葵花宝典--spark入门+WordCount入门
一、概述
定义:spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎;采用scala编写。支持迭代式计算和图计算,计算比MR快的原因,是因为他的中间结果不落盘,只有发生shuffer的时候才会进行落盘
内置模块

- sparkCore:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
- sparkSQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
- sparkStreaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
- sparkMLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
- sparkGraghX:主要用于图形并行计算和图挖掘系统的组件。
- 集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
特点:
- 快:想比较于mapRdeuce,spark基于内存运算,比MR要快100倍,基于硬盘也要快10倍以上。Spark实现了高效的DAG运算,通过内存来高效处理,计算的中间结果也是基于内存的
- 易用:支持java、scala和python的API,支持超过80种算法,支持交互式的linux命令行
- 通用性:支持了统一的解决方案,可以用于交互式查询、实时流处理、机器学习和图计算,并且可以在同一个应用中无缝连接
- 兼容性:可以和其他开源产品无缝融合,包括hadoop、hdfs、yarn等,并且可以处理存储在hdfs中的数据
运行模式:简单分为单机模式和集群模式
- local模式:本地部署单个spark服务
- standalone模式:spark自带的集群和任务调度
- yarn模式:Spark使用Hadoop的YARN组件进行资源与任务调度
- mesos模式:Spark使用Mesos平台进行资源与任务的调度
二、安装和使用
yarn模式安装:
1、解压spark安装包,确保hadoop环境能正常使用
2、配置yarn-site.xml
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
3、修改/opt/module/spark/conf/spark-env.sh,添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
##确保directory目录已在hdfs中创建完成
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"4、修改spark-default.conf文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=180805、运行模式:客户端模式(driver在客户端)和集群模式(driver不在客户端,位置由集群决定)
服务启动:
- 启动关闭服务:sbin/start-all.sh sbin/stop-all.sh
- 启动历史服务器:sbin/start-history-server.sh sbin/stop-history-server.sh
使用方式:
- spark-submit:bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn ./examples/jars/spark-examples_2.11-2.1.1.jar 10
- spark-shell:bin/spark-shell,开启交互式命令行
三、集群角色
master和slave:

driver和executor:
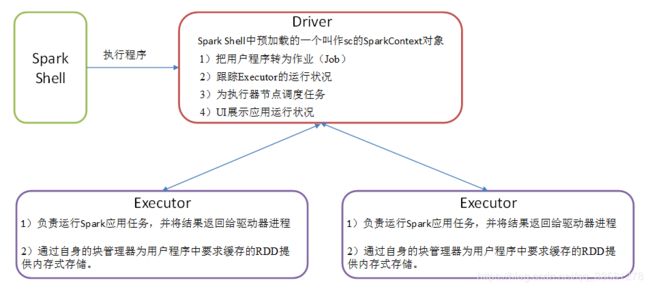
通用运行流程:Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序
集群模式运行流程:

集中模式对比:
| 模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
| Local |
1 |
无 |
Spark |
| Standalone |
3 |
Master及Worker |
Spark |
| Yarn |
1 |
Yarn及HDFS |
Hadoop |
常用端口号:
1)Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)
2)Spark Master Web端口号:8080(类比于Hadoop的NameNode Web端口号:9870(50070))
3)Spark Master内部通信服务端口号:7077 (类比于Hadoop的8020(9000)端口)
4)Spark查看当前Spark-shell运行任务情况端口号:4040
5)Hadoop YARN任务运行情况查看端口号:8088
四、WordCount案例
val conf = new SparkConf().setMaster("local[*]").setAppName("WoedCount")
val sc = new SparkContext(conf)
val value: RDD[String] = sc.textFile("")
sc.textFile(args(0))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.saveAsTextFile(args(1))
sc.stop() SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("WoedCount");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD javaRDD = sc.textFile("D:\\ideaWorkspace\\scala0105\\spark-0105\\input");
JavaRDD words = javaRDD.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairRDD pairs = words.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
JavaPairRDD reduceBykey = pairs.reduceByKey(new Function2() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
reduceBykey.foreach(new VoidFunction>() {
@Override
public void call(Tuple2 stringIntegerTuple2) throws Exception {
System.out.println(stringIntegerTuple2._1 + "\t" + stringIntegerTuple2._2);
}
});
sc.close(); pom文件:
org.apache.spark
spark-core_2.11
2.1.1