,能够完全访问内核的虚拟地址空间,所以在这里初始化所有物理内存,并开始了锁机制保护空闲内存链表。
void
kinit2(void *vstart, void *vend)
{
freerange(vstart, vend);
kmem.use_lock = 1;
}2.内核新页表初始化
main函数通过调用kvmalloc函数来实现内核新页表的初始化
pde_t *kpgdir; // for use in scheduler()void
kvmalloc(void)
{
kpgdir = setupkvm();
switchkvm();
}通过初始化,最后内存布局和地址空间如下:
内核末尾物理地址到物理地址PHYSTOP的内存空间未使用
虚拟地址空间KERNBASE以上部分映射到物理内存低地址相应位置
// This table defines the kernel's mappings, which are present in
// every process's page table.
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};
物理内存管理
xv6对上层提供kalloc和kfree接口来管理物理内存,上层无需知道具体的细节,kalloc返回虚拟地址空间的地址,kfree以虚拟地址为参数,通过kalloc和kfree能够有效管理物理内存,让上层只需要考虑虚拟地址空间。
xv6通过将未分配的内存构成一个简单的链表来管理物理内存,具体的链表结构如下:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
int use_lock;
struct run *freelist;
} kmem;刚开始对于run结构的使用我很迷惑,其实xv6使用了空闲内存的前部分作为指针域来指向下一页空闲内存,物理内存管理是以页(4K)为单位进行分配的。也就是说物理内存空间上空闲的每一页,都有一个指针域(虚拟地址)指向下一个空闲页,最后一个空闲页为NULL
通过这种方式,只需要保存着虚拟地址空间上的freelist地址即可,kalloc和kfree操作的地址都是虚拟地址,那么为什么就能够准确找到每一物理页的位置呢,这是还是通过页表来完成的,仔细看内核映射布局
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory由此可知 VA’s [KERNBASE, KERNBASE+PHYSTOP) to PA’s [0, PHYSTOP),
所以可以想成就算kalloc和kfree操作的是虚拟地址,但是也能够总是准确找到每一页的位置,其实也不用关心kalloc和kfree是如何组织空闲页的,只要保证正确并能供上层调用即可,上层无需关心是如何实现的。上层调用的只需要想着“虚拟地址a对应的一页释放为空闲页”“分配一页返回虚拟地址给我”即可
有了上面的基础,很容易看懂kalloc和kfree的代码实现了
void
freerange(void *vstart, void *vend)
{
char *p;
p = (char*)PGROUNDUP((uint)vstart);
for(; p + PGSIZE <= (char*)vend; p += PGSIZE)
kfree(p);
}
void
kfree(char *v)
{
struct run *r;
if((uint)v % PGSIZE || v < end || V2P(v) >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(v, 1, PGSIZE);
if(kmem.use_lock)
acquire(&kmem.lock);
r = (struct run*)v;
r->next = kmem.freelist;
kmem.freelist = r;
if(kmem.use_lock)
release(&kmem.lock);
}
char*
kalloc(void)
{
struct run *r;
if(kmem.use_lock)
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
if(kmem.use_lock)
release(&kmem.lock);
return (char*)r;
}
通过kalloc和kfree,屏蔽了对物理内存的管理,使得调用者只需要关心虚拟地址空间,在需要使用新内存空间的时候调用kalloc,在需要释放内存空间的时候调用kfree
xv6内存管理函数
xv6通过提供几个接口来实现内核页表的控制和用户页表的控制,xv6让每个进程都有独立的页表结构,在切换进程时总是需要切换页表,切换页表的接口如下:
// Switch h/w page table register to the kernel-only page table,
// for when no process is running.
void
switchkvm(void)
{
lcr3(V2P(kpgdir)); // switch to the kernel page table
}
// Switch TSS and h/w page table to correspond to process p.
void
switchuvm(struct proc *p)
{
pushcli();
cpu->gdt[SEG_TSS] = SEG16(STS_T32A, &cpu->ts, sizeof(cpu->ts)-1, 0);
cpu->gdt[SEG_TSS].s = 0;
cpu->ts.ss0 = SEG_KDATA << 3;
cpu->ts.esp0 = (uint)proc->kstack + KSTACKSIZE;
// setting IOPL=0 in eflags *and* iomb beyond the tss segment limit
// forbids I/O instructions (e.g., inb and outb) from user space
cpu->ts.iomb = (ushort) 0xFFFF;
ltr(SEG_TSS << 3);
if(p->pgdir == 0)
panic("switchuvm: no pgdir");
lcr3(V2P(p->pgdir)); // switch to process's address space
popcli();
}
switchkvm简单地将kpgdir设置为cr3寄存器的值,这个页表仅仅在 scheduler内核线程中使用。
页表和内核栈都是每个进程独有的,xv6使用结构体proc将它们统一起来,在进程切换的时候,他们也往往随着进程切换而切换,内核中模拟出了一个内核线程,它独占内核栈和内核页表kpgdir,它是所有进程调度的基础。
switchuvm通过传入的proc结构负责切换相关的进程独有的数据结构,其中包括TSS相关的操作,然后将进程特有的页表载入cr3寄存器,完成设置进程相关的虚拟地址空间环境。
进程的页表在使用前往往需要初始化,其中必须包含内核代码的映射,这样进程在进入内核时便不需要再次切换页表,进程使用虚拟地址空间的低地址部分,高地址部分留给内核,设置页表时通过调用setupkvm、allocuvm、deallocuvm接口完成相关操作
setupkvm通过kalloc分配一页内存作为页目录,然后将按照kmap数据结构映射内核虚拟地址空间到物理地址空间。期间调用了工具函数mappages,mappages的具体实现下文再解释。
// Set up kernel part of a page table.
pde_t*
setupkvm(void)
{
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0)
return 0;
memset(pgdir, 0, PGSIZE);
if (P2V(PHYSTOP) > (void*)DEVSPACE)
panic("PHYSTOP too high");
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start,
(uint)k->phys_start, k->perm) < 0)
return 0;
return pgdir;
}allocuvm、deallocuvm负责完成用户进程的内存空间,allocuvm在设置页表的同时还会分配物理内存供用户进程使用allocuvm中的参数oldsz,newsz我没怎么搞懂为什么要这样命名,但是意思就是分配虚拟地址oldsz到newsz的以页为单位的内存,deallocuvm则相反,它将newsz到oldsz对应的虚拟地址空间内存置为空闲。
int
allocuvm(pde_t *pgdir, uint oldsz, uint newsz)
{
char *mem;
uint a;
if(newsz >= KERNBASE)
return 0;
if(newsz < oldsz)
return oldsz;
a = PGROUNDUP(oldsz);
for(; a < newsz; a += PGSIZE){
mem = kalloc();
if(mem == 0){
cprintf("allocuvm out of memory\n");
deallocuvm(pgdir, newsz, oldsz);
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(pgdir, (char*)a, PGSIZE, V2P(mem), PTE_W|PTE_U) < 0){
cprintf("allocuvm out of memory (2)\n");
deallocuvm(pgdir, newsz, oldsz);
kfree(mem);
return 0;
}
}
return newsz;
}
int
deallocuvm(pde_t *pgdir, uint oldsz, uint newsz)
{
pte_t *pte;
uint a, pa;
if(newsz >= oldsz)
return oldsz;
a = PGROUNDUP(newsz);
for(; a < oldsz; a += PGSIZE){
pte = walkpgdir(pgdir, (char*)a, 0);
if(!pte)
a += (NPTENTRIES - 1) * PGSIZE;
else if((*pte & PTE_P) != 0){
pa = PTE_ADDR(*pte);
if(pa == 0)
panic("kfree");
char *v = P2V(pa);
kfree(v);
*pte = 0;
}
}
return newsz;
}到了这里,xv6内存管理提供的主要接口也差不多了,两个切换接口,一个设置内核页表的接口,两个为用户进程管理内存,设置用户代码页表的接口,xv6 vm.c文件中还提供了loaduvm将文件系统上的i节点内容读取载入到相应的地址上,通过allocuvm接口为用户进程分配内存和设置页表,然后调用loaduvm接口将文件系统上的程序载入到内存,便能够为exec系统调用提供接口,为用户进程的正式运行做准备。
// Load a program segment into pgdir. addr must be page-aligned
// and the pages from addr to addr+sz must already be mapped.
int
loaduvm(pde_t *pgdir, char *addr, struct inode *ip, uint offset, uint sz)
{
uint i, pa, n;
pte_t *pte;
if((uint) addr % PGSIZE != 0)
panic("loaduvm: addr must be page aligned");
for(i = 0; i < sz; i += PGSIZE){
if((pte = walkpgdir(pgdir, addr+i, 0)) == 0)
panic("loaduvm: address should exist");
pa = PTE_ADDR(*pte);
if(sz - i < PGSIZE)
n = sz - i;
else
n = PGSIZE;
if(readi(ip, P2V(pa), offset+i, n) != n)
return -1;
}
return 0;
}vm.C中还有一个inituvm函数,为第一个进程所使用,通过调用它能够初始化虚拟地址为0的initcode.S的虚拟地址环境,initcode.S是独立于内核编译和链接的,它的加载地址和运行地址都为0。
// Load the initcode into address 0 of pgdir.
// sz must be less than a page.
void
inituvm(pde_t *pgdir, char *init, uint sz)
{
char *mem;
if(sz >= PGSIZE)
panic("inituvm: more than a page");
mem = kalloc();
memset(mem, 0, PGSIZE);
mappages(pgdir, 0, PGSIZE, V2P(mem), PTE_W|PTE_U);
memmove(mem, init, sz);
}当进程销毁需要回收内存时,可以调用freevm清除用户进程相关的内存环境,freevm首先调用deallocuvm将0到KERNBASE的虚拟地址空间回收,然后销毁整个进程的页表
// Free a page table and all the physical memory pages
// in the user part.
void
freevm(pde_t *pgdir)
{
uint i;
if(pgdir == 0)
panic("freevm: no pgdir");
deallocuvm(pgdir, KERNBASE, 0);
for(i = 0; i < NPDENTRIES; i++){
if(pgdir[i] & PTE_P){
char * v = P2V(PTE_ADDR(pgdir[i]));
kfree(v);
}
}
kfree((char*)pgdir);
}在vm.c中,copyuvm负责复制一个新的页表并分配新的内存,新的内存布局和旧的完全一样,xv6使用这个函数作为fork的底层实现
// Given a parent process's page table, create a copy
// of it for a child.
pde_t*
copyuvm(pde_t *pgdir, uint sz)
{
pde_t *d;
pte_t *pte;
uint pa, i, flags;
char *mem;
if((d = setupkvm()) == 0)
return 0;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walkpgdir(pgdir, (void *) i, 0)) == 0)
panic("copyuvm: pte should exist");
if(!(*pte & PTE_P))
panic("copyuvm: page not present");
pa = PTE_ADDR(*pte);
flags = PTE_FLAGS(*pte);
if((mem = kalloc()) == 0)
goto bad;
memmove(mem, (char*)P2V(pa), PGSIZE);
if(mappages(d, (void*)i, PGSIZE, V2P(mem), flags) < 0)
goto bad;
}
return d;
bad:
freevm(d);
return 0;
}
在vm.c的最后,还有两个函数,不过我还不清楚它有什么作用,其中uva2ka将一个用户地址转化为内核地址,也就是通过用户地址找到对应的物理地址,然后退出这个物理地址在内核页表中的虚拟地址并返回,copyout则调用uva2ka则拷贝p地址len字节到用户地址va中,这两个函数我不清楚到底是被谁调用的,先写在这里后面补充。
// Map user virtual address to kernel address.
char*
uva2ka(pde_t *pgdir, char *uva)
{
pte_t *pte;
pte = walkpgdir(pgdir, uva, 0);
if((*pte & PTE_P) == 0)
return 0;
if((*pte & PTE_U) == 0)
return 0;
return (char*)P2V(PTE_ADDR(*pte));
}
// Copy len bytes from p to user address va in page table pgdir.
// Most useful when pgdir is not the current page table.
// uva2ka ensures this only works for PTE_U pages.
int
copyout(pde_t *pgdir, uint va, void *p, uint len)
{
char *buf, *pa0;
uint n, va0;
buf = (char*)p;
while(len > 0){
va0 = (uint)PGROUNDDOWN(va);
pa0 = uva2ka(pgdir, (char*)va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (va - va0);
if(n > len)
n = len;
memmove(pa0 + (va - va0), buf, n);
len -= n;
buf += n;
va = va0 + PGSIZE;
}
return 0;
}总结
至此,xv6内存管理内容大致了解了,xv6对于物理内存的管理较为简单,只是将每一空闲页用链表链接起来,向上提供kalloc和kfree接口来屏蔽管理物理内存的细节,xv6将内存管理分为内核地址空间管理和用户地址空间管理,并提供几个函数供系统调用过程调用,很多需要管理内存的系统函数例如exec,fork都需要使用到这些接口,vm.c和kalloc.c包含了内存管理的大部分内容,系统调用过程使用这些函数来初始化和处理页表结构。