c/c++编译原理浅谈(二)
-------------前言
浑浑噩噩就看完了一遍《高级c/c++编译技术》,我知道看完一遍是不行,而且光是看也是不行的,先写下这篇博文也权当是记录下我的一些猜想,当然是未经过验证的,经过验证就不是猜想了。最终,在下有什么说得不对的,请各位大侠指正,不断学习不断进步!
-------------正文
先说一下这本书。这本书是由Milan Stevanovic大佬写的,卢誉声所译。结构内容是硬件基础,程序的生命周期,生命周期中的各个阶段的介绍,各类问题的解决。
我觉得有必要介绍以下目标文件的属性,因为没有截图,所以我就直接把书上的内容码上来。大家可以对照着自己的程序看看。
1.符号(symbol)和节(section)是目标文件的基本组成部分,其中符号表示的是程序中的内存地址或数据结构。(这里需要注意,往后我们会非常关注内存地址这个东西)
2.绝大多数的目标文件中都包含代码节(.text)、初始化数据节(.data)、未初始化数据节(.bss)以及一些特殊节(比如调试信息),这个大家可以对照着看看。
3.我们的目的是:将编译的每个独立的源代码文件生成的节拼接到一个二进制可执行文件中。
如何拼接呢?这就是咱们接下来要讨论的问题。
1.目标文件中独立的节都有可能包含在最终的程序内存映射中,因为每个目标文件中每个节的起始地址都会被临时设置为0,等待链接时调整,确程序内存映射中每个独立节的实际地址范围。
2.目标文件中不存在专门的节会影响堆与栈的数据,内存映射中的堆与栈内容完全在程序运行时确定。
以上,将所有目标文件的节集合在一起需要一个标准,需要一个规则,不然怎么集合的完全完整高效呢?这就有了各种平台的规范,比如,可执行文件(exe(win)、EXEC(linux))、静态库(lib(win)、a(linux))、动态库(dll(win)、so(linux))。
ok,那么我们就知道了输入输出是什么了。
输入:一系列目标文件的集合
输出:规范的二进制文件(可执行文件、静态库、动态库)
1.重定位
链接过程的第一个阶段紧紧进行拼接,其过程是将分散在单独不表文件中的不同类型的节拼接带程序内u才能映射节中。为了完成该认为有,需要将之前预留的控件,也就是节中从0开始的地址范围转换成最终程序内存映射中更具体的地址范围。
2.解析引用
重定位已经完成地址的线性转成成程序内存映射地址范围。然后我们还得完成一个非常艰巨的任务就是要把各个部分的联系简历起来,使得程序成为一个整体。我们的函数和变量可以分成两种类型,一种是在当前目标文件节中的函数和变量,可以直接通过节中的变对位置就可以寻址成功,而另一种就是在其他目标文件中的函数和变量,我们要做的就是找出那些是这些变量,并找出它的准确地址(内存映射中的地址)。
最后,将机器指令中的伪地址替换成程序内存映射的实际地址,这样我们链接的任务就完成了。
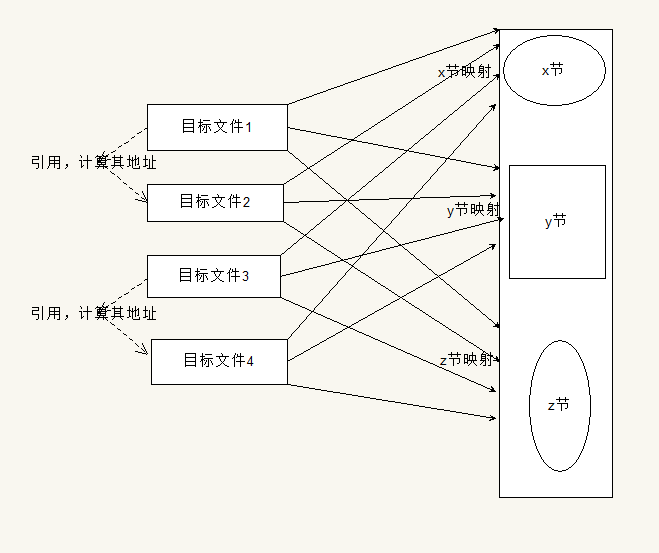
至于它通过什么算法找到“在外”的函数和变量和计算出他们的地址,这我就不知道了。
使用linux下的gcc进行示例:
gcc -c function.c main.c //生成两个目标文件
gcc function.o main.o -o demoApp //生成可执行文件
这个就是我们每次编程的时候生成的可执行文件了,是不是很神奇呢?但是需要注意的一点是:
crt0是“纯粹”的入口点,而不是我们通常看到的main函数的入口,它的程序代码的第一部分,在内核控制下执行。
crt1是更为现代化的启动例程(startprountime),可以在main函数执行前与程序终止后完成一些任务。

这里就说到这,请看下一篇。