python爬取中国天气网天气并保存为csv格式文件
python版本:python3.7
编译器:pycharm
所爬取的网址:http://www.weather.com.cn/weather/101020100.shtml (中国天气网上海)
所用方法:lxml的css选择器
lxml的具体使用方法可以参照我另一篇博客:https://blog.csdn.net/qq_38929220/article/details/83623057
最后运行结果示例如图:
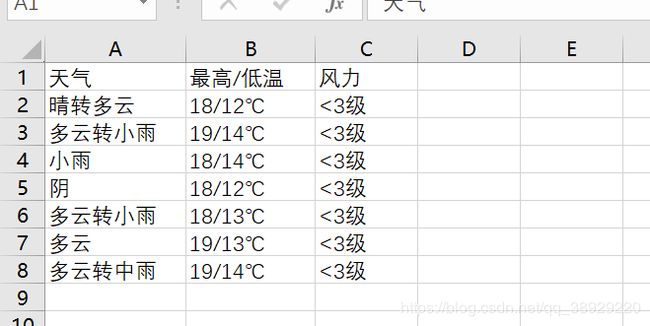
爬取思路
- 检查网站的robots.txt文件
- 查看网页源代码找到所要爬取的内容
- 写表达式爬取想要的内容
- 写入csv文件
检查网站的robots.txt文件
robots.txt文件定义了对爬虫的限制,可以直接手动在想要爬的网址后输入robots.txt查看
例:http://www.weather.com.cn/robots.txt
也可以通过代码实现,这样在爬取其他网页时也可以复用,爬多网页时比较方便。
# 检查url传递的robots.txt限制
if rp.can_fetch(user_agent, url):
throttle.wait(url)#延迟函数
html = download(url, headers, proxy=proxy, num_retries=num_retries)
查看网页源代码找到所要爬取的内容并爬取
右键网页点击查看网页源代码就可以看到网页的源代码。
找出想爬取信息对应的代码。

可以看出此网站的天气有wea、tem、win三个属性,均写在p标签里,没有定义父标签,可单独直接抓取。
td = tree.cssselect('p.wea,p.tem,p.win')
for wea in td:
#strip方法用于移除字符串头尾指定的字符
print(wea.text_content().strip('\n'))
写入csv文件
import csv
from urllib.parse import urlparse
import lxml.html
from link_crawler import link_crawler
import json
#使用回调类而非回调函数以保持csv中write属性的状态
class ScrapeCallback:
def __init__(self):
#不写newline=''的话会出现空行
self.writer = csv.writer(open('weather.csv', 'w',newline=''))
#天气 最高温/最低温 风力
self.fields = ('天气','最高/低温','风力')
self.writer.writerow(self.fields)
def __call__(self, url, html):
tree = lxml.html.fromstring(html)
td=tree.cssselect('p.wea')
n=0
for wea in td:
row=[]
row.append(tree.cssselect('p.wea')[n].text_content().strip('\n'))
row.append(tree.cssselect('p.tem')[n].text_content().strip('\n'))
row.append(tree.cssselect('p.win')[n].text_content().strip('\n'))
n=n+1
self.writer.writerow(row)
全部源码(适用于多页):
import re
from urllib.parse import urlparse,urljoin,urlsplit
import urllib.request
import time
from datetime import datetime
import urllib.robotparser
import queue
def link_crawler(seed_url, link_regex=None, delay=5, max_depth=-1, max_urls=-1, headers=None, user_agent='wswp', proxy=None, num_retries=1, scrape_callback=None):
"""
在link_regex匹配的链接之后从给定的种子URL抓取
"""
# 仍需要抓取的URL队列
crawl_queue = [seed_url]
# 已经看到深度的URL
seen = {seed_url: 0}
# 追踪有多少URL被下载过
num_urls = 0
rp = get_robots(seed_url)
throttle = Throttle(delay)
headers = headers or {}
if user_agent:
headers['User-agent'] = user_agent
while crawl_queue:
url = crawl_queue.pop()
depth = seen[url]
# 检查url传递的robots.txt限制
if rp.can_fetch(user_agent, url):
throttle.wait(url)
html = download(url, headers, proxy=proxy, num_retries=num_retries)
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
#未达到最大深度,仍可以进一步爬取
if depth != max_depth:
if link_regex:
# 筛选符合正则表达式的链接
links.extend(link for link in get_links(html) if re.match(link_regex, link))
for link in links:
link = normalize(seed_url, link)
# 检查是否已抓取此链接
if link not in seen:
seen[link] = depth + 1
# 检查链接是否在同一个域内
if same_domain(seed_url, link):
# 成功! 将此新链接添加到队列
crawl_queue.append(link)
# 检查是否已达到下载的最大值
num_urls += 1
if num_urls == max_urls:
break
else:
print ('Blocked by robots.txt:', url)
#节流
class Throttle:
"""
通过在对同一域之间请求休眠来限制下载
"""
def __init__(self, delay):
#每个域的下载之间的延迟量
self.delay = delay
# 上次访问域时的时间戳
self.domains = {}
def wait(self, url):
"""
如果最近访问过这个域,则会延迟
"""
domain = urlsplit(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
#下载网址
def download(url, headers, proxy, num_retries, data=None):
print ('Downloading:', url)
request = urllib.request.Request(url, data, headers)
opener = urllib.request.build_opener()
if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib.request.ProxyHandler(proxy_params))
try:
response = opener.open(request)
html = response.read()
code = response.code
except urllib2.URLError as e:
print( 'Download error:', e.reason)
html = ''
if hasattr(e, 'code'):
code = e.code
if num_retries > 0 and 500 <= code < 600:
# 重试 5XX HTTP errors(服务器错误)
html = download(url, headers, proxy, num_retries-1, data)
else:
code = None
#python3需转化html编码格式
html = html.decode('utf-8')
return html
def normalize(seed_url, link):
"""
通过删除哈希和添加域来规范化此URL
"""
link, _ = urlparse.urldefrag(link) # 删除哈希以避免重复
return urlparse.urljoin(seed_url, link)
def same_domain(url1, url2):
"""
如果两个URL都属于同一个域,则返回True
"""
return urlparse.urlparse(url1).netloc == urlparse.urlparse(url2).netloc
def get_robots(url):
"""
初始化此域的机器人解析器
"""
rp = urllib.robotparser.RobotFileParser()
rp.set_url(urljoin(url, '/robots.txt'))
rp.read()
return rp
def get_links(html):
"""
从html返回链接列表
"""
#一个正则表达式,用于从网页中提取所有链接
webpage_regex = re.compile(']+href=["\'](.*?)["\']' , re.IGNORECASE)
# 来自网页的所有链接的列表
return webpage_regex.findall(html)
'''
if __name__ == '__main__'的意思是:当.py文件被直接运行时,
if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被
导入时,if __name__ == '__main__'之下的代码块不被运行。
'''
if __name__ == '__main__':
link_crawler('http://www.weather.com.cn/weather/101020100.shtml', '/(index|view)', delay=0, num_retries=1, user_agent='BadCrawler')
link_crawler('http://www.weather.com.cn/weather/101020100.shtml', '/(index|view)', delay=0, num_retries=1, max_depth=1, user_agent='GoodCrawler')
import csv
from urllib.parse import urlparse
import lxml.html
from link_crawler import link_crawler
#使用回调类而非回调函数以保持csv中write属性的状态
class ScrapeCallback:
def __init__(self):
#不写newline=''的话会出现空行
self.writer = csv.writer(open('weather.csv', 'w',newline=''))
#天气 最高温/最低温 风力
self.fields = ('天气','最高/低温','风力')
self.writer.writerow(self.fields)
def __call__(self, url, html):
tree = lxml.html.fromstring(html)
td=tree.cssselect('p.wea')
n=0
for wea in td:
row=[]
row.append(tree.cssselect('p.wea')[n].text_content().strip('\n'))
row.append(tree.cssselect('p.tem')[n].text_content().strip('\n'))
row.append(tree.cssselect('p.win')[n].text_content().strip('\n'))
n=n+1
self.writer.writerow(row)
if __name__ == '__main__':
html='http://www.weather.com.cn/weather/101020100.shtml'
link_crawler(html, '/(index|view)', scrape_callback=ScrapeCallback())