python爬虫实战——运用requests批量下载qq音乐
-
python -qq音乐爬取
在学习一段时间后,在视频的讲解下,觉得自己掌握的不错,就开始了这一次的qq音乐的爬取,在爬取的过程中发现了很多问题。知识点掌握的不够,知识点掌握的不熟,例如:正则表达式的使用等。不过困难也一个个解决,最后完成了这次的爬取任务。
任意选取一个歌单的的歌曲进行下载。
首先:我的思路是从音乐的下载链接动手逆推寻找需要的元素。
选取一个关于古风的歌单,
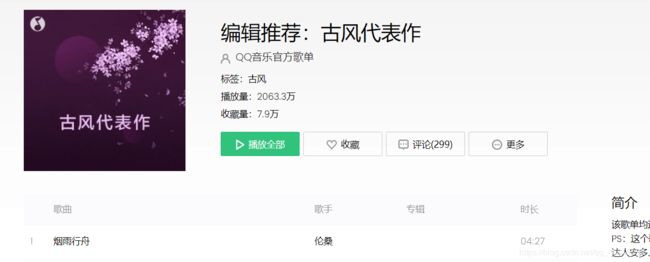
播放第一首歌进入播放页面,右键点击检查->network 然后刷新页面,再次点击播放,到这我也不知道哪个是下载链接,查了下,下载链接一般放在状态码为206的里面,点击status找到206
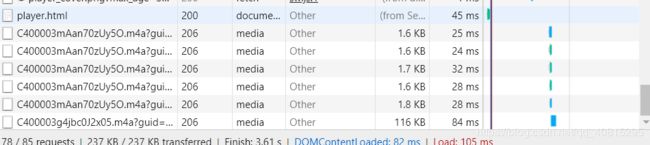 内容和另几个不同的,这里就是最后一个点击它
内容和另几个不同的,这里就是最后一个点击它
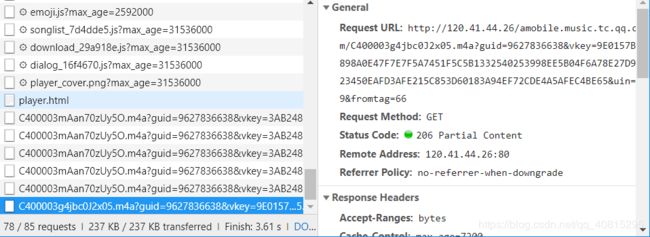
复制它的url去浏览器中试验下看看有没有错误。

得到的是这个就是正确的下载链接。
然后我们拿另一首歌也进行相同的操作。
Request URL: http://120.41.44.26/amobile.music.tc.qq.com/C400003g4jbc0J2x05.m4a?guid=9627836638&vkey=9E0157B25898A0E47F7E7F5A7451F5C5B1332540253998EE5B04F6A78E27D94A23450EAFD3AFE215C853D60183A94EF72CDE4A5AFEC4BE65&uin=799&fromtag=66
两个url在进行对比之下
Request URL: http://120.41.44.26/amobile.music.tc.qq.com/C400
003g4jbc0J2x05.m4a?(不同)
guid=9627836638
&vkey=9E0157B25898A0E47F7E7F5A7451F5C5B1332540253998EE5B04F6A78E27D94A23450EAFD3AFE215C853D60183A94EF72CDE4A5AFEC4BE65(不同)
&uin=799
&fromtag=66
有两个值是不同的。
然后我们需要在这里面找到这两个不同的属性值。
在这八十多个文件中一个个查(查看Preview),我们首先进最有可能的XHR中寻找
![]()
再这个文件中我们找到了我们需要的值,存在了这个XHR的purl中,来到headers,查看URL。
https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey5503321846419544&g_tk=2032367742&loginUin=1028530975&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req"%3A{"module"%3A"CDN.SrfCdnDispatchServer"%2C"method"%3A"GetCdnDispatch"%2C"param"%3A{"guid"%3A"9627836638"%2C"calltype"%3A0%2C"userip"%3A""}}%2C"req_0"%3A{"module"%3A"vkey.GetVkeyServer"%2C"method"%3A"CgiGetVkey"%2C"param"%3A{"guid"%3A"9627836638"%2C"
songmid%22%3A%5B%22
003g4jbc0J2x05
%22%5D%2C%22songtype%22%3A%5B0%5D%2C%22uin%22%3A%221028530975%22%2C%22loginflag%22%3A1%2C%22platform%22%3A%2220%22%7D%7D%2C%22comm%22%3A%7B%22uin%22%3A1028530975%2C%22format%22%3A%22json%22%2C%22ct%22%3A24%2C%22cv%22%3A0%7D%7D
另一个歌曲一样进行相同操作找到这个链接进行对比。发现两者不同之处在于songmid%22%3A%5B%22后的这个003g4jbc0J2x05,也就是每首歌曲的id。这时候我们就要去歌单页面找到每首歌的id就基本大功告成了。来到歌单页面一样进行检查XHR,逐个检查preview。
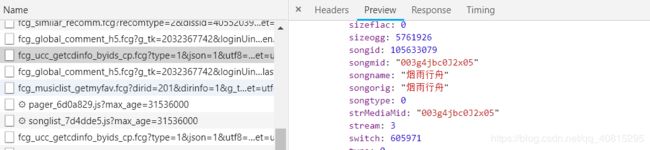
最后我们找到了这个,songmid就是我们需要的歌曲id,songname就是歌曲名称

歌单的资料都在里面,找到URL,这时候我们只需要用正则表达式提取里面的内容就行。
然后这里是我遇到最大的问题,在用requests提取源代码的时候
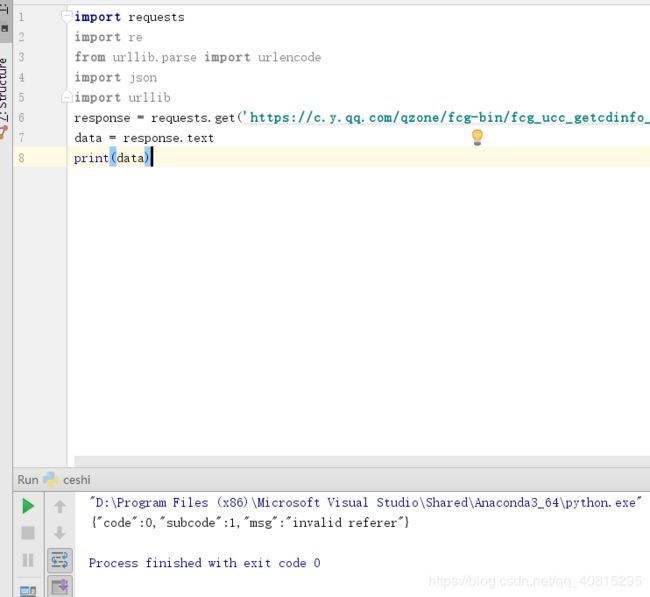
requests的get请求得不到网页里的值,一开始是以为Ajax请求的原因,就各种测试。结果最后发现是Referer: https://y.qq.com/n/yqq/playlist/4055203913.html
这个值的问题,只需要在haeders加入这个就可以了,这样我就加入一个请求头就可以提取这个源代码了。这里推荐一个构造请求头的网址。详情请参考知乎:
https://www.zhihu.com/question/60685487
分析到这里后就差不多可以动手写代码实现了。
代码实现很简单,难点是找到所需要的元素,下面贴一下代码:
import requests
import re
from urllib.parse import urlencode
import json
import urllib
url ='https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?’
headers = {
‘authority’: ‘y.qq.com’,
‘cache-control’: ‘max-age=0’,
‘upgrade-insecure-requests’: ‘1’,
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36’,
‘accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8’,
‘referer’: ‘https://y.qq.com/portal/profile.html’,
‘accept-encoding’: ‘gzip, deflate, br’,
‘accept-language’: ‘zh-CN,zh;q=0.9’,
‘cookie’: ‘*’,
}#这里cookie我隐藏了,需要你们自己加入
response = requests.get(‘https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?type=1&json=1&utf8=1&onlysong=0&disstid=4055203913&g_tk=2032367742&loginUin=1028530975&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0’, headers=headers)
data = response.text
results = re.findall(’,“songmid”:"(.?)",“songname”’,data,re.S)#取出歌曲id存入列表
results2 = re.findall(’“songname”:"(.?)",“songorig”’,data,re.S)#取出歌曲名字存入列表
sum = len(results)#歌曲数量
for m in range(0,sum):
url = ‘https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey4430392461792736&g_tk=2032367742&loginUin=1028530975&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={“req_0”%3A{“module”%3A"vkey.GetVkeyServer"%2C"method"%3A"CgiGetVkey"%2C"param"%3A{“guid”%3A"9627836638"%2C"songmid"%3A["’+results[m]+’"]%2C"songtype"%3A[0]%2C"uin"%3A"1028530975"%2C"loginflag"%3A1%2C"platform"%3A"20"}}%2C"comm"%3A{“uin”%3A1028530975%2C"format"%3A"json"%2C"ct"%3A24%2C"cv"%3A0}}’
browser= requests.get(url)
data2 = browser.text
aw = re.search(’,“purl”:“C400(.*?)”,“qmdlfromtag”’,data2,re.S).group(1)#取出purl
url2 = ‘http://27.152.180.23/amobile.music.tc.qq.com/C400’+aw
urllib.request.urlretrieve(url2,‘D:\We\作业\python\qqmp4\’+results2[m]+’.mp4’)#用urlretrieve进行下载文件,第一个参数是下载链接,第二个参数是下载保存的路径
到这就结束了,如果要做搜索的也很简单,关键找到前面几个元素就行了。
这个做完后最大的收获就是知道了关看是没用的,一定要多写!多写!多写!