numpy中一些用法汇总
本篇文章用来总结在使用numpy库使用到的函数,方便自己回过头来查阅,在开始默认导入如下设置
import numpy as np1. 奇异值分解会用到
numpy.linalg.svd(a, full_matrices=True, compute_uv=True)
a : 维度大于等于2的矩阵
full_matrices: 默认为True ,用来表示u, vh是否维度分别为(M,M)和(N,N),不然的话维度就为(M,K)和(K,N)
compute_uv: 默认为True,是否在s外组合u和vh
返回值为
u : 是个(M,M)或者(M,K)的矩阵
s :返回的是除了主对角线以外全为0,主对角线上的值被称为奇异值,这里返回的时候只返回奇异值数组,而且奇异值是从大到小排序的,这里在做奇异值能量占比的时候会使用到。
vh : 是个(N,N)或者(K,N)的矩阵
拓展:这里解释下SVD ,假设矩阵A 是一个m*n的矩阵,那么定义矩阵A的SVD为
![]() ,
, ![]() 所以上述的函数就是将一个矩阵进行分解,但是在实际的操作中是要将矩阵进行降维,降维主要是对中间的
所以上述的函数就是将一个矩阵进行分解,但是在实际的操作中是要将矩阵进行降维,降维主要是对中间的 进行调整,这是个对角矩阵,因为除了主对角线以外其余的元素全为0,而在做奇异值分解后实际返回的奇异值大小是从大往小排序的,我们在实际操作中只取前面的k个值,前10%的奇异值之和就占了全部奇异值之和的80%以上的比例,从而达到降维的效果。
进行调整,这是个对角矩阵,因为除了主对角线以外其余的元素全为0,而在做奇异值分解后实际返回的奇异值大小是从大往小排序的,我们在实际操作中只取前面的k个值,前10%的奇异值之和就占了全部奇异值之和的80%以上的比例,从而达到降维的效果。
进行降维后就可以这样来进行表示 ![]() 通过后面的来进行描述矩阵A会发现高分值十分接近。这说明我们可以用
通过后面的来进行描述矩阵A会发现高分值十分接近。这说明我们可以用![]() 来表征原始的矩阵A 。
来表征原始的矩阵A 。
举例如下:

比如上述的sigma我们可以看到奇异值是从大往小排序的,前5就能包含89%的特征了,那么我们取5*5来对矩阵进行降维后看会得到啥
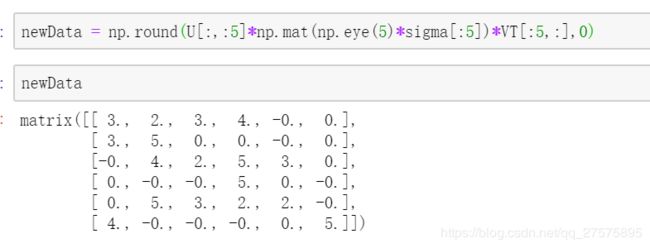
这里我们对比newData和最开始做奇异值分解的矩阵myhat可以发现基本一致。这也是降维思想的由来。
2. 保留小数位
numpy.round(a, decimals=0, out=None) 将array中的值按照指定精度进行保留
a: array 或者 矩阵
decimals : 精度
比如保留2位小数:

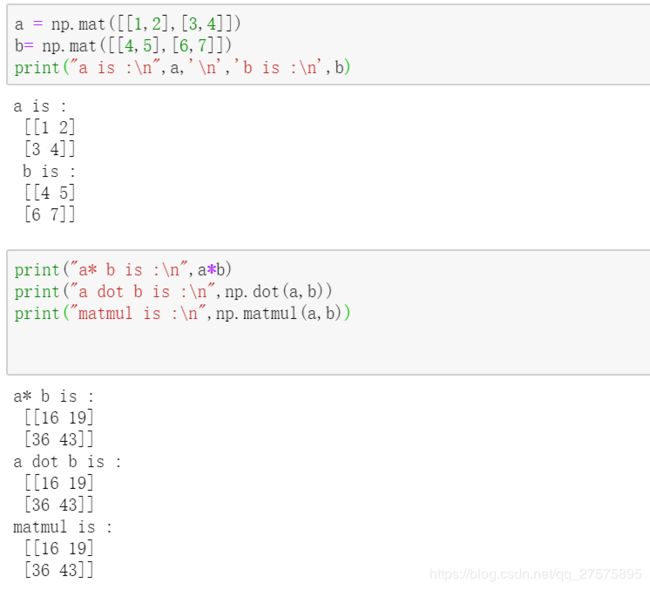
3. 矩阵的叉乘 ![]()
4. 矩阵的模 numpy.linalg.norm(x, ord=None, axis=None, keepdims=False)
x: array 或者矩阵
ord : 默认为None,范式 的顺序,比如向量的1-范式:向量元素绝对值之和,向量的2-范式 :欧几里得范数,常用计算向量长度

举例如下:

比如这里算矩阵的1-范式,因为矩阵的1-范式表示的是列模,也就是对矩阵的每一列上的元素绝对值求和,再从中取最大的。(列绝对值和最大)
矩阵的2-范数 : ![]() 其中
其中 ![]() 为
为 ![]() 的特征值,所以描述的就是矩阵
的特征值,所以描述的就是矩阵![]() 的最大特征值开平方根。
的最大特征值开平方根。

矩阵的无穷-范数 : ![]() ; 取得是矩阵的每一行上的元素绝对值先求和,再从中取最大的(行绝对值和最大)
; 取得是矩阵的每一行上的元素绝对值先求和,再从中取最大的(行绝对值和最大)

5. numpy.sum() ,如果使用了np.sum ,那么表示将一个数组中的维数和列数上的数都加在一起

6. numpy.reshape(a,newshape,order='C') 矩阵重组,不改变矩阵内的数据,只改变维度
a: 目标矩阵或者array
newshape: 新维度,整型或者为整型的元组

有时固定行让程序自动计算列数,不进行指定用如下方式实现
import numpy as np
x = np.array([0,1,2,3,3,4,5])
print(x.reshape(1, -1))
print(x.reshape(1, 7))得到结果如下所示:

上述的-1就是起到固定1行,列数不进行指定,改种方式与行列分别进行指定所达到的效果是一样的,但是有时候在进行一些计算的时候,传入进来的数组大小并不固定,这个时候就需要采用-1来进行灵活处理。
同样也可以固定列数对行数不进行指定,
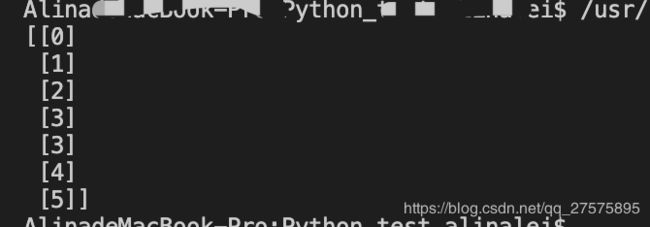
print(x.reshape(-1, 1))得到结果如下:
7. 矩阵的合并
numpy.vstack((a,b)) 、numpy.hstack((a,b))
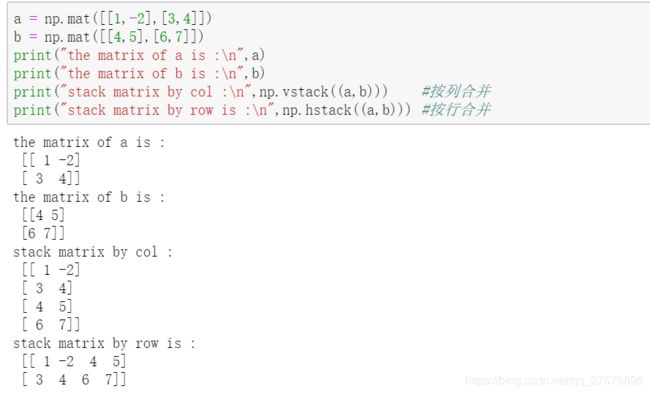
8. 矩阵的列和和行和

9. 生成对角矩阵
numpy.eye(n,n)

10.生成一个对角线为按照a列表来的矩阵
numpy.diag(a)

11. 矩阵的逆矩阵和转置

12 .矩阵的特征值 、特征向量

13. 返回非0元素的索引值
numpy.nonzero(a)


当然里面也可以加条件,不仅仅局限于0 ,

14. 数组拼接 numpy.concatenate(array, axis=0)
array 待拼接数组列表
axis 为0 代表将多个待拼接数组进行行追加对行扩充,为1代表将多个待拼接数据进行列追加对列扩充。
a = np.array([2, 3, 4, 5])
b = np.concatenate((np.array([-float('inf')]), a, np.array([float('inf')])))
print('b is:', b)
得到输出结果为:
![]()
15. numpy.where(condition, x, y)
满足condition条件输出x,否则输出y