摘要:在互联网高度发达的今天,ipad、手机等智能终端设备随处可见,运行在其中的APP、网站也非常多,如何采集终端数据进行分析,提升软件的品质非常重要,例如PV/UV统计、用户行为数据统计与分析等。虽然场景简单,但是数据量大,对系统的吞吐量、实时性、分析能力、查询能力都有较高的要求,搭建起来并不容易。今天我们来介绍一下基于阿里云表格存储,以及相关的大数据产品来采集与分析数据的方案。
TableStore
TableStore(表格存储)是阿里云自主研发的专业级分布式NoSQL数据库,是基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台,支撑互联网和物联网数据的高效计算与分析。
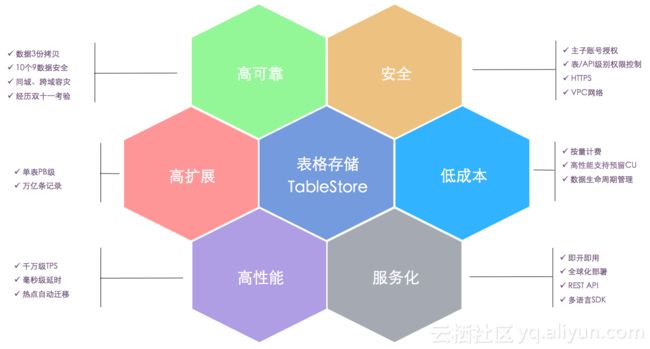
目前不管是阿里巴巴集团内部,还是外部公有云用户,都有成千上万的系统在使用。覆盖了重吞吐的离线应用,以及重稳定性,性能敏感的在线应用。表格存储的具体的特性可以看下面这张图片。
基于TableStore的数据采集分析系统
一个典型的数据采集分析统计平台,对数据的处理,主要由如下五个步骤组成:

对于上图流程的具体实现,网上有许多可以参考的案例,数据在客户端采集完以后,如果量比较小,我们可能直接在后端的API上做一次透传,然后持久化到RDBMS类型的数据库中就好了,通过Sql可以进行数据分析。如果数据量很大,就需要一些中间件来辅助收集和上传,然后分别将数据写入到在线和离线的系统中,比如先上传到Flume,Flume可以做数据的采集与聚合,再将Flume作为消息的生产者,将生产的消息数据通过Kafka Sink发布到Kafka中,Kafka作为消息队列的角色,可以对接后端的在线和离线计算平台。如下图所示:

引入Flume和Kafka的原因有很多,比如他们可以处理大流量的数据、做数据聚合、保证数据不丢失等,但最关键的原因是他们拥有高吞吐的能力。引入的组件多,系统的复杂性和成本也会相应的增加,上图中,Spark Streaming/Storm分析完成以后,结果数据还需要引入另外的存储组件进行存储,比如HBase/MySQL,如果引入MySQL可能还需要再引入Redis做热点数据缓存,这样一来就更加复杂了。
我们尝试一种基于TableStore和阿里云其他大数据产品的新方案,我们先看架构图:
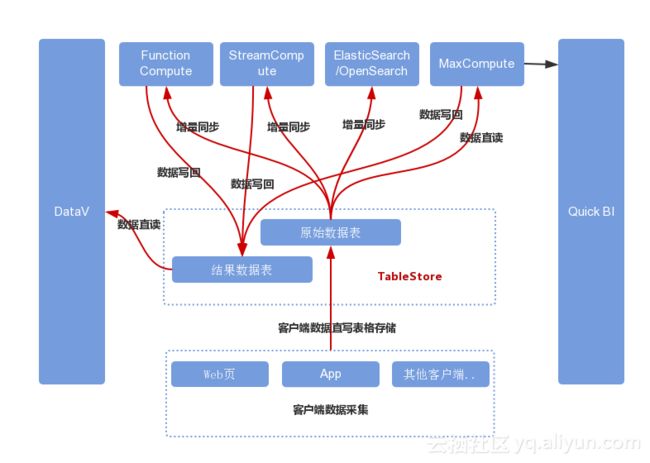
图中关键路径分析:
1、Web页、APP等客户端先通过埋点系统收集数据,然后通过表格存储的SDK将数据写入TableStore的原始数据表。
2、MaxCompute直读TableStore原始数据表的数据进行分析,然后QuickBI读取MaxCompute的数据进行展示,具体操作可参考:MaxCompute直读直写表格存储、QuickBI新建云数据源。
3、TableStore原始数据表中的数据可增量同步到ElasticSearch或者openSearch中,同步方法参考:TableStore数据同步到ElasticSearch,TableStore数据同步到OpenSearch。
4、TableStore中的数据可增量同步到Blink/Flink进行分析,分析完以后的数据再写回TableStore的结果数据表中,DavaV读取结果数据表的数据进行展示。
新架构优势分析:
1、客户端数据直读直写TableStore,不需要再引入API层进行数据透传,降低了复杂度,对于大型应用来说也减少了不少的服务器成本。
2、TableStore已经对接了丰富了大数据组件,包括阿里云的大数据产品和开源大数据产品,数据的同步与读写非常容易。
3、实时分析与离线分析后的结果数据再写回TableStore,DataV直接读取结果数据进行展示,因为TableStore具备高性能与高吞吐特点,不需要再引入Redis等缓存组件,可以简化整个系统。
直读直写安全问题:
关于数据直读直写TableStore,大家可能都会想到一个安全的问题,客户端直连TableStore不是要把AccessKey和AccessId暴露在客户端吗?答案是不用,我们使用STSToken授权访问TableStore,过程如下图所示:
