mysql limit优化(信息流方式) 大数据量
起因:
我们做了一个订单导出功能,大概流程是
1. 分页查询一些数据
2. 把查询到的数据聚合, 然后分片上传到OSS(阿里对象存储)上
3. 动态刷新临时数据(例如: 可以显示当前已经导出多少条等等)
问题
在使用mysql分页查询时, 使用的是默认的 limit 查询, 当分页的条数过大的时候,就会很慢
例如: select * from order limit 0, 500; -> 这条SQL应该是很快的
select * from order limit 500000,500; -> 这条SQL就会变的奇慢。
原因:
在mysql执行 limit 500000,500 时 ,mysql会先查询出 500500条, 然后再把前500000丢掉,
这就很逗比了...... ‘(*>﹏<*)′
解决方案
我们分析 limit 500000,500 变慢的真正原因是 它扫描了 500500行, 我们却只要500行,
那么我们能不能 直接让mysql查我们想要的500行数据呢?
----------
本菜鸡通过 "百度" 等渠道查询了一些资料,最终看到了一种类似是叫做信息流的查询方式, 来优化mysql的limit查询。
大概流程应该是这样的.
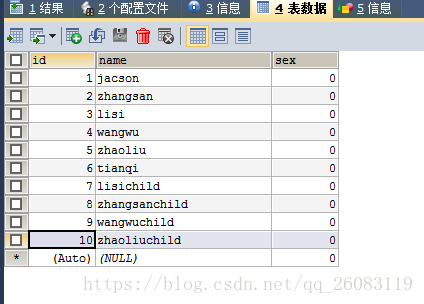
(这里以每页5条为例)
1. 先用普通方式查询5条数据 select * from member limit 5;
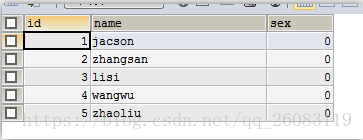
2. 然后获取 这5条的最后一条数据的 自增ID(这里可以是其它自定义的可排序的ID) 图片可以看到 ,
我们获取到最后一条数据的自增ID为 5 那么我们查询第二页的时候可以 这样写
select * from member where id > 5 limit 5;

这样我们就查询到了第二页的数据;
我们来比对一下 优化前: select * from member limit 5, 5;
优化后: select * from member where id > 5 limit 5;
优化前的语句 :mysql扫描了 10行,
优化后的语句 mysql 扫描了 5行 . 数据量少可能并不明显,如果limit 分页的 行数 过万的话就可以看出明显的差别.
但是----- emmmm
上面的方式对我们来说并不实用 , 因为我们的订单表 并没有设置类似与自增字段的东东。。。。
经过两只菜鸡反复思索了几个小时后, 我们发现,。 我们的订单表有创建时间 ,
我们可以通过创建时间来充当(自增字段)来做查询啊 。
但是... 我们想的太美好了, 我们的创建时间只精确到秒, 那么也就是 同一秒中可能会有多个订单,

所以上面的方式还需要优化才行.
我们看到上面的例子 是把e6给查出来了, 那么我们在查询的时候把e6排除掉是不是就可以了呢?
那么我们写SQL先把要排除的ID查出来, 我
们要查要排除的ID 我们需要上一页数据的 订单ID 和对应的创建时间
select order_id
from order
where create_time = '上一页最后一条信息的创建时间'
and order_id < '上一页最后一条信息的订单ID'
问题??? 为什么要写 order_id < '上一页最后一条信息的订单ID' 呢?
因为 在一列数据中,我们按照创建时间默认从小到大排序, 然而如果创建时间相同, 那么我们用order_id排序 因为我们要下某个订单id下的数据,
所以我们要把这个订单ID上的数据排除掉.
画个图:

最终方案:
SELECT
*
FROM
`seller_order_master_31`
WHERE `seller_order_master_31`.`order_id` NOT IN
-- 这个子查询是排除时间相同但是是不需要的数据
(SELECT
order_id
FROM
seller_order_master_31
-- 这个时间是上一页的最后一条数据的创建时间
WHERE `create_time` = '2018-09-13 15:13:02'
-- 这个订单ID是上一页最后一条数据的订单ID , 如果下面的 order by order_id 是正序排序,那么就是 <=
AND `order_id` >= '1809133530pdu00013739')
-- 这里order by create_time 是倒序排序, 所以是 <= 如果是正序排序那么就是>=
AND `seller_order_master_31`.`create_time` <= '2018-09-13 15:13:02'
-- 自定义条件
ORDER BY create_time DESC, order_id DESCLIMIT 500 ;

这里大概用这种方法和普通的分页进行测试:
用普通的limit 500000,50; 查询时间为 12S 用优化后的limit 查询用的0.056S ,
速度相差是乘指数上升 普通的limit 越查越慢, 而优化后的limit速度始终稳定在一个时间段上.
本菜鸡第一次写博客, 如果写的不好, 望各位读者体谅一下下 O(∩_∩)O. 如果有什么疑问,或者想一起研究, 欢迎留言!!!