使用BeautifulSoup和lxml解析网页中的元素(一)
一、安装第三方爬虫库BeautifulSoup
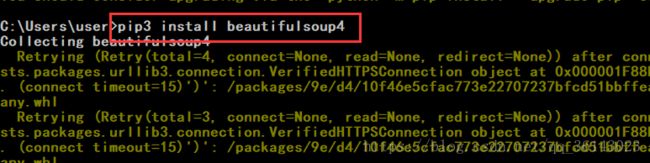
二、安装lxml类库
(1)首先,安装wheel。
先进入python安装目录下的scripts目录 cd xxxxxxxxpip3 install wheel(2)查看自己的python版本的支持情况

从网站下载对应版本支持的lxml的whl文件,网址为:
【点击打开链接】https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
下载完成后,在cmd中
pip install 绝对路径\文件名.whl
软件安装至此完毕。
二、用BeautifulSoup和lxml解析库解析网站
我用的是本地html文件进行的实验:
from bs4 import BeautifulSoup
with open("D:\\user\\Desktop\\the_blah.html") as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
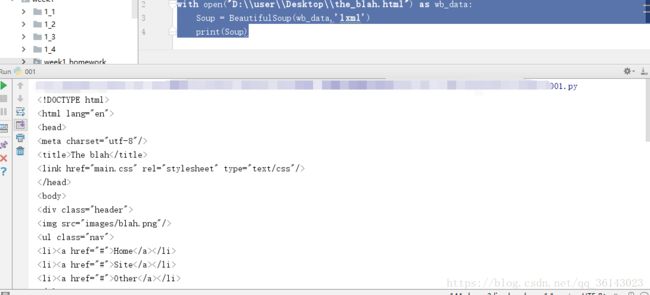
print(Soup)运行结果,解析出网站的html代码:
三、选择需要的网页元素并找到正确的路径
这里使用CSS Slector描述目的资源在html代码中的位置信息。比如要获得图片和描述,网站是这样子的:
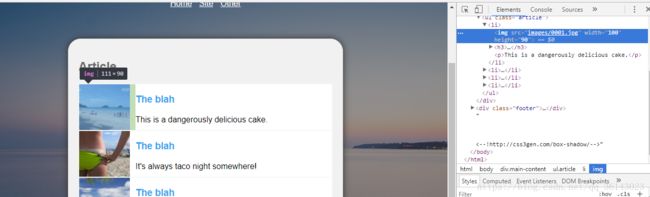
选择其中的一个图片,右击,选择 copy -> copy selector,黏贴后是这样的形式:
body > div.main - content > ul > li: nth - child(1) > img
由于这只是其中的一个图片,所以所有图片的位置描述应该是:
body > div.main-content > ul > li > img
然后使用beautifulsoup中的select方法可以挑选出这些符合条件的标签,效果如图:
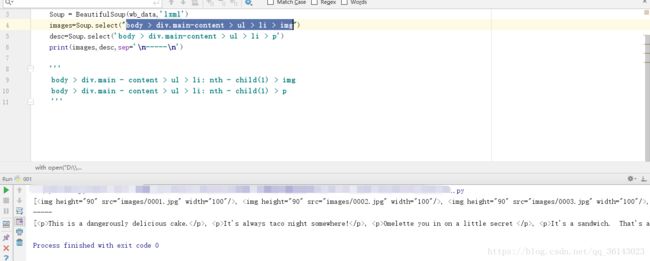
from bs4 import BeautifulSoup
with open("D:\\user\\Desktop\\the_blah.html") as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
images=Soup.select("body > div.main-content > ul > li > img")
desc=Soup.select('body > div.main-content > ul > li > p')
print(images,desc,sep='\n-----\n')四、从提取的标签中筛选所需的信息
文本信息使用get_text()函数
图片属性使用get('src')函数获得
代码如下:
from bs4 import BeautifulSoup
with open("D:\\user\\Desktop\\the_blah.html") as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
images=Soup.select("body > div.main-content > ul > li > img")
desc=Soup.select('body > div.main-content > ul > li > p')
#zip函数会返回一个以元组为元素的列表
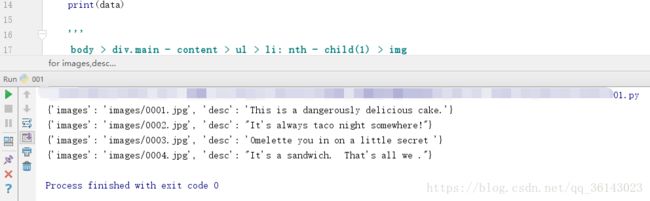
for images,desc in zip(images,desc):
data={
#获得属性用get函数
'images':images.get('src'),
'desc':desc.get_text()
}
print(data)运行结果:
最后按自己的要求操作字典、列表等,取出所需数据即可。