图嵌入(Graph embedding)
目录
- Graph embedding的意义
- 图嵌入可以解决的问题
- 为什么我们要使用图形嵌入?
- 什么是图嵌入?
- 图嵌入的挑战
- Word2vec
- 图嵌入方法
- 总结
- 参考资料
- 后记
Graph embedding的意义
Graph广泛存在于真实世界的多种场景中,即节点和边的集合。比如社交网络中人与人之间的联系,生物中蛋白质相互作用以及通信网络中的IP地址之间的通信等等。除此之外,我们最常见的一张图片、一个句子也可以抽象地看做是一个图模型的结构,图结构可以说是无处不在。通过对它们的分析,我们可以深入了解社会结构、语言和不同的交流模式,因此图一直是学界研究的热点。 图分析任务可以大致抽象为以下四类: ( a )节点分类,( b )链接预测,( c )聚类,以及( d )可视化。(个人认为还包括因果)
图嵌入可以解决的问题
对于Graph的研究可以解决下面的一些问题:比如社交网络中新的关系的预测,在QQ上看到的推荐的可能认识的人;生物分子中蛋白质功能、相互作用的预测;通信网络中,异常事件的预测和监控以及网络流量的预测。如果要解决以上的问题,我们首先需要做的是对图进行表示,graph embedding 是其中非常有效的技术。
为什么我们要使用图形嵌入?
需要使用图形嵌入有以下几个原因:
-
机器学习图形是有限的。图由边和节点组成。这些网络关系只能使用数学、统计和机器学习的特定子集,而向量空间有更丰富的方法工具集。
-
嵌入是压缩的表示。邻接矩阵描述图中节点之间的连接。它是一个|V| x
|V|矩阵,其中|V|是图中节点的个数。矩阵中的每一列和每一行表示一个节点。矩阵中的非零值表示两个节点相连。使用邻接矩阵作为大型图的特征空间几乎是不可能的。假设一个图有1M个节点和一个1M x 1M的邻接矩阵。嵌入比邻接矩阵更实用,因为它们将节点属性打包到一个维度更小的向量中。 -
向量运算比图形上的可比运算更简单、更快。
什么是图嵌入?
图嵌入(Graph Embedding,也叫Network Embedding)是一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。
- 节点的分布式表示
- 节点之间的相似性表示链接强度
- 编码网络信息并生成节点表示
图嵌入是将属性图转换为向量或向量集。嵌入应该捕获图的拓扑结构、顶点到顶点的关系以及关于图、子图和顶点的其他相关信息。更多的属性嵌入编码可以在以后的任务中获得更好的结果。我们可以将嵌入式大致分为两类:
- 顶点嵌入:每个顶点(节点)用其自身的向量表示进行编码。这种嵌入一般用于在顶点层次上执行可视化或预测。比如,在2D平面上显示顶点,或者基于顶点相似性预测新的连接。
- 图嵌入:用单个向量表示整个图。这种嵌入用于在图的层次上做出预测,可者想要比较或可视化整个图。例如,比较化学结构。
图嵌入的挑战
如前所述,图嵌入的目标是发现高维图的低维向量表示,而获取图中每个节点的向量表示是十分困难的,并且具有几个挑战,这些挑战一直在推动本领域的研究:
- 属性选择:节点的“良好”向量表示应保留图的结构和单个节点之间的连接。第一个挑战是选择嵌入应该保留的图形属性。考虑到图中所定义的距离度量和属性过多,这种选择可能很困难,性能可能取决于实际的应用场景。它们需要表示图拓扑、节点连接和节点邻居。预测或可视化的性能取决于嵌入的质量。
- 可扩展性:大多数真实网络都很大,包含大量节点和边。嵌入方法应具有可扩展性,能够处理大型图。定义一个可扩展的模型具有挑战性,尤其是当该模型旨在保持网络的全局属性时。好的嵌入方法需要在大型图上高效。
- 嵌入的维数:实际嵌入时很难找到表示的最佳维数。例如,较高的维数可能会提高重建精度,但具有较高的时间和空间复杂性。较低的维度虽然时间、空间复杂度低,但无疑会损失很多图中原有的信息。用户需要根据需求做出权衡。在一些文章中,他们通常报告说嵌入大小在128到256之间对于大多数任务来说已经足够了。在Word2vec方法中,他们选择了嵌入长度300。
Word2vec
图嵌入是图表示学习的一种,简单的来说就是把图模型映射到低维向量空间,表示成的向量形式还应该尽量的保留图模型的结构信息和潜在的特性。自从word2vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的word2vec、doc2vec算法,基于物品序列的item2vec算法,基于图模型的图嵌入技术,无论是在引荐、广告还是反欺诈范畴,各互联网公司基于本身业务与嵌入结合的论文相继问世。当前比较知名的图嵌入方法有DeepWalk、Line和Node2vec,这些都是基于顶点对相似度的图表示学习,仅仅保留了一部分的图的特性。
在介绍其它图嵌入的方法之前,我将讨论Word2vec方法和Skip-Gram模型。它们是图嵌入方法的基础。
word2vec的思想可以简单的归结为一句话: 利用海量的文本序列,根据上下文单词预测目标单词共现的概率,让一个构造的网络向概率最大化优化,得到的参数矩阵就是单词的向量。
Word2vec是一种将单词转换为嵌入向量的嵌入方法。相似的词应该有相似的嵌入。Word2vec采用一层隐含神经网络的Skip-Gram网络。Skip-Gram被训练来预测句子中的相邻单词。这个任务被称为伪任务,因为它只是在训练阶段使用。网络在输入端接受单词,并对其进行优化,使其能够以高概率预测句子中的相邻单词。下图显示了输入单词(用绿色标记)和预测单词的示例。通过这个任务,作者实现了两个相似的词有相似的嵌入,因为两个意思相似的词很可能有相似的邻域词。

在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
如下图所示,Skip-Gram神经网络有输入层、隐含层和输出层。网络接受一个热门的编码字。one-hot编码是一个长度与单词字典相同的向量,除了1之外,其他都是0。第一个是字典中出现已编码单词的地方。隐含层没有激活功能,它的输出是一个单词的嵌入。输出层是预测邻域词的softmax分类器。

需要提到一点的是,由神经网络得出的这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V 的大小,所以Word2vec 本质上是一种降维操作——把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
NLP中的单词可以通过共现关系进行embedding,那么将graph类比成整个语料库,图中的节点类比成单词,我们是否也可以通过共现关系对graph中的node进行embedding?对于word2vec而言,语料库中的每个句子都可以描述单词之间的共现,对于graph,这种共现关系如何描述呢?接下来我们将对多种不同的graph embedding方式进行展开。
图嵌入方法
这部分将介绍四种图嵌入方法,其中三种属于顶点嵌入,而另外一种属于向量嵌入。 这些嵌入方式一定程度上用了Word2vec的嵌入原则。
顶点嵌入的方法可以分为三大类:因式分解方法、随机游走方法和深度方法。选择它们,是因为它们在实践中经常使用,并且通常提供最好的结果。DeepWalk使用随机游走来生成嵌入。随机游走从一个选定的节点开始,然后我们从一个当前节点移动到随机邻居节点,移动一定数量的步。该方法主要包括三个步骤:
-
抽样:用随机游动抽样一个图。从每个节点执行的随机游走很少。作者证明了从每个节点执行32到64个随机游走是足够的。一般良好的随机漫步的长度约为40步。
-
训练跳跃图:随机漫步与word2vec方法中的句子相似。跳跃图网络接受随机游走中的一个节点作为一个独热向量作为输入,并最大化预测邻居节点的概率。它通常被训练来预测大约20个邻居节点——左边10个节点,右边10个节点。
-
计算嵌入:嵌入是网络隐含层的输出。DeepWalk计算图中每个节点的嵌入。
步骤如下图所示

DeepWalk方法执行随机步,这意味着嵌入不能很好地保留节点的局部邻域。Node2vec方法解决了这个问题。
Node2vec 是DeepWalk的一个改进,只是随机漫步的差异很小。它有参数P和Q。参数Q定义了random walk发现图中未发现部分的概率,而参数P定义了random walk返回到前一个节点的概率。参数P控制节点周围微观视图的发现。参数Q控制较大邻域的发现。它可以推断出社区和复杂的依赖关系。
下图中显示了Node2vec中一个随机行走步长的概率。我们只是从红结点走了一步到绿结点。返回到红色节点的概率是1/P,而返回到与前一个(红色)节点没有连接的节点的概率是1/Q。到红结点相邻结点的概率是1。

图中显示了Node2vec中一个随机行走步长的概率。我们只是从红结点走了一步到绿结点。返回到红色节点的概率是1/P,而返回到与前一个(红色)节点没有连接的节点的概率是1/Q。到红结点相邻结点的概率是1。
嵌入的其他步骤与DeepWalk方法相同。
结构深度网络嵌入(SDNE) 与前两种方法没有任何共同之处,因为它不执行随机游走。SDNE在不同任务上的表现非常稳定。
它的设计使嵌入保持一阶和二阶接近。一阶近似是由边连接的节点之间的局部成对相似。它描述了本地网络结构的特征。如果网络中的两个节点与边缘相连,则它们是相似的。当一篇论文引用了另一篇论文,这意味着它们涉及了类似的主题。二阶邻近性表示节点邻近结构的相似性。它捕获了全局网络结构。如果两个节点共享许多邻居,它们往往是相似的。
SDNE提出的自动编码器神经网络有两个部分-见下图。自动编码器(左、右网络)接受节点邻接向量,并经过训练来重建节点邻接。这些自动编码器被命名为原始自动编码器,它们学习二级邻近性。邻接向量(邻接矩阵中的一行)在表示连接到所选节点的位置上具有正值。
还有一个网络的监督部分——左翼和右翼之间的联系。它计算从左到右的嵌入距离,并将其包含在网络的共同损耗中。网络经过这样的训练,左、右自动编码器得到所有由输入边连接的节点对。距离部分的损失有助于保持一阶接近性。
网络的总损耗是由左、右自编码器的损耗和中间部分的损耗之和来计算的。

图嵌入方法
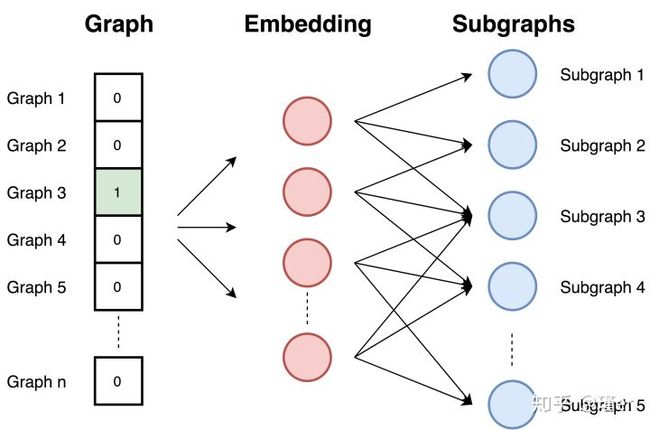
最后一种方法嵌入整个图。它计算一个描述图形的向量。在这一部分选择graph2vec来作为典型的例子,因为它是实现图嵌入的较优秀的方法。
Graph2vec基于doc2vec方法的思想,它使用了SkipGram网络。它获得输入文档的ID,并经过训练以最大化从文档中预测随机单词的概率。
Graph2vec方法包括三个步骤:
- 从图中采样并重新标记所有子图。子图是在所选节点周围出现的一组节点。子图中的节点距离不超过所选边数。
- 训练跳跃图模型。图类似于文档。由于文档是词的集合,所以图就是子图的集合。在此阶段,对跳跃图模型进行训练。它被训练来最大限度地预测存在于输入图中的子图的概率。输入图是作为一个热向量提供的。
- 通过在输入处提供一个图ID作为一个独热向量来计算嵌入。嵌入是隐藏层的结果。 由于任务是预测子图,所以具有相似子图和相似结构的图具有相似的嵌入。
其他嵌入方法
上面的分析是常用的一些方法。由于这个主题目前非常流行,还有其它的一些可用的方法:
- 顶点嵌入方法:LLE,拉普拉斯特征映射,图分解,GraRep, HOPE, DNGR, GCN, LINE
- 图形嵌入方法:Patchy-san, sub2vec (embed subgraphs), WL kernel和deep WL kernels
总结
这篇文章从以下几个方面对图嵌入作了简介:
- 图嵌入的意义
- Word2Vec方法。 Word2vec方法和Skip-Gram模型。它们是图嵌入方法的基础。
- 图嵌入,这部分将介绍四种图嵌入方法,其中三种属于顶点嵌入,而另外一种属于向量嵌入。这些嵌入方式一定程度上用了Word2vec的嵌入原理。
参考资料
【1】 [NLP] 秒懂词向量Word2vec的本质
【2】一些大牛的回答和帖子
【3】Graph Embedding:从DeepWalk到SDNE
后记
图(Graph)是一个常见的数据结构,现实世界中有很多很多任务可以抽象成图问题,比如社交网络,蛋白体结构,交通路网数据,以及很火的知识图谱等,甚至规则网络结构数据(如图像,视频等)也是图数据的一种特殊形式。针对graph的研究可以分成三类:
- 1.简单的graph算法:如生成树算法,最短路算法,复杂一点的二分图匹配,费用流问题等等;
- 2.概率图模型:将条件概率表达为图结构,并进一步挖掘,典型的有条件随机场等;
- 3.图神经网络:研究图结构数据挖掘的问题,典型的有graph embedding,graph CNN等。