【数学建模算法汇总】
目录
- 数学建模方法
- (一)预测与预报
- 灰色预测模型(必须掌握)
- 微分方程预测(备用)
- 回归分析预测(必须掌握)
- 马尔可夫预测(备用)
- 时间序列预测(必须掌握)
- 小波分析预测(备用)
- 神经网络预测(备用)
- 混沌序列预测(备用)
- (二)、评价与决策
- 模糊综合评判(必须掌握)
- 主成分分析(必须掌握)
- 层次分析法(AHP,必须掌握)
- 数据包络(EDA)分析法
- 秩和比综合评价法(必须掌握)
- 优劣解距离法(TOPSIS法)
- 投影寻踪综合评价法
- 方差分析、协方差分析等(必须掌握)
- (三)、分类与判别
- 1、距离聚类(系统聚类)(必须掌握)
- 2、关联性聚类(需掌握)
- 3、层次性据类
- 4、密度性聚类
- 5、其他聚类
- 6、贝叶斯判别(统计判别方法,必须掌握)
- 7、费舍尔判别(训练的样本点比较多,必须掌握)
- 8、模糊识别(分好类的数据点比较少)
- (四)、关联与因果
- 1、灰色关联分析方法(样本点的个数比较少)
- 2、Sperman或Kendall等级相关分析
- 3、Person相关(样本点的个数比较多)
- 4、Copula相关(比较难,金融数学、概率数学)
- 5、典型相关分析
- 6、标准化回归分析
- 7、生产分析(事件史分析)
- 8、格兰杰因果检验
- (五)、优化与控制
- 1、线性规划、整数规划、0-1规划(有约束,确定的目标)
- 2、非线性规划与智能优化算法
- 3、多目标规划和目标规划(柔性约束,目标函数,超过)
- 4、动态规划
- 5、网络优化(多因素交错复杂)
- 6、排队论与计算机仿真
- 7、模糊规划(范围约束)
- 8、灰色规划
- 9、退火算法(常用)
- 10、神经网络
- 11、遗传算法
数学建模方法
统计:
1、预测与预报
2、评价与决策
3、分类与判别
4、关联与因果
优化:
5、优化与控制
(一)预测与预报
灰色预测模型(必须掌握)
满足两个条件可用:
①数据样本点个数少,6-15个
②数据呈现指数或者曲线的形式
- 概述
关于所谓的“颜色”预测或者检测等,大致分为三色:黑、白、灰,在此以预测为例阐述。
其中,白色预测是指系统的内部特征完全已知,系统信息完全充分;黑色预测指系统的内部特征一无所知,只能通过观测其与外界的联系来进行研究;灰色预测则是介于黑、白两者之间的一种预测,一部分已知,一部分未知,系统因素间有不确定的关系。细致度比较:白>黑>灰。
-
原理
灰色预测是通过计算各因素之间的关联度,鉴别系统各因素之间发展趋势的相异程度。其核心体系是灰色模型(Grey Model,GM),即对原始数据做累加生成(或者累减、均值等方法)生成近似的指数规律在进行建模的方法。 -
分类及求解步骤
1、GM(1,1)与GM(2,1)、DGM、Verhulst模型的分类比较:
2.求解步骤思维导图:

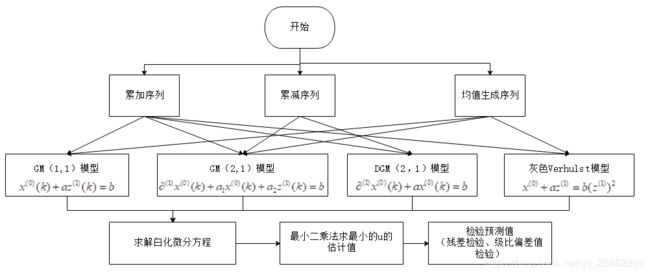
-
实例
1.使用GM(1,1)的预测检验“北方某城市1986年-1992年道路噪声交通 平均声级数据:”
见下图:
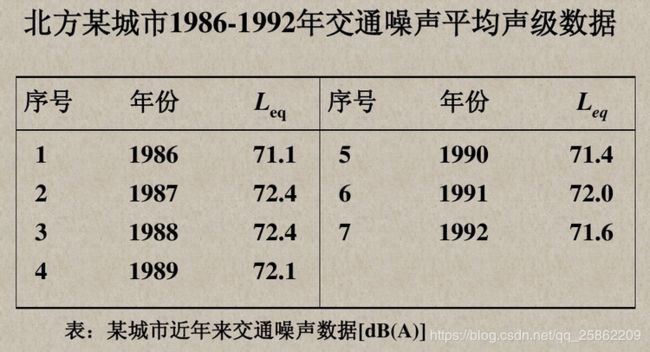
x0 = [71.1 72.4 72.4 72.1 71.4 72 71.6]'; %这里是列向量,相当于原始数据中因变量
n = length(x0);
lamda = x0(1:n-1)./x0(2:n) %计算级比
range = minmax(lamda') %计算级比的范围
x1 = cumsum(x0)
B = [-0.5*(x1(1:n-1)+x1(2:n)),ones(n-1,1)]; %这是构造的数据矩阵B
Y = x0(2:n); %数据向量Y
u = B\Y %拟合参数u(1)=a,u(2)=b
syms x(t)
x = dsolve(diff(x)+u(1)*x==u(2),x(0)==x0(1)); %建立模型求解
xt = vpa(x,6) %以小数格式显示微分方程的解
prediction1 = subs(x,t,[0:n-1]); %求已知数据的预测值
prediction1 = double(prediction1); %符号数转换成数值类型,以便做差分运算
prediction = [x0(1),diff(prediction1)] %差分运算,还原数据
epsilon = x0'-prediction %计算残差
delta = abs(epsilon./x0') %计算相对残差
rho = 1-(1-0.5*u(1))/(1+0.5*u(1))*lamda'%计算级比偏差值,u(1)=a
2.使用GM(2,1)的MATLAB实例:
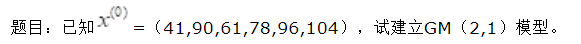
%% -------------2.GM(2,1)预测模型-------------------%%
x0 = [41 49 61 78 96 104];
n = length(x0);
add_x0 = cumsum(x0);%1次累加序列
minus_x0 = diff(x0)'; %1次累减序列
z = 0.5*(add_x0(2:end)+add_x0(1:end-1))';%计算均值生成序列
B = [-x0(2:end)',-z,ones(n-1,1)];
u = B\minus_x0 %最小二乘法拟合参数
syms x(t)
x = dsolve(diff(x,2)+u(1)*diff(x)+u(2)*x == u(3),x(0) == add_x0(1),x(5) == add_x0(6)); %求符号解
xt = vpa(x,6) %显示小数形式的符号解
prediction = subs(x,t,0:n-1);
prediction = double(prediction);
x0_prediction = [prediction(1),diff(prediction)];%求已知数据点的预测值
x0_prediction = round(x0_prediction) %四舍五入取整数
epsilon = x0-x0_prediction %求残差
delta = abs(epsilon./x0) %求相对误差
3.灰色预测模型GM(1,1)
GM(1,1).m
%建立符号变量a(发展系数)和b(灰作用量)
syms a b;
c = [a b]';
%原始数列 A
A = [174, 179, 183, 189, 207, 234, 220.5, 256, 270, 285];%填入已有的数据列!
n = length(A);
%对原始数列 A 做累加得到数列 B
B = cumsum(A);
%对数列 B 做紧邻均值生成
for i = 2:n
C(i) = (B(i) + B(i - 1))/2;
end
C(1) = [];
%构造数据矩阵
B = [-C;ones(1,n-1)];
Y = A; Y(1) = []; Y = Y';
%使用最小二乘法计算参数 a(发展系数)和b(灰作用量)
c = inv(B*B')*B*Y;
c = c';
a = c(1); b = c(2);
%预测后续数据
F = []; F(1) = A(1);
for i = 2:(n+10) %这里10代表向后预测的数目,如果只预测一个的话为1
F(i) = (A(1)-b/a)/exp(a*(i-1))+ b/a;
end
%对数列 F 累减还原,得到预测出的数据
G = []; G(1) = A(1);
for i = 2:(n+10) %10同上
G(i) = F(i) - F(i-1); %得到预测出来的数据
end
disp('预测数据为:');
G
%模型检验
H = G(1:10); %这里的10是已有数据的个数
%计算残差序列
epsilon = A - H;
%法一:相对残差Q检验
%计算相对误差序列
delta = abs(epsilon./A);
%计算相对误差Q
disp('相对残差Q检验:')
Q = mean(delta)
%法二:方差比C检验
disp('方差比C检验:')
C = std(epsilon, 1)/std(A, 1)
%法三:小误差概率P检验
S1 = std(A, 1);
tmp = find(abs(epsilon - mean(epsilon))< 0.6745 * S1);
disp('小误差概率P检验:')
P = length(tmp)/n
%绘制曲线图
t1 = 1995:2004;%用自己的,如1 2 3 4 5...
t2 = 1995:2014;%用自己的,如1 2 3 4 5...
plot(t1, A,'ro'); hold on;
plot(t2, G, 'g-');
xlabel('年份'); ylabel('污水量/亿吨');
legend('实际污水排放量','预测污水排放量');
title('长江污水排放量增长曲线'); %都用自己的
grid on;
- 参考
灰色预测模型及Matlab实例.
灰色预测模型GM(1,1).
微分方程预测(备用)
无法直接找到原始数据之间的关系,但可以找到原始数据变化速度之间的关系,通过公式推导转化为原始数据的关系。
微分方程建模是数学建模的重要方法,因为许多实际问题的数学描述将导致求解微分方程的定解问题。把形形色色的实际问题化成微分方程的定解问题,大体上可以按以下几步:
- 根据实际要求确定要研究的量(自变量、未知函数、必要的参数等)并确定坐标系。
- 找出这些量所满足的基本规律(物理的、几何的、化学的或生物学的等等)。
- 运用这些规律列出方程和定解条件。
列方程常见的方法有:
(i)按规律直接列方程
在数学、力学、物理、化学等学科中许多自然现象所满足的规律已为人们所熟悉,并直接由微分方程所描述。如牛顿第二定律、放射性物质的放射性规律等。我们常利用这些规律对某些实际问题列出微分方程。
(ii)微元分析法与任意区域上取积分的方法
自然界中也有许多现象所满足的规律是通过变量的微元之间的关系式来表达的。对于这类问题,我们不能直接列出变量和未知函数及其变化率之间的关系式,而是通过微元分析法,利用已知的规律建立一些变量(自变量与未知函数)的微元之间的关系式,然后再通过取极限的方法得到微分方程,或等价地通过任意区域上取积分的方法来建立微分方程。
(iii)模拟近似法
在生物、经济等学科中,许多现象所满足的规律并不很清楚而且相当复杂,因而需要根据实际资料或大量的实验数据,提出各种假设。在一定的假设下,给出实际现象所满足的规律,然后利用适当的数学方法列出微分方程。在实际的微分方程建模过程中,也往往是上述方法的综合应用。不论应用哪种方法,通常要根据实际情况,作出一定的假设与简化,并要把模型的理论或计算结果与实际情况进行对照验证,以修改模型使之更准确地描述实际问题并进而达到预测预报的目的。本章将利用上述方法讨论具体的微分方程的建模问题。



























clc,clear
syms m V rho g k
s=dsolve('m*D2s-m*g+rho*g*V+k*Ds','s(0)=0,Ds(0)=0');
s=subs(s,{m,V,rho,g,k},{239.46,0.2058,1035.71,9.8,0.6});
s=vpa(s,10) %求位移函数
v=dsolve('m*Dv-m*g+rho*g*V+k*v','v(0)=0');
v=subs(v,{m,V,rho,g,k},{239.46,0.2058,1035.71,9.8,0.6});
v=vpa(v,7) %求速度函数
y=s-90;
tt=solve(y) %求到达海底 90 米处的时间
vv=subs(v,tt) %求到底海底 90 米处的速度

回归分析预测(必须掌握)
求一个因变量与若干个自变量之间的关系,若自变量变化后,求因变量如何变化;
样本点的个数有要求:
①自变量之间的协方差比较小,最好趋近于0,自变量间的相关性小;
②样本点的个数n>3k+1,k为自变量的个数;
③因变量要符合正态分布




















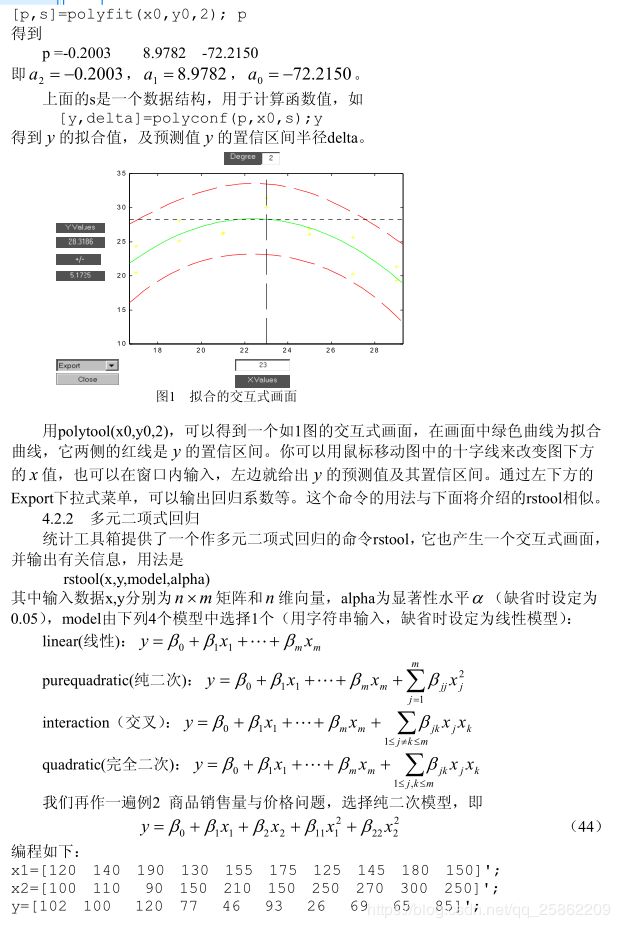

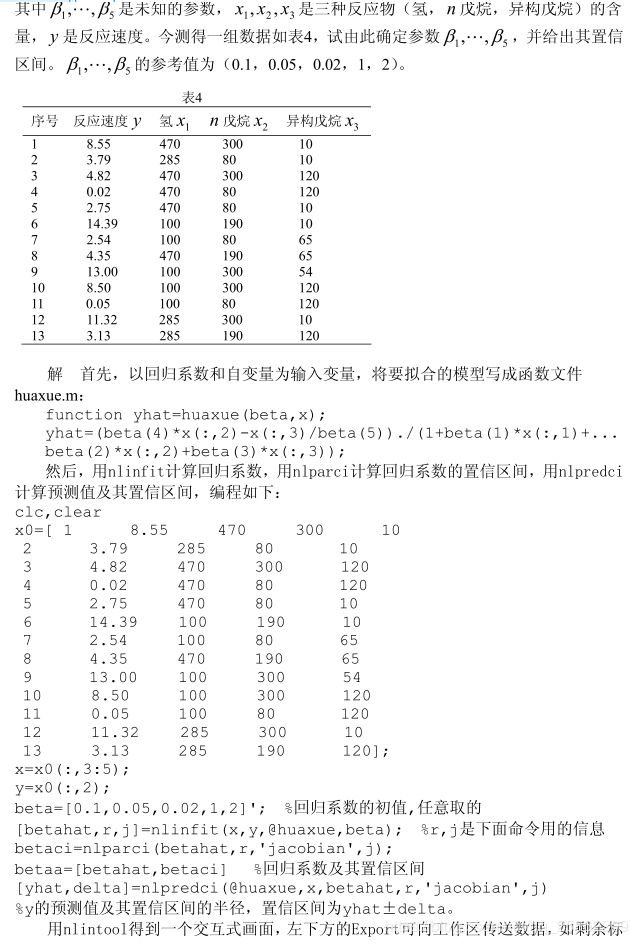

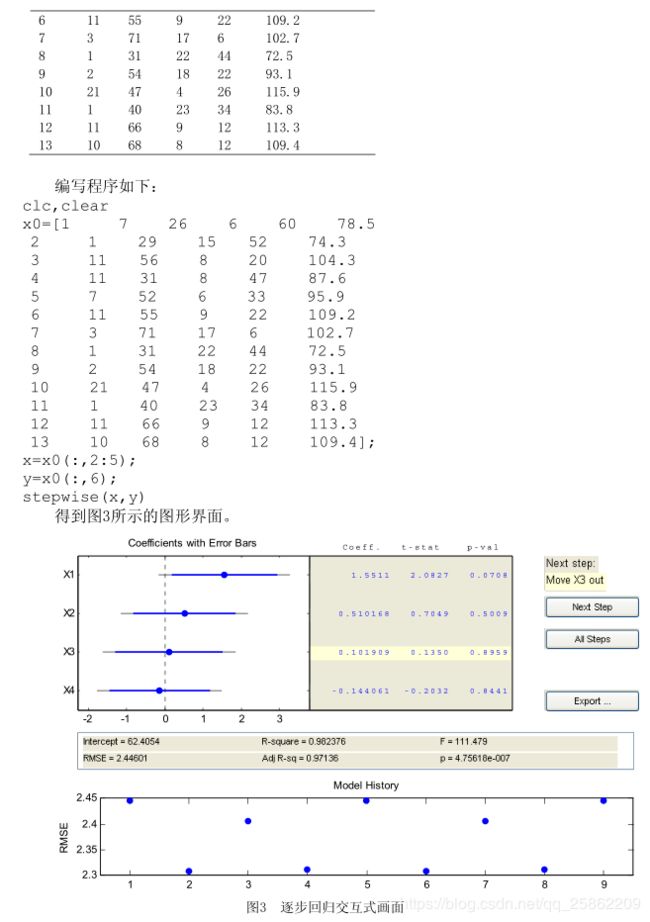
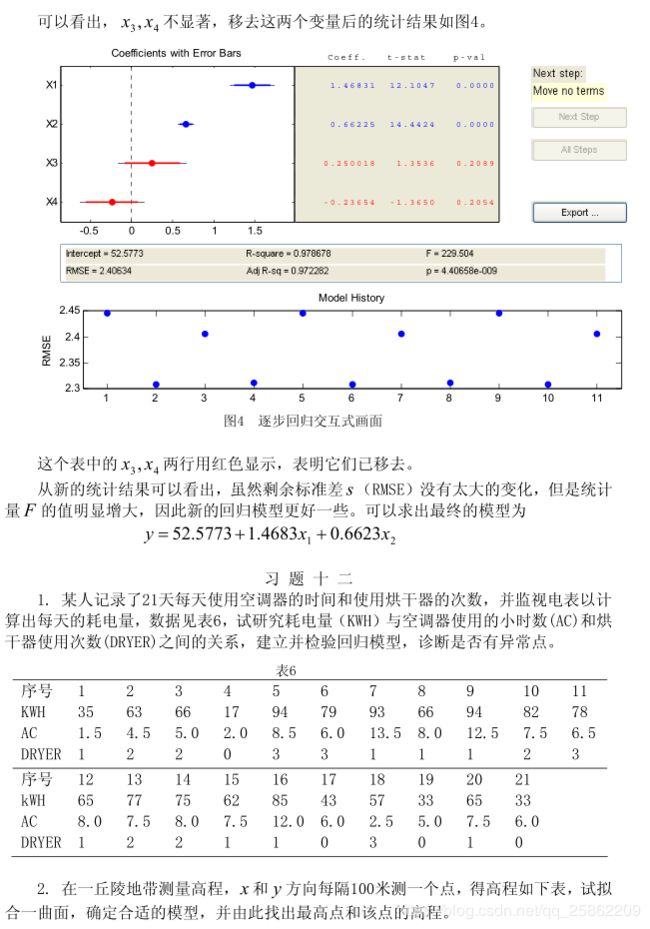
马尔可夫预测(备用)
一个序列之间没有信息的传递,前后没有联系,数据与数据之间的随机性强,相互不影响;今天的温度与昨天、后天没有直接联系,预测后天温度高、中、低的概率,只能得到概率




clc,clear
format rat
fid=fopen('data1.txt','r');
a=[];
while (~feof(fid))
a=[a fgetl(fid)];
end
for i=0:1
for j=0:1
s=[int2str(i),int2str(j)];
f(i+1,j+1)=length(findstr(s,a));
end
end
fs=sum(f');
for i=1:2
f(i,:)=f(i,:)/fs(i);
end







format rat
p=[0.8 0.1 0.1;0.5 0.1 0.4;0.5 0.3 0.2];
a=[p'-eye(3);ones(1,3)];
b=[zeros(3,1);1];
p_limit=a\b







时间序列预测(必须掌握)
与马尔可夫链预测互补,至少有两个点需要信息的传递,ARMA模型,周期模型,季节模型等






clc,clear
y=[533.8 574.6 606.9 649.8 705.1 772.0 816.4 892.7 963.9 1015.1
1102.7];
m=length(y);
n=[4,5]; %n 为移动平均的项数
for i=1:length(n)
%由于n 的取值不同,yhat 的长度不一致,下面使用了细胞数组
for j=1:m-n(i)+1
yhat{i}(j)=sum(y(j:j+n(i)-1))/n(i);
end
y12(i)=yhat{i}(end);
s(i)=sqrt(mean((y(n(i)+1:m)-yhat{i}(1:end-1)).^2));
end
y12,s


y=[6.35 6.20 6.22 6.66 7.15 7.89 8.72 8.94 9.28
9.8];
w=[1/6;2/6;3/6];
m=length(y);n=3;
for i=1:m-n+1
yhat(i)=y(i:i+n-1)*w;
end
yhat
err=abs(y(n+1:m)-yhat(1:end-1))./y(n+1:m)
T_err=1-sum(yhat(1:end-1))/sum(y(n+1:m))
y1989=yhat(end)/(1-T_err)




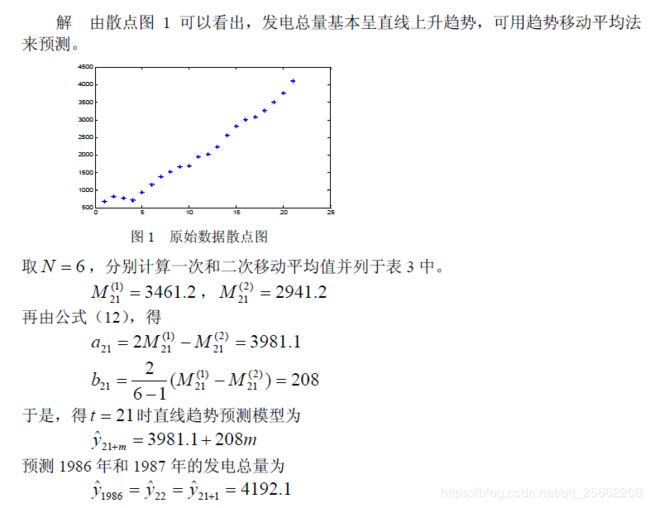







clc,clear
load fadian.txt %原始数据以列向量的方式存放在纯文本文件中
yt=fadian; n=length(yt);
alpha=0.3; st1(1)=yt(1); st2(1)=yt(1);
for i=2:n
st1(i)=alpha*yt(i)+(1-alpha)*st1(i-1);
st2(i)=alpha*st1(i)+(1-alpha)*st2(i-1);
end
xlswrite('fadian.xls',[st1',st2'])
a=2*st1-st2
b=alpha/(1-alpha)*(st1-st2)
yhat=a+b;
xlswrite('fadian.xls',yhat','Sheet1','C2')
str=char(['C',int2str(n+2)]);
xlswrite('fadian.xls',a(n)+2*b(n),'Sheet1',str)


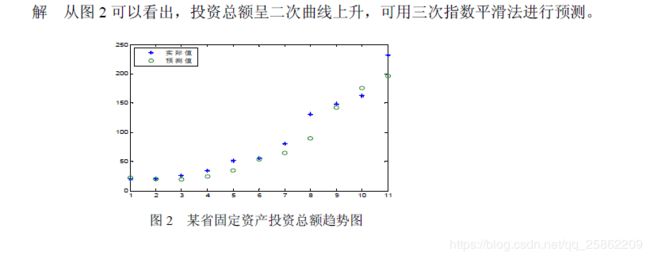

clc,clear
load touzi.txt %原始数据以列向量的方式存放在纯文本文件中
yt=touzi; n=length(yt);
alpha=0.3; st1_0=mean(yt(1:3)); st2_0=st1_0;st3_0=st1_0;
st1(1)=alpha*yt(1)+(1-alpha)*st1_0;
st2(1)=alpha*st1(1)+(1-alpha)*st2_0;
st3(1)=alpha*st2(1)+(1-alpha)*st3_0;
for i=2:n
st1(i)=alpha*yt(i)+(1-alpha)*st1(i-1);
st2(i)=alpha*st1(i)+(1-alpha)*st2(i-1);
st3(i)=alpha*st2(i)+(1-alpha)*st3(i-1);
end
xlswrite('touzi.xls',[st1',st2',st3'])
st1=[st1_0,st1];st2=[st2_0,st2];st3=[st3_0,st3];
a=3*st1-3*st2+st3;
b=0.5*alpha/(1-alpha)^2*((6-5*alpha)*st1-2*(5-4*alpha)*st2+(4-3*alpha)*st3);
c=0.5*alpha^2/(1-alpha)^2*(st1-2*st2+st3);
yhat=a+b+c;
xlswrite('touzi.xls',yhat','Sheet1','D1')
plot(1:n,yt,'*',1:n,yhat(1:n),'O')
legend('实际值','预测值',2)
xishu=[c(n+1),b(n+1),a(n+1)];
yhat1990=polyval(xishu,2)






































小波分析预测(备用)
数据无规律,海量数据,将波进行分离,分离出周期数据、规律性数据;可以做时间序列做不出的数据,应用范围比较广
- 小波的特点和发展
小波分析是分析原始信号各种变化的特性,进一步用于数据压缩,噪声去除,特征选择等。






神经网络预测(备用)
大量的数据,不需要模型,只需要输入和输出,黑箱处理,建议作为检验的办法


BP神经网络matlab源程序代码)
%******************************%
学习程序
%******************************%
%======原始数据输入========
p=[2845 2833 4488;2833 4488 4554;4488 4554 2928;4554 2928 3497;2928 3497 2261;...
3497 2261 6921;2261 6921 1391;6921 1391 3580;1391 3580 4451;3580 4451 2636;...
4451 2636 3471;2636 3471 3854;3471 3854 3556;3854 3556 2659;3556 2659 4335;...
2659 4335 2882;4335 2882 4084;4335 2882 1999;2882 1999 2889;1999 2889 2175;...
2889 2175 2510;2175 2510 3409;2510 3409 3729;3409 3729 3489;3729 3489 3172;...
3489 3172 4568;3172 4568 4015;]';
%===========期望输出=======
t=[4554 2928 3497 2261 6921 1391 3580 4451 2636 3471 3854 3556 2659 ...
4335 2882 4084 1999 2889 2175 2510 3409 3729 3489 3172 4568 4015 ...
3666];
ptest=[2845 2833 4488;2833 4488 4554;4488 4554 2928;4554 2928 3497;2928 3497 2261;...
3497 2261 6921;2261 6921 1391;6921 1391 3580;1391 3580 4451;3580 4451 2636;...
4451 2636 3471;2636 3471 3854;3471 3854 3556;3854 3556 2659;3556 2659 4335;...
2659 4335 2882;4335 2882 4084;4335 2882 1999;2882 1999 2889;1999 2889 2175;...
2889 2175 2510;2175 2510 3409;2510 3409 3729;3409 3729 3489;3729 3489 3172;...
3489 3172 4568;3172 4568 4015;4568 4015 3666]';
[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %将数据归一化
NodeNum1 =20; % 隐层第一层节点数
NodeNum2=40; % 隐层第二层节点数
TypeNum = 1; % 输出维数
TF1 = 'tansig';
TF2 = 'tansig';
TF3 = 'tansig';
net=newff(minmax(pn),[NodeNum1,NodeNum2,TypeNum],{TF1 TF2 TF3},'traingdx');
%网络创建traingdm
net.trainParam.show=50;
net.trainParam.epochs=50000; %训练次数设置
net.trainParam.goal=1e-5; %训练所要达到的精度
net.trainParam.lr=0.01; %学习速率
net=train(net,pn,tn);
p2n=tramnmx(ptest,minp,maxp);%测试数据的归一化
an=sim(net,p2n);
[a]=postmnmx(an,mint,maxt) %数据的反归一化 ,即最终想得到的预测结果
plot(1:length(t),t,'o',1:length(t)+1,a,'+');
title('o表示预测值--- *表示实际值')
grid on
m=length(a); %向量a的长度
t1=[t,a(m)];
error=t1-a; %误差向量
figure
plot(1:length(error),error,'-.')
title('误差变化图')
grid on
混沌序列预测(备用)
比较难掌握,数学功底要求要
(二)、评价与决策
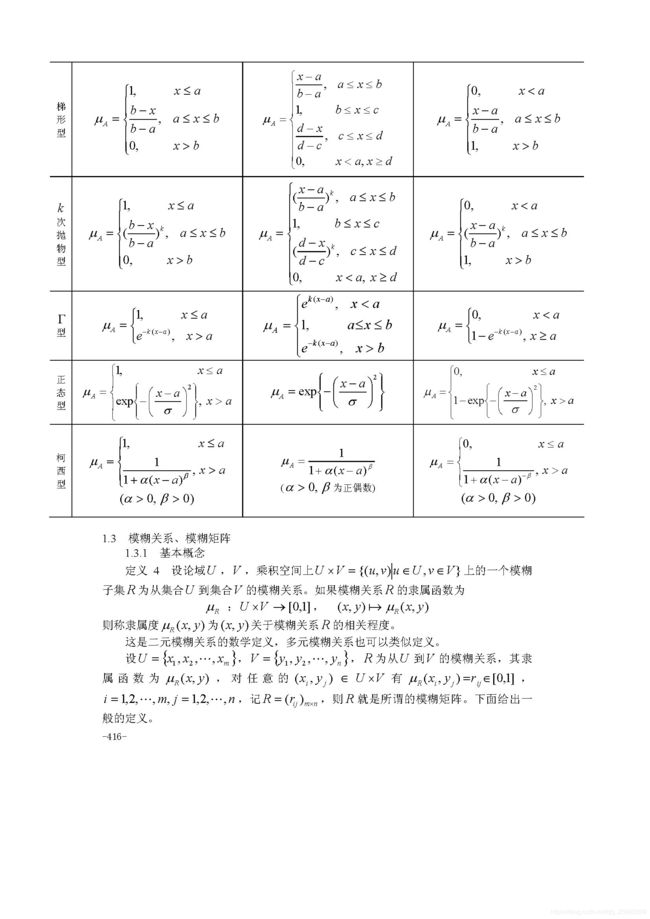
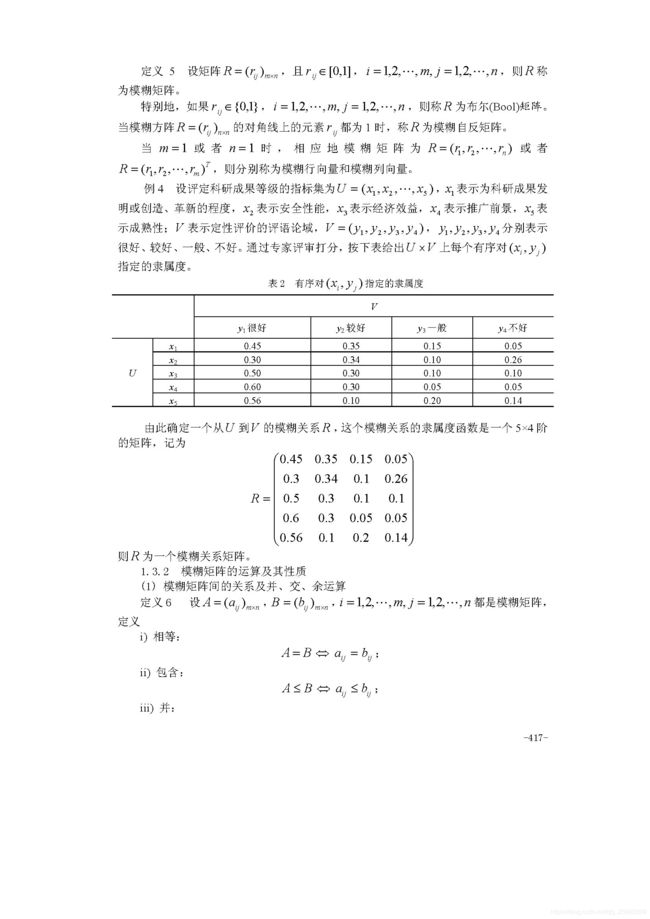
模糊综合评判(必须掌握)
评价一个对象优良中差等层次评价,评价一个学校等,不能排序






















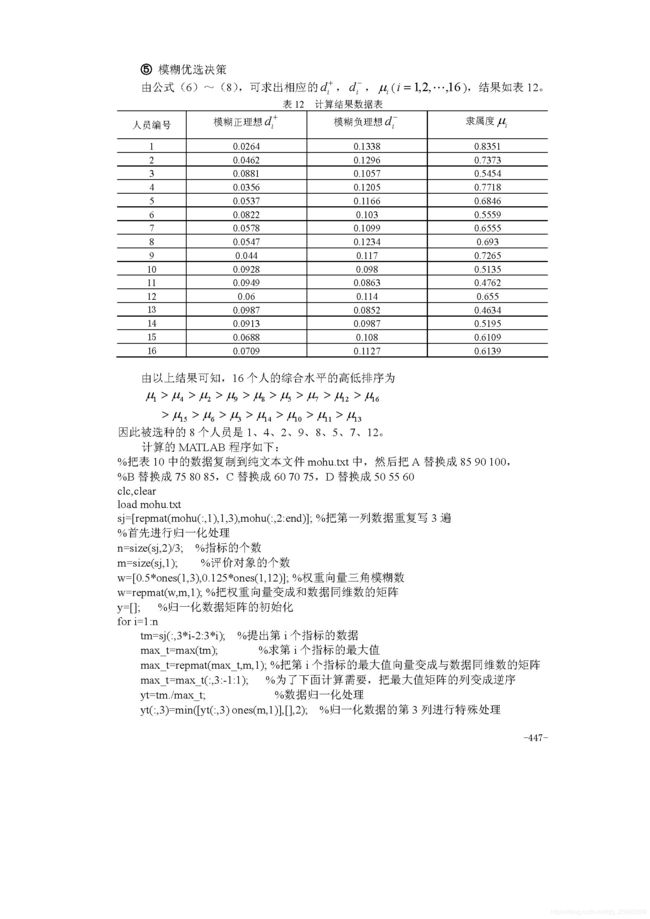

主成分分析(必须掌握)
评价多个对象的水平并排序,指标见关联性很强
- 引例:居民生活质量
为了全面分析我国各省市自治区的城市居民生活质量,选取如下六个指标:人均工资、人均住房面积、人均道路面积、人均公园绿地面积、商品销售总额、旅游外汇收入
假定给定了各省市自治区的上述六个指标数据,试着对各省市自治区的居民生活质量进行综合评价。事实上,上述六个指标存在一定的相关性,应该将它们综合成几个不相关的指标后再进行分析。
层次分析法(AHP,必须掌握)
做决策,取哪旅游,通过指标,综合考虑做决策
数据包络(EDA)分析法
秩和比综合评价法(必须掌握)
评价各个对象并排序,指标间关联性不强
优劣解距离法(TOPSIS法)
投影寻踪综合评价法
柔和多种算法,比如遗传算法、最优化理论等
方差分析、协方差分析等(必须掌握)
方差分析:看几类数据之间有无差异,差异性影响,例如:元素对麦子的产量有无影响,差异量的多少;
协方差分析:有几个因素,我们只考虑一个因素对问题的影响,忽略其他因素,但注意初始数据的量纲及初始情况
(三)、分类与判别
1、距离聚类(系统聚类)(必须掌握)
2、关联性聚类(需掌握)
3、层次性据类
4、密度性聚类
5、其他聚类
6、贝叶斯判别(统计判别方法,必须掌握)
7、费舍尔判别(训练的样本点比较多,必须掌握)
8、模糊识别(分好类的数据点比较少)
(四)、关联与因果
1、灰色关联分析方法(样本点的个数比较少)
2、Sperman或Kendall等级相关分析
3、Person相关(样本点的个数比较多)
4、Copula相关(比较难,金融数学、概率数学)
5、典型相关分析
因变量组Y1234,自变量组X1234,各自变量组相关性比较强,问哪一个因变量与哪一个自变量关系比较紧密?
6、标准化回归分析
若干自变量,一个因变量,问哪一个自变量与因变量关系比较紧密
7、生产分析(事件史分析)
数据里面有缺失的数据,哪些因素对因变量有影响
8、格兰杰因果检验
计量经济学,去年的x对今年的y有没有影响