python中文分词,生成标签云,生成指定形状图片标签云
使用结巴分词
https://github.com/fxsjy/jieba
可以直接pip 安装
pip install jieba
主要看到这么一篇文章
https://zhuanlan.zhihu.com/p/20432734?columnSlug=666666
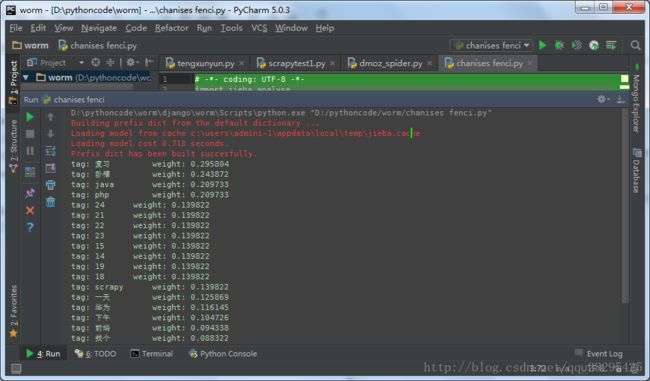
参考,测试我写的一个学习计划分析其关键词并给出权重
# -*- coding: UTF-8 -*-
import jieba.analyse
with open('ci.txt','r') as f:
seg_list =jieba.analyse.extract_tags(f.read(), topK=20, withWeight=True, allowPOS=())
for tag in seg_list:
print("tag: %s\t\t weight: %f" % (tag[0],tag[1]))
基于 TF-IDF 算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件还可以自定义字典,有一些提取不好的可以改下。
还有等等很多功能,需要的时候在学习。先了解下。
https://github.com/fxsjy/jieba
然后将其生成标签云
# -*- coding: utf-8 -*-
import codecs
import random
from pytagcloud import create_tag_image, create_html_data, make_tags, \
LAYOUT_HORIZONTAL, LAYOUTS
from pytagcloud.colors import COLOR_SCHEMES
from pytagcloud.lang.counter import get_tag_counts
wd = {}
fp=codecs.open("rsa.txt", "r",'utf-8');
alllines=fp.readlines();
fp.close();
for eachline in alllines:
line = eachline.split(' ')
#print eachline,
wd[line[0]] = int(line[1])
from operator import itemgetter
swd = sorted(wd.iteritems(), key=itemgetter(1), reverse=True)
tags = make_tags(swd,minsize = 50, maxsize = 240,colors=random.choice(COLOR_SCHEMES.values()))
create_tag_image(tags, 'yun.png', background=(0, 0, 0, 255),
size=(2400, 1000),layout=LAYOUT_HORIZONTAL,
fontname="SimHei")参考后
# -*- coding: utf-8 -*-
import codecs
import random
from pytagcloud import create_tag_image, create_html_data, make_tags, \
LAYOUT_HORIZONTAL, LAYOUTS
from pytagcloud.colors import COLOR_SCHEMES
from pytagcloud.lang.counter import get_tag_counts
import jieba.analyse
with open('ci.txt','r') as f:
seg_list =jieba.analyse.extract_tags(f.read(), topK=20, withWeight=True, allowPOS=())
wd={}
for tag in seg_list:
wd[tag[0]] = float(tag[1])
from operator import itemgetter
swd = sorted(wd.iteritems(), key=itemgetter(1), reverse=True)
tags = make_tags(swd,minsize = 50, maxsize = 240,colors=random.choice(COLOR_SCHEMES.values()))
create_tag_image(tags, 'yun.png', background=(0, 0, 0, 255),
size=(2400, 1000),layout=LAYOUT_HORIZONTAL,
fontname="SimHei")
输出
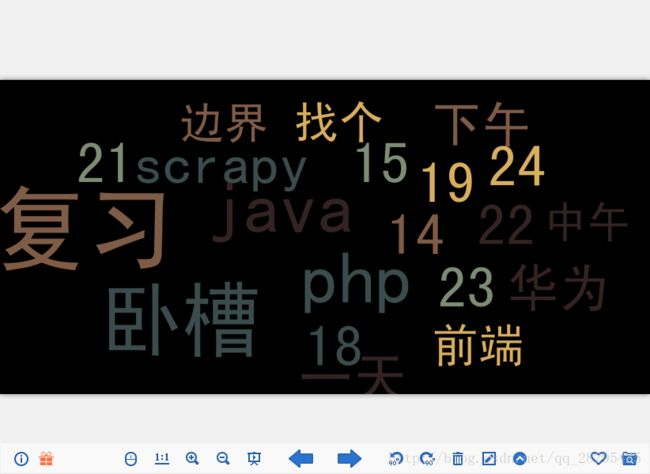
恩,像我参考的大佬说的那样,都是写入门基本的东西,我学习也是因为有趣。
还有一些标签云的解析参考
https://zhuanlan.zhihu.com/p/20436581?refer=666666
然后继续学习,指定图片覆盖生成图片里的形状的标签云。
就用的文章讲的图片学习。
参考
https://zhuanlan.zhihu.com/p/20436642
使用的 是 wordcloud
传入的是数组
作者:段小草
链接:https://zhuanlan.zhihu.com/p/20436642
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-*- coding: utf-8 -*-
"""
Minimal Example
===============
Generating a square wordcloud from the US constitution using default arguments.
"""
from os import path
from wordcloud import WordCloud
d = path.dirname(__file__)
# Read the whole text.
此处原为处理英文文本,我们修改为传入中文数组
#text = open(path.join(d, 'constitution.txt')).read()
frequencies = [(u'知乎',5),(u'小段同学',4),(u'曲小花',3),(u'中文分词',2),(u'样例',1)]
# Generate a word cloud image 此处原为 text 方法,我们改用 frequencies
#wordcloud = WordCloud().generate(text)
wordcloud = WordCloud().fit_words(frequencies)
# Display the generated image:
# the matplotlib way:
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
plt.axis("off")
# take relative word frequencies into account, lower max_font_size
#wordcloud = WordCloud(max_font_size=40, relative_scaling=.5).generate(text)
wordcloud = WordCloud(max_font_size=40, relative_scaling=.5).fit_words(frequencies)
plt.figure()
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# The pil way (if you don't have matplotlib)
#image = wordcloud.to_image()
#image.show()import numpy as np
from PIL import Image
from os import path
import matplotlib.pyplot as plt
import random
from wordcloud import WordCloud, STOPWORDS
def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
return "hsl(0, 0%%, %d%%)" % random.randint(60, 100)
d = path.dirname(__file__)
# read the mask image
# taken from
# http://www.stencilry.org/stencils/movies/star%20wars/storm-trooper.gif
mask = np.array(Image.open(path.join(d, "yun4.jpg")))
# movie script of "a new hope"
# http://www.imsdb.com/scripts/Star-Wars-A-New-Hope.html
# May the lawyers deem this fair use.
text = open("re.txt").read()
# preprocessing the text a little bit
text = text.replace("HAN", "Han")
text = text.replace("LUKE'S", "Luke")
# adding movie script specific stopwords
stopwords = STOPWORDS.copy()
stopwords.add("int")
stopwords.add("ext")
wc = WordCloud(max_words=1000, mask=mask, stopwords=stopwords, margin=10,
random_state=1).generate(text)
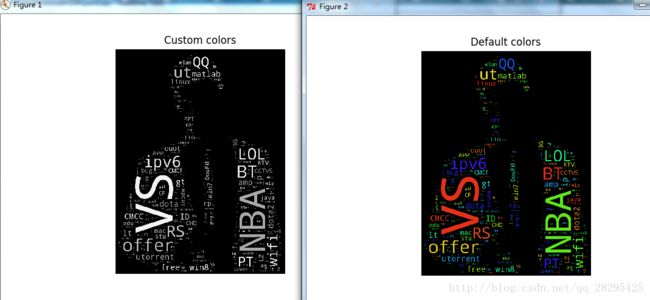
# store default colored image
default_colors = wc.to_array()
plt.title("Custom colors")
plt.imshow(wc.recolor(color_func=grey_color_func, random_state=3))
wc.to_file("a_new_hope.png")
plt.axis("off")
plt.figure()
plt.title("Default colors")
plt.imshow(default_colors)
plt.axis("off")
plt.show()生成图片
就是跟着文章学习然后做的。我想学习也是一点一点来的把。不过缺少了很多创新。等下次有机会用到结合实际需求碰撞出更好的东西把。
主要还是中文分词。记录下。方便以后用到。