TensorFlow 深度学习框架 (1)-- 神经网络与前向传播
基本概念:计算图,张量,会话
计算图是相互运算不影响的两个计算模型,是定义计算的运行,且互不影响
#在TensorFlow程序中,系统会自动维护一个默认的计算图,也支持通过tf.Graph 生成新的计算图
#不同计算图上的张量和运算都不会共享
import tensorflow as tf
print(a.graph is tf.get_default_graph()) #获取默认的计算图
g1 = tf.Graph()
with g1.as_default():
#在计算图 g1 中定义变量"v",并设置初始值为 0
v = tf.get_variable("v",shape = [1],initializer = tf.zeros_initializer())
g2 = tf.Grahp()
with g2.as_default():
#在计算图 g2 中定义变量"v",并设置初始值为 1
v = tf.ger_variable("v",shape = [1],initializer = tf.ones_initializer())
#在计算图 g1 中读取变量 "v" 的值
with tf.Session(graph = g1) as sess:
tf.initialize_all_variables().run() #初始化变量
with tf.variable_scope("layer1",reuse = True): #变量空间后续会介绍
print(sess.run(tf.get_variable("v"))) #输出为 0
#在计算图 g2 中读取变量 "v" 的值
with tf.Session(graph = g2) as sess:
tf.initialize_all_variables().run()
with tf.variable_scope("layer1",reuse = True):
print(sess.run(tf.get_variable("v"))) #输出为 1
print(v.eval()) #可以通过 节点.eval(session=xxx) 获取计算值
张量 Tensor 从名字上就能看出是一个基本的概念,在TensorFlow中所有的数据都通过张量的形式来表示。从功能的角度看,张量可以被简单理解为多维数据。其中0阶张量就是标量,表示一个数,第 n 阶张量就是 n 维的数组。但是张量在TensorFlow中并不是直接采用数组的形式实现,它只是对TensorFlow中运算结果的引用,在张量中并没有真正保存数字。
import tensorflow as tf
#tf.constant 是一个计算,这个计算的结果为一个张量,保存在变量 a 中
a = tf.constant([1.0,2.0],name = "a")
b = tf.constant([2.0,3.0],name = "b")
result = tf.add(a,b,name = "add")
print result
"""
输出:
Tensor("add:0",shape = (2,),dtypt=float32)
"""从上面的代码的运行结果可以看出,一个张量中主要保存了三个属性:name,shape,type
shape=(2,) 表示张量 result 是一个一维数组,这个数组的长度为 2
会话是TensorFlow用来运行计算的模型,会话拥有并管理TensorFlow程序运行时的所有资源。当所有计算完成后需要关闭会话来帮助系统回收资源。
#创建一个会话
sess = tf.Session()
#运行计算
sess.run(...)
#关闭会话来释放资源
sess.close()
#也可以用python中的上下文管理器来管理会话的开启和关闭
with tf.Session() as sess:
sess.run(...)
#不需要调用 sess.close() 来关闭了TensorFlow实现神经网络
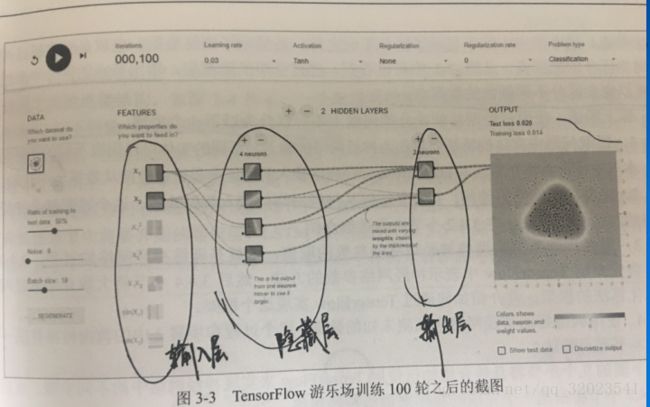
如图是一个包含三层的简单神经网络,输入层 x1 和 x2 ,隐藏层有 4 个节点,输出层有两个节点,如果把(x1,x2)当做某一个笛卡尔坐标系的取值,而点的颜色代表x1,x2这个节点的输出值。使用神经网络解决分类问题就可以分为以下4个步骤
1)提取问题中实体的特征向量作为神经网络的输入
2)定义神经网络的结构,并定义如何从神经网络的输入得到输出
3)通过训练数据来调整神经网络中参数的取值,这就是训练神经网络的过程
4)使用训练好的神经网络来预测未知的数据
这么说吧,假设有一些产品,知道一些合格品的长度和质量,也知道一些不合格品的长度和质量,上图的x1 和 x2就可以分别代表长度和质量参数,结果可以用数字 y 来代表合格与不合格。如果用上图的网络来实现,那么我们已经走到了第二步,即神经网络的结构已经定义好了,现在开始的是训练过程,而训练一个神经网络,需要解析它的前向传播算法。
前向传播算法简介
这里介绍最简单的全连接网络结构的前向传播算法,为了展示全连接网络结构,我们先了解神经元的传播。
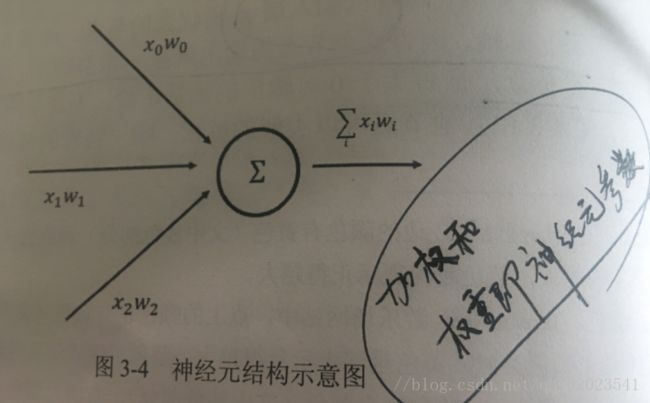
从图可以看出,一个神经元有多个输入和一个输出。一个最简单的神经元结构的输出就是所有输入的加权和,而不同输入的权重就是神经元的参数。这个参数的调节就是神经网络的训练过程。
现在我们回到前面定义的神经网络,这个网络的数据传播过程如下,每条线代表神经元的一个连接,每条线上的权重用W表示,为了简化,我们将隐藏层减为 3 个节点。
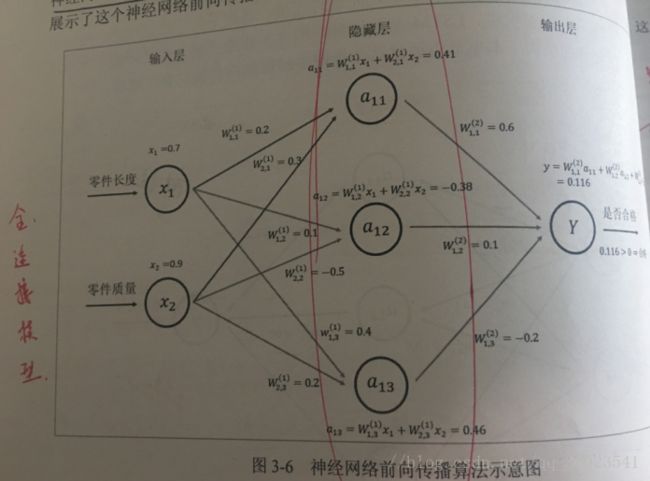
如图所示,给出了x1,x2从输入层一层一层前向传播的算法过程。
![]()
![]()
将输入 x1,x2组织成一个 1*2 的矩阵 x = [x1,x2],W组成一个2*3的矩阵
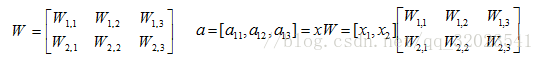
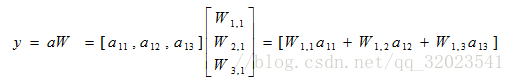
TensorFlow变量函数如下

用代码表示上述前向传播公式如下
import tensorflow as tf
#声明 w1,w2 两个变量,这里还通过 seed 参数设定了随机种子
#这样可以确保每次运行得到的结果是一样的
w1 = tf.Variable(tf.random_normal([2,3],stddev = 1,seed =1))
w2 = tf.Variable(tf.random_normal([3,1],stddev = 1,seed =1))
#暂时将输入的特征向量定义为一个常量,注意这里 x 是一个 1*2 的矩阵
x = tf.constant([[0.7,0.9]])
#前向传播算法
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
sess = tf.Session()
init_op = tf.initialize_all_variables()
sess.run(init_op)
print(sess.run(y))
sess.close()