机器学习学习笔记(七)
(七)神经网络的学习
1.代价函数
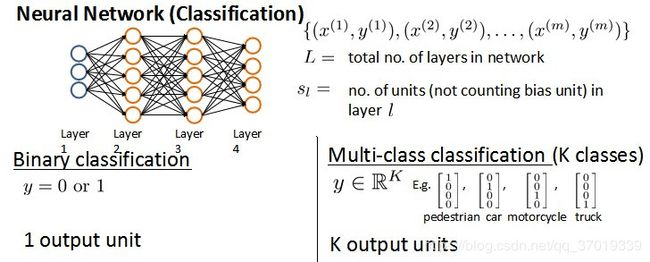
假设神经网络的训练样本有 m m m 个,每个包含一组输入 x x x 和一组输出信号 y y y , L L L 表示神经网络层数, S l S_l Sl 表示 l l l 层的neuron(神经元)个数( S l S_l Sl 中不包含第 l l l 层的偏差单元), S L S_L SL 代表最后一层中处理单元的个数。
将神经网络的分类定义为两种情况:二类分类和多类分类。
二类分类: S L = 1 , y = 0 o r 1 S_L = 1, y = 0 or 1 SL=1,y=0or1 表示两类中的一类;
K类分类: S L = k , y i = 1 S_L = k, y_i = 1 SL=k,yi=1 表示分到第 i i i 类( k > 2 k > 2 k>2 );
 我们回顾逻辑回归问题中我们的代价函数为:
我们回顾逻辑回归问题中我们的代价函数为:
J ( θ ) = − 1 m [ ∑ i = 1 m y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta) = -{1 \over m}[{\sum_{i=1}^{m}y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))}]+ {\lambda \over 2m}\sum_{j=1}^{n}\theta_j^2 J(θ)=−m1[i=1∑my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量 y y y ,但是在神经网络中,我们可以有很多输出变量,我们的 h θ ( x ) h_\theta(x) hθ(x) 是一个维度为 K K K 的向量,并且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,为: h θ ( x ) ∈ R K , ( h θ ( x ) ) i = i t h o u t p u t h_\theta(x) \in \mathbb{R}^K ,(h_\theta(x))_i = i^{th} output hθ(x)∈RK,(hθ(x))i=ithoutput
J ( θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 k y k ( i ) l o g ( h θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − ( h θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 S l ∑ j = 1 S l + 1 ( θ j i ( l ) ) 2 J(\theta) = -{1 \over m}[{\sum_{i=1}^{m}\sum_{k=1}^{k}y_k^{(i)}log(h_\theta(x^{(i)}))_k+(1-y_k^{(i)})log(1-(h_\theta(x^{(i)}))_k)}]+ {\lambda \over 2m}\sum_{l=1}^{L-1}\sum_{i=1}^{S_l}\sum_{j=1}^{S_l+1}(\theta_{ji}^{(l)})^2 J(θ)=−m1[i=1∑mk=1∑kyk(i)log(hθ(x(i)))k+(1−yk(i))log(1−(hθ(x(i)))k)]+2mλl=1∑L−1i=1∑Slj=1∑Sl+1(θji(l))2
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出 K K K 个预测,基本上我们可以利用循环,对每一行特征都预测 K K K 个不同结果,然后再利用循环在 K K K 个预测中选择可能性最高的一个,将其与 y y y 中的实际数据进行比较。
正则化的那一项只是排除了每一层 θ 0 \theta_0 θ0 后,每一层的 θ \theta θ 矩阵的和。最里层的循环 j j j 循环所有的行(由 S l + 1 S_l+1 Sl+1 层的激活单元数决定),循环 i i i 则循环所有的列,由该层( S l S_l Sl 层)的激活单元数所决定。即: h θ ( x ) h_\theta(x) hθ(x) 与真实值之间的距离为每个样本-每个类输出的加和,对参数进行regularization的bias(偏差)项处理所有参数的平方和。
2.反向传播算法
之前我们在计算神经网络预测结果的时候我们采用了一种正向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层的 h θ ( x ) h_\theta(x) hθ(x) 。
现在,为了计算代价函数的偏导数 ∂ ∂ θ i j ( l ) J ( θ ) {\partial \over \partial \theta_{ij}^{(l)}}J(\theta) ∂θij(l)∂J(θ) ,我们需要采用一种反向传播算法,也就是首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。 以一个例子来说明反向传播算法。
假设我们的训练集只有一个样本 ( x ( 1 ) , y ( 1 ) ) (x^{(1)}, y^{(1)}) (x(1),y(1)) ,我们的神经网络是一个四层的神经网络,其中 K = 4 , S L = 4 , L = 4 K = 4,S_L = 4,L = 4 K=4,SL=4,L=4:
前向传播算法:


我们从最后一层的误差开始计算,误差是激活单元的预测( a ( 4 ) a^{(4)} a(4) )与实际值( y k y^k yk)之间的误差,( k = 1 : k k = 1 : k k=1:k )。 我们用 δ \delta δ 来表示误差,则: δ ( 4 ) = a ( 4 ) − y \delta^{(4)} = a^{(4)} - y δ(4)=a(4)−y ,我们利用这个误差值来计算前一层的误差: δ ( 3 ) = ( θ ( 3 ) ) T δ ( 4 ) ∗ g ′ ( z ( 3 ) ) \delta^{(3)} = (\theta^{(3)})^T\delta^{(4)}*g'(z^{(3)}) δ(3)=(θ(3))Tδ(4)∗g′(z(3)) ,其中 g ′ ( z ( 3 ) ) g'(z^{(3)}) g′(z(3)) 是 S S S 形函数的导数, g ′ ( z ( 3 ) ) = a ( 3 ) ∗ ( 1 − a ( 3 ) ) g'(z^{(3)}) = a^{(3)}*(1-a^{(3)}) g′(z(3))=a(3)∗(1−a(3)) 。而 ( θ ( 3 ) ) T δ ( 4 ) (\theta^{(3)})^T\delta^{(4)} (θ(3))Tδ(4) 则是权重导致的误差的和。下一步是继续计算第二层的误差: δ ( 2 ) = ( θ ( 2 ) ) T δ ( 3 ) ∗ g ′ ( z ( 2 ) ) \delta^{(2)} = (\theta^{(2)})^T\delta^{(3)}*g'(z^{(2)}) δ(2)=(θ(2))Tδ(3)∗g′(z(2)) ,因为第一层是输入变量,不存在误差。我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了,假设 λ = 0 \lambda=0 λ=0 ,即我们不做任何正则化处理时有: ∂ ∂ θ i j ( l ) J ( θ ) = a j ( l ) δ i l + 1 {\partial \over \partial \theta_{ij}^{(l)}}J(\theta) = a_j^{(l)}\delta_i^{l+1} ∂θij(l)∂J(θ)=aj(l)δil+1
重要的是清楚地知道上面式子中上下标的含义:
l l l 代表目前所计算的是第几层。
j j j 代表目前计算层中的激活单元的下标,也将是下一层的第 j j j 个输入变量的下标。
i i i 代表下一层中误差单元的下标,是受到权重矩阵中第 i i i 行影响的下一层中的误差单元的下标。
如果我们考虑正则化处理,并且我们的训练集是一个特征矩阵而非向量。在上面的特殊情况中,我们需要计算每一层的误差单元来计算代价函数的偏导数。在更为一般的情况中,我们同样需要计算每一层的误差单元,但是我们需要为整个训练集计算误差单元,此时的误差单元也是一个矩阵,我们用 Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l) 来表示这个误差矩阵。第 l l l 层的第 i i i 个激活单元受到第 j j j 个参数影响而导致的误差。
我们的算法表示为:

即首先用正向传播方法计算出每一层的激活单元,利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播法计算出直至第二层的所有误差。
在求出了 Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l) 之后,我们便可以计算代价函数的偏导数了,计算方法如下:
D i j ( l ) : = 1 m Δ i j ( l ) + λ θ i j ( l ) ( i f j ≠ 0 ) D_{ij}^{(l)} := {1\over m}\Delta_{ij}^{(l)}+\lambda\theta_{ij}^{(l)} (if~~j \neq 0) Dij(l):=m1Δij(l)+λθij(l)(if j̸=0)
D i j ( l ) : = 1 m Δ i j ( l ) ( i f j = 0 ) D_{ij}^{(l)} := {1\over m}\Delta_{ij}^{(l)} (if~~j = 0) Dij(l):=m1Δij(l)(if j=0)
3.反向传播算法的直观理解
我们介绍了反向传播算法,对很多人来说,当第一次看到这种算法时,第一印象通常是,这个算法需要那么多繁杂的步骤,简直是太复杂了,实在不知道这些步骤,到底应该如何合在一起使用。就好像一个黑箱,里面充满了复杂的步骤。如果你对反向传播算法也有这种感受的话,这其实是正常的,相比于线性回归算法和逻辑回归算法而言,从数学的角度上讲,反向传播算法似乎并不简洁。
现在,我想更加深入地讨论一下反向传播算法的这些复杂的步骤,并且希望获得一 个更加全面直观的感受,理解这些步骤究竟是在做什么,也希望能理解,它至少还是一个合理的算法。但即便如此,这还是会让人觉得反向传播依然很复杂,依然像一个黑箱,太多复杂的步骤,依然感到有点神奇,这也是没关系的。为了更好地理解反向传播算法,我们再来仔细研究一下前向传播的原理:
前向传播算法:


反向传播算法做的是:


4.实现注意:展开参数
们谈到了怎样使用反向传播算法计算代价函数的导数。在这段视频中,我想快速地向你介绍一个细节的实现过程,怎样把你的参数从矩阵展开成向量,以便我们在高级最优化步骤中的使用需要。



5.梯度检验
当我们对一个较为复杂的模型(例如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果可能并不是最优解。
为了避免这样的问题,我们采取一种叫做梯度的数值检验(Numerical Gradient Checking)方法。这种方法的思想是通过估计梯度值来检验我们计算的导数值是否真的是我们要求的。
对梯度的估计采用的方法是在代价函数上沿着切线的方向选择离两个非常近的点,然后计算两个点的平均值用以估计梯度。即对于某个特定的 θ \theta θ ,我们计算出在 θ − ε \theta - \varepsilon θ−ε 处和 θ + ε \theta + \varepsilon θ+ε 的代价值( ε \varepsilon ε 是一个非常小的值,通常选取 0.001),然后求两个代价的平均,用以估计在 θ \theta θ 处的代价值。

6.随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。
我们通常初始参数为正负 ε \varepsilon ε 之间的随机值。
7.综合起来
小结一下使用神经网络时的步骤:
网络结构:第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
第一层的单元数即我们训练集的特征数量。
最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
1.参数的随机初始化
2.利用正向传播方法计算所有的 h θ ( x ) h_\theta(x) hθ(x)
3.编写计算代价函数 J J J 的代码
4.利用反向传播方法计算所有偏导数
5.利用数值检验方法检验这些偏导数
6.使用优化算法来最小化代价函数
8.自主驾驶
最后说一个具有历史意义的神经网络学习的重要例子。那就是使用神经网络来实现自动驾驶,也就是说使汽车通过学习来自己驾驶。
在下面也就是左下方,就是汽车所看到的前方的路况图像。
 在图中你依稀能看出一条道路,朝左延伸了一点,又向右了一点,然后上面的这幅图,你可以看到一条水平的菜单栏显示的是驾驶操作人选择的方向。就是这里的这条白亮的区段显示的就是人类驾驶者选择的方向。比如:最左边的区段,对应的操作就是向左急转,而最右端则对应向右急转的操作。因此,稍微靠左的区段,也就是中心稍微向左一点的位置,则表示在这一点上人类驾驶者的操作是慢慢的向左拐。
在图中你依稀能看出一条道路,朝左延伸了一点,又向右了一点,然后上面的这幅图,你可以看到一条水平的菜单栏显示的是驾驶操作人选择的方向。就是这里的这条白亮的区段显示的就是人类驾驶者选择的方向。比如:最左边的区段,对应的操作就是向左急转,而最右端则对应向右急转的操作。因此,稍微靠左的区段,也就是中心稍微向左一点的位置,则表示在这一点上人类驾驶者的操作是慢慢的向左拐。
这幅图的第二部分对应的就是学习算法选出的行驶方向。并且,类似的,这一条白亮的区段显示的就是神经网络在这里选择的行驶方向,是稍微的左转,并且实际上在神经网络开始学习之前,你会看到网络的输出是一条灰色的区段,就像这样的一条灰色区段覆盖着整个区域这些均称的灰色区域,显示出神经网络已经随机初始化了,并且初始化时,我们并不知道汽车如何行驶,或者说我们并不知道所选行驶方向。只有在学习算法运行了足够长的时间之后,才会有这条白色的区段出现在整条灰色区域之中。显示出一个具体的行驶方向这就表示神经网络算法,在这时候已经选出了一个明确的行驶方向,不像刚开始的时候,输出一段模糊的浅灰色区域,而是输出一条白亮的区段,表示已经选出了明确的行驶方向。