hadoop学习笔记(五)MapReduce常见实例二:排序(一次排序、二次排序、倒排索引)
目录
一次排序
MapReduce的默认排序规则
Map、Reduce任务中Shuffle和排序的过程
流程分析
任务描述
代码
执行结果
二次排序
任务描述
过程分析
代码
执行结果
倒排索引
任务描述
设计思路
代码
执行过程
执行结果
一次排序
熟悉MapReduce的人都知道,排序是MapReduce的天然特性!在数据达到reducer之前,MapReduce框架已经对这些数据按键排序了。
MapReduce的默认排序规则
它是按照key值进行排序的,如果key为封装的int为IntWritable类型,那么MapReduce按照数字大小对key排序;
如果Key为封装String的Text类型,那么MapReduce将按照数据字典顺序对字符排序。
Map、Reduce任务中Shuffle和排序的过程
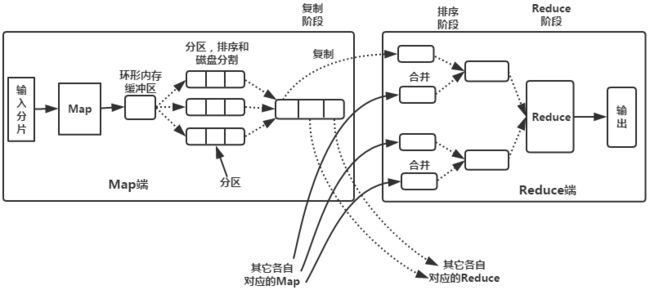
流程分析
1. Map端:
(1)每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
(2)在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
(3)当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:①尽量减少每次写入磁盘的数据量。②尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
(4)将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?
2.Reduce端:
(1)Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
(2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
(3)合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
任务描述
现有用户对商品访问情况的数据文件goods_visit1,包含商品id ,点击次数两个字段,内容以“\t”分割,数据内容如下:
商品id 点击次数
1010037 100
1010102 100
1010152 97
1010178 96
1010280 104
1010320 103
1010510 104
1010603 96
1010637 97要求编写mapreduce程序来对商品点击次数实现由低到高的排序。
代码
package MapReduce.sort;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
// goods_visit1中包含(商品id ,点击次数)两个字段,内容以“\t”分割
// 对商品点击次数由低到高进行排序
public class OneSort {
public static class Map extends Mapper{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String arr[]=line.split("\t");
num.set(Integer.parseInt(arr[1]));//把要排序的点击次数字段转化为IntWritable类型并设置为key
goods.set(arr[0]);//商品id字段设置为value
context.write(num,goods);//输出
}
}
// 在数据达到reducer之前,MapReduce框架已经按照key值对这些数据按键排序了,就是shuffle()
// 如果key为封装的int为IntWritable类型,那么MapReduce按照数字大小对key排序
// 如果Key为封装String的Text类型,那么MapReduce将按照数据字典顺序对字符排序
// 所以一般在map中把要排序的字段使用IntWritable类型,作为key,不排序的字段作为value
public static class Reduce extends Reducer{
@Override
protected void reduce(IntWritable key, Iterable values, Context context) throws IOException, InterruptedException {
for(Text value : values){
context.write(key,value);
}
}
}
public static void main(String[] args) throws Exception {
Job job = Job.getInstance();
job.setJobName("OneSort");
job.setJarByClass(OneSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
Path in = new Path("hdfs://localhost:9000/mr/in/goods_visit1");
Path out = new Path("hdfs://localhost:9000/mr/out/onesort/goods_visit1");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行结果

二次排序
在mapreduce操作时,shuffle阶段会多次根据key值排序。但是在shuffle分组后,相同key值的values序列的顺序是不确定的。如果想要此时value值也是排序好的,这种需求就是二次排序。
任务描述
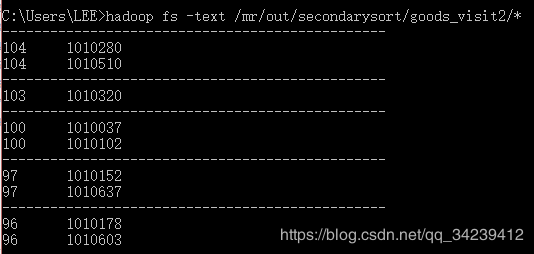
用户对商品的访问情况记录为goods_visit2表,包含(goods_id,click_num)两个字段。 要求编写MapReduce代码,功能为根据商品的点击次数(click_num)进行降序排序,再根据goods_id升序排序,并输出所有商品。
数据内容如下:
goods_id click_num
1010037 100
1010102 100
1010152 97
1010178 96
1010280 104
1010320 103
1010510 104
1010603 96
1010637 97
过程分析
在Map阶段:
1.使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。本实验中使用的是TextInputFormat,他提供的RecordReder会将文本的字节偏移量作为key,这一行的文本作为value。这就是自定义Map的输入是
2.然后调用自定义Map的map方法,将一个个
3.在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。可以看到,这本身就是一个二
次排序。如果没有通过job.setSortComparatorClass设置key比较函数类,则可以使用key实现的compareTo方法进行排序。
在Reduce阶段:
1.reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass设置的key比较函数类对所有数据对排序。
2.然后开始构造一个key对应的value迭代器。这时就要用到分组,使用job.setGroupingComparatorClass设置的分组函数类。只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,
而这个迭代器的key使用属于同一个组的所有key的第一个key。
3.最后就是进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器)。同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
代码
package MapReduce.sort;
import java.io.*;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
// 二次排序
// goods_visit2表,包含(goods_id,click_num)两个字段
// 根据商品的点击次数(click_num)进行降序排序,再根据goods_id升序排序,并输出所有商品
public class SecondarySort
{
public static class IntPair implements WritableComparable// 自定义组合key,让类中个每个成员变量都参与计算和比较
{
int first;//第一个成员变量
int second;//第二个成员变量
public void set(int left, int right) {
first = left;
second = right;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
@Override
public void readFields(DataInput in) throws IOException {//反序列化,从流中的二进制转换成IntPair
first = in.readInt();
second = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {//序列化,将IntPair转化成使用流传送的二进制
out.writeInt(first);
out.writeInt(second);
}
@Override
public int compareTo(IntPair o) {// 自定义key比较
if (first != o.first)
return first < o.first ? 1 : -1;
else if (second != o.second)
return second < o.second ? -1 : 1;
else
return 0;
}
// 由于后面进行了自定义组合key对象的相等比较操作,最好重写hashCode()和equal()方法
@Override
public int hashCode(){
return first * 157 + second;
}
@Override
public boolean equals(Object right){
if (right == null)
return false;
if (this == right)
return true;
if (right instanceof IntPair) {
IntPair r = (IntPair) right;
return r.first == first && r.second == second;
}
else
return false;
}
}
// 分区函数类代码
public static class FirstPartitioner extends Partitioner
{
@Override
public int getPartition(IntPair key, IntWritable value,int numPartitions) {
/**
* 数据输入来源:map输出
* @param key map输出键值,自定义组合key
* @param value map输出value值
* @param numPartitions 分区总数,即reduce task个数
**/
// 数字的分区写法:
// 根据自定义key中first(click_num)乘以127取绝对值,再对numPartions取余来进行分区,主要是为实现了第一次排序
return Math.abs(key.getFirst() * 127) % numPartitions;
}
}
// 分组函数类代码,即自定义比较器,自定义二次排序策略
public static class GroupingComparator extends WritableComparator // 这是一个比较器,需要继承WritableComparator
{
protected GroupingComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
// 在reduce阶段,构造一个key对应的value迭代器的时候,只要first相同就属于同一个组,放在一个value迭代器
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
int l = ip1.getFirst();//click_num
int r = ip2.getFirst();
return l == r ? 0 : (l < r ? -1 : 1);//比较click_num大小,相等返回0,小于返回-1,大于返回1
}
}
// 在Map阶段:
// 1. 使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。
// 本实验中使用的是TextInputFormat,他提供的RecordReder会将文本的字节偏移量作为key,这一行的文本作为value。
// 这就是自定义Map的输入是的原因。
// 2. 然后调用自定义Map的map方法,将一个个键值对输入给Map的map方法。
// 注意输出应该符合自定义Map中定义的输出。最终是生成一个List。
// 3. 在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。
// 每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。可以看到,这本身就是一个二次排序。
// 如果没有通过job.setSortComparatorClass设置key比较函数类,则可以使用key实现的compareTo方法进行排序。
// 将map端输出的中的key和value组合成一个新的key(称为newKey),value值不变,变成<(key,value),value>
// 在针对newKey排序的时候,如果key相同,就再对value进行排序。
public static class Map extends Mapper
{
private final IntPair intkey = new IntPair();
private final IntWritable intvalue = new IntWritable();//相当于int
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
int left = 0;
int right = 0;
if (tokenizer.hasMoreTokens())//如果还存在下一个记录
{
left = Integer.parseInt(tokenizer.nextToken());//goods_id
if (tokenizer.hasMoreTokens())
right = Integer.parseInt(tokenizer.nextToken());//click_num
intkey.set(right, left);
intvalue.set(left);
context.write(intkey, intvalue);//组合为新的键<(key,value),value>,即<(click_num,goods_id),goods_id>
}
}
}
// 在Reduce阶段:
// 1. reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass设置的key比较函数类对所有数据对排序
// 2. 然后开始构造一个key对应的value迭代器。这时就要用到分组,使用job.setGroupingComparatorClass设置的分组函数类
// 只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,而这个迭代器的key使用属于同一个组的所有key的第一个key
// 3. 最后就是进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器),同样注意输入与输出的类型必须与自定义的Reducer中声明的一致
public static class Reduce extends Reducer
{
private final Text left = new Text();
private static final Text SEPARATOR = new Text("------------------------------------------------");
public void reduce(IntPair key, Iterable values,Context context) throws IOException, InterruptedException {
context.write(SEPARATOR, null);
left.set(Integer.toString(key.getFirst()));//click_num
for (IntWritable val : values)//goods_id
context.write(left, val);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = new Job(conf, "SecondarySort");
job.setJarByClass(SecondarySort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置分区函数类,实现第一次排序
job.setPartitionerClass(FirstPartitioner.class);
// 指定分组排序使用的比较器,默认使用key对象(IntPair)自身的compareTo()方法,实现第二次排序
job.setGroupingComparatorClass(GroupingComparator.class);
//设置map输出类型
job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// job.setNumReduceTasks(1);//设置reduce Task的数量,默认是1
String[] otherArgs=new String[]{
"hdfs://localhost:9000/mr/in/goods_visit2",
"hdfs://localhost:9000/mr/out/secondarysort/goods_visit2"
};
FileInputFormat.setInputPaths(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行结果
倒排索引
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
实现"倒排索引"主要关注的信息为:单词、文档URL及词频。
任务描述
现有3张信息数据表,分别为商品库表goods3,商品访问情况表goods_visit3,订单明细表order_items3,goods表记录了商品的状态数据,goods_visit3记录了商品的点击情况,order_items3记录了用户购买的商品的信息数据,它们的表结构及内容如下:
goods3(goods_id,goods_status,cat_id,goods_score)
商品ID 商品状态 分类ID 评分
1024600 6 52006 0
1024593 1 52121 0
1024592 1 52121 0
1024590 1 52119 0
1024589 1 52119 0
1024588 1 52030 0
1024587 1 52021 0
1024586 1 52029 0
1024585 1 52014 0
1024584 1 52029 0goods_visit3(goods_id,click_num)
商品ID 商品点击次数
1024600 2
1024593 0
1024592 0
1024590 0
1024589 0
1024588 0
1024587 0
1024586 0
1024585 0
1024584 0order_items3(item_id,order_id,goods_id,goods_number,shop_price,goods_price,goods_amount)
明细ID 订单ID 商品ID 购买数据 商品销售价格 商品最终单价 商品金额
251688 52107 1024600 1 31.6 31.6 15.8
252165 52209 1024600 1 31.6 31.6 15.8
251870 52146 1024481 1 15.6 15.6 7.8
251935 52158 1024481 1 15.6 15.6 7.8
252415 52264 1024480 1 69.0 69.0 69.0
250983 51937 1024480 1 69.0 69.0 69.0
252609 52299 1024480 1 69.0 69.0 69.0
251689 52107 1024440 1 31.6 31.6 15.8
239369 49183 1024256 1 759.0 759.0 759.0
249222 51513 1024140 1 198.0 198.0 198.0要求查询goods_id相同的商品都在哪几张表中,并统计出现了多少次。
设计思路
(1)Map过程
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的

这里存在两个问题:
第一,
第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
这里将商品ID和URL组成key值(如"1024600:goods3"),将词频(商品ID出现次数)作为value,这样做的好处是可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
(2)Combine过程
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频,如下图所示。如果直接将下图所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词(商品ID)作为key值,URL和词频组成value值(如"goods3:1")。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。如下图所示:

(3)Reduce过程
经过上述两个过程后,Reduce过程只需将相同key值的所有value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。如下图所示:

代码
package MapReduce.sort;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
// 倒排索引
//goods3(goods_id,goods_status,cat_id,goods_score)
//goods_visit3(goods_id,click_num)
//order_items3(item_id,order_id,goods_id,goods_number,shop_price,goods_price,goods_amount)
//查询goods_id相同的商品都在哪几张表,并统计出现了多少次
public class InvertedIndex {
public static class doMapper extends Mapper{
public static Text myKey = new Text(); // 存储单词和URL组合
public static Text myValue = new Text(); // 存储词频
//private FileSplit filePath; // 存储Split对象
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String filePath=((FileSplit)context.getInputSplit()).getPath().toString();
System.out.println("filePath= "+filePath);
System.out.println("传给map的key为 "+key);//偏移量
System.out.println("传给map的value为 "+value);//文件每行内容
// Map过程必须分析输入的对,得到倒排索引中需要的三个信息:单词、文档URL和词频
String val[]=value.toString().split("\t");
if(filePath.contains("goods")){
int splitIndex =filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
}else if(filePath.contains("order")){
int splitIndex =filePath.indexOf("order");//获取字符串中含有order的起始索引位置
//order表中的goods_id位于第三列,即val[2]
//以“goods_id:文件名”格式组成key
myKey.set(val[2] + ":" + filePath.substring(splitIndex));//获取字符串中指定索引位置开始的子串
}
myValue.set("1");
context.write(myKey, myValue);
System.out.println("map的key为 "+myKey.toString());
System.out.println("map的value为 "+myValue.toString());
}
}
// 这里存在两个问题:
// 第一,对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值
// 第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计
public static class doCombiner extends Reducer{
public static Text myKey = new Text();
public static Text myValue = new Text();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//传给combine的key为map中set的myKey,如“1024140:order_items3”
System.out.println("传给combine的key为 "+key);
//key可能重复,一个key对应多个value,这些value组成了一个Iterable values的list,list中每个值都为1
int sum = 0 ;
for (Text value : values)
sum += Integer.parseInt(value.toString());//将key值相同的value值累加,得到一个单词在文档中的词频
//分隔map传来的key(goods_id:文件名)
int mysplit = key.toString().indexOf(":");
myKey.set(key.toString().substring(0, mysplit));//goods_id
myValue.set(key.toString().substring(mysplit + 1) + ":" + sum);//文件名:词频
context.write(myKey, myValue);
System.out.println("combiner key "+myKey.toString());
System.out.println("combiner value "+myValue.toString());
}
}
// 如果直接将输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:
// 所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值
// 这次将单词(goods_id)作为key值,URL和词频组成value值
// 这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理
public static class doReducer extends Reducer{
public static Text myKey = new Text();
public static Text myValue = new Text();
@Override
//经过上述两个过程后,Reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
System.out.println("传给reduce的key为 "+key);
System.out.println("传给reduce的values为 "+values);
String myList = new String();
for (Text value : values)
myList += value.toString() + ";";
myKey.set(key);
myValue.set(myList);
context.write(myKey, myValue);
System.out.println("reduce key "+myKey.toString());
System.out.println("reduce value "+myValue.toString());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("InversedIndex");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(doMapper.class);
job.setCombinerClass(doCombiner.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in1 = new Path("hdfs://localhost:9000/mr/in/goods3");
Path in2 = new Path("hdfs://localhost:9000/mr/in/goods_visit3");
Path in3 = new Path("hdfs://localhost:9000/mr/in/order_items3");
Path out = new Path("hdfs://localhost:9000/mr/out/invertedindex");
// 使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容,移交给Map
FileInputFormat.addInputPath(job, in1);
FileInputFormat.addInputPath(job, in2);
FileInputFormat.addInputPath(job, in3);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行过程
上述代码的执行过程为:
1. 一个path作为filePath传给map,path中的文件的行偏移量作为传给map的key,path中文件的每行内容作为传给map的value
2. 以'\t'split value,存储到val[]中
3. 截取path中的文件名
4. 根据path判断传给map的是具体哪个文件,根据文件名选择goods_id所在val[]列,设置key为goods_id:文件名,value为1,传给combine
5. 重复1-4步,直到该文件读取完毕
6. combine获取map传来的key和values list(key可能重复,一个key对应多个value,这些value组成了一个Iterable
7. 对每个key进行词频统计,遍历values累加其value值,赋给sum
8. split map传来的key,获取goods_id和文件名
9. 设置key为goods_id,value为“文件名:sum(词频)”
10. 重复6-9步,直至map传来的全部combine完毕
11. 重复1-10步,直至所有文件都combine完毕,将combian的key,value传给reduce
12. 根据combine传来的key,遍历其values,以分号间隔集成一个String,设置成reduce的value,key不变
13. 重复12步,直至combine传来的全部reduce完毕
14. 将结果写入out文件
执行结果
