一知半解 --词向量(Word2Vec初步解读及代码实现)
目录
- 词向量的来源
- word2vec简介
- 词向量实战训练
- 结果测试
- 结束语
- 参考文献
词向量的来源
NLP相关任务中最常见的第一步是创建一个词表库并把每个词顺序编号,这就是最初的one-hot模型,这种方法把每个词顺序编号,每个词就是一个很长的向量,向量的维度等于词表的大小,只有对应位置上的数字为1,其他都为0,例如一个词表[’ 我’,‘是’,‘谁’],那么这个词表的大小是3,每个词对应的向量为:
- 我:[1,0,0]
- 是:[0,1,0]
- 谁:[0,0,1]
而实际常用的模型是词袋模型,该模型仍以词语为基本处理单元,下面举例说明该方法的原理,首先给出两个简单的文本如下:
- 我是一个学生
- 我爱学习,小明也爱学习
基于上面文本出现的词,构建如下词典:
- {‘我’:1, ‘是’:2, ‘一个’:3, ‘学生’:4, ‘爱’:5, ‘学习’:6, ‘小明’:7, ‘也’:8}
上面词典包含8个词语,每个词有唯一的索引,那么每个文本我们就可以使用一个8维的向量表示,如下所示:
- [1,1,1,1,0,0,0,0]
- [1,0,0,0,2,2,1,1]
然而随着词典规模的增大,向量的维度也要增大,这就造成了维度灾难,矩阵也会变得超级稀疏,这样会大大耗费计算资源;同时该方法也丢掉了词序信息,造成语意鸿沟,而在很多NLP任务中,我们是需要去关注一个词的上下文信息,从而从大量的数据中挖掘有价值的信息来,词向量技术就是为了利用神经网络从大量的文本数据中提取有用信息而产生的。
word2vec简介
word2vec是Google在2013年发布的一个开源词向量建模工具,是一款将词表征为实数值的高效工具,采用的语言模型有CBOW和Skip-Gram两种,这两种模型原理可以用下图展示:
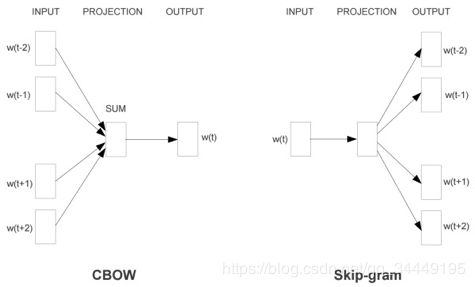
从直观上理解,Skip-Gram是给定input word来预测上下文;而CBOW是给定上下文,来预测input word。详细原理本文就不介绍了,感兴趣的可以去阅读word2vec的源码或者读这篇博客 点击阅读,因为Google的gensim模块已经将这两种语言模型包装好了,可以直接用,本文也是基于该模块对上次爬取的百度百科数据进行词向量训练。
词向量实战训练
语料:自己爬取的百度百科词条345万条,数据大小为18G
word2vec函数:
- Word2Vec(sentences=None,size=100,alpha=0.025,window=5, min_count=5, max_vocab_size=None, sample=0.001,seed=1, workers=3,min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=,iter=5,null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000)
- 参数详解
· sentences:可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或LineSentence构建;
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法;
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百;
· window:表示当前词与预测词在一个句子中的最大距离是多少;
· alpha: 是学习速率;
· seed:用于随机数发生器。与初始化词向量有关;
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5;
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制;
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5);
· workers参数控制训练的并行数;
· hs: 如果为1则会采用hierarchical softmax技巧。如果设置为0(defaut),则negative sampling会被使用;
· negative: 如果>0,则会采用negativesamping,用于设置多少个noise words;
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defaut)则采用均值。只有使用CBOW的时候才起作用;
· hashfxn: hash函数来初始化权重。默认使用python的hash函数;
· iter: 迭代次数,默认为5;
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数;
· sorted_vocab: 如果为1(defaut),则在分配word index 的时候会先对单词基于频率降序排序;
· batch_words:每一批的传递给线程的单词的数量,默认为10000。
因为数据量比较大,在数据预处理上花了一些时间,本来是可以直接从MongoDB中读取数据然后采用多进程处理,但是为了不依赖mongodb,采用了pandas的按块读取并用dataframe并行处理,速度还是可以的。(大批量的数据还是十分推荐保存为标准的csv格式,配合pandas处理大数据,效率杠杠的)
具体的语料预处理及模型训练代码还是详见GitHub
点击查看代码
结果测试
from gensim.models import Word2Vec
model = Word2Vec.load('baidubaike.word2vec')
#计算两个词的相似度
model.similarity('西红柿','番茄')
#out
0.8586861
model.similarity('西红柿','地球')
#out
0.21494764
#查看与目标词相近的词
model.most_similar('学习')
#out
[('自学', 0.7149122357368469),
('进修', 0.6984058618545532),
('学员', 0.6712468862533569),
('努力学习', 0.6626697778701782),
('深造', 0.6579384207725525),
('研习', 0.6552010178565979),
('授课', 0.6533999443054199),
('学习者', 0.647920548915863),
('进修班', 0.6479190587997437),
('学习外语', 0.6450531482696533)]
#使用TSNE对提取的特征进行降维,然后进行可视化
from sklearn.manifold import TSNE
import numpy as np
import matplotlib.pyplot as plt
import random
from matplotlib.font_manager import FontProperties
font = FontProperties(fname='/System/Library/Fonts/PingFang.ttc')
#因为词向量文件比较大,全部可视化就什么都看不见了,所以随机抽取一些词可视化
words = list(model.wv.vocab)
random.shuffle(words)
words = random.sample(words,100000)
vector = model[words]
tsne = TSNE(n_components=2,init='pca',verbose=1)
embedd = tsne.fit_transform(vector)
#可视化
plt.figure(figsize=(14,10))
plt.scatter(embedd[:100,0], embedd[:100,1])
for i in range(100):
x = embedd[i][0]
y = embedd[i][1]
plt.text(x, y, words[i],fontproperties=font)
plt.show()
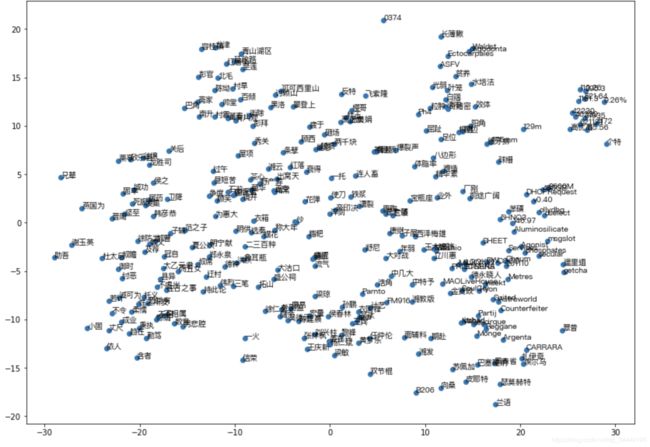
由于词向量比较大,选取其中一部分词降维,再选取一部分词画散点图,这节约了时间,但是准确度也会下降,有条件的可以用全量画,效果会更明显。画这幅图的目的是为了说明词向量的含义,它把词义相近的词映射到相近的区域内,理论上词义的相关性对应着词向量的几何距离,也就是词向量的几何关系应该表示这些词之间的语义关系,词向量的作用应该是将人类的语言映射到几何空间。
结束语
就不对这篇博文做总结了,内容比较少,看目录就比较清晰了,在这里聊聊闲话,记录自己的毕业设计。
这个周终于争取到了专门的时间来整论文,进了小黑屋,茫然怀念起本科毕业设计在实验室待的几个月的时光,只是身边少了那几台高大上的示波器和互相调侃的同学,总之还是找到了奋斗的动力,一定要坚持下去✊。
参考文献
- https://blog.csdn.net/FUCCKL/article/details/91850172
- https://www.cnblogs.com/peghoty/p/3857839.html