逻辑回归——梯度下降法(原理推导和自定义代码实现)
往期线性回归文章:
线性回归——二维线性回归方程(证明和代码实现)
线性回归——最小二乘法(公式推导和非调包实现)
线性回归——梯度下降法(公式推导和自定义代码实现)
前言:
前面博主已经做了三期的线性回归算法的推导了,我们今天换个主题,来谈谈逻辑回归的原理,算法逻辑,和如何自定义代码实现这个算法,因为本文会提到梯度下降法的一些用法,但是由于梯度下降法的原理博主在前一篇文章中已经详细介绍了梯度下降法的原理.所以本文会侧重于算法中梯度下降方向的使用,至于这样做为什么会得到最优解,不清楚的读者不妨参考博主上一期文章的推导过程.那废话不多说了,进入今天的主题:
一、逻辑回归是回归算法?
- 当然不是啦,你别被它的名字所迷惑了,虽然它的名字当中带有回归二字,但是它却是一个彻彻底底的分类算法,而且还是一个经典的二分类回归算法.所以这里还需留意,为什么它被归到分类算法的类别当中呢,不妨来看一下它的实现过程与原理
二、算法原理及推导
- 其实吧逻辑回归算法既然名字当中带有回归二字,那必然是有原因的,那是因为它就是通过线性回归的算法模型然后衍生出来的.
- 我们先来看一个函数:
g ( x ) = 1 1 + e − x \displaystyle g(x)=\frac{1}{1+e^{-x}} g(x)=1+e−x1
它名字叫做Sigmoid函数,通常它就是用来将连续的数据变为离散的数据的,我们来看看它的函数图像吧:
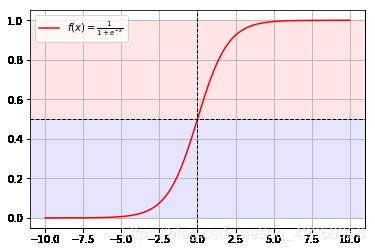
博主故意将函数的纵轴从y=0.5为分界线划分成了红,蓝两个区域,可以看到这个函数的取值就是在0~1之间的, - 那么如何利用Sigmoid函数来进行分类呢?
打个比方现在我有一些数据 [ x 1 , x 2 , ⋯ , x n ] [x_1,x_2,\cdots,x_n] [x1,x2,⋯,xn]
我们将 x i x_i xi传入 Sigmoid 函数当中来计算,那么必然就可以得到一些 0~1 之间的数值.
我们从 0.5 为界分割线开始划分,
如果 g ( x i ) > 0.5 g(x_i) \gt 0.5 g(xi)>0.5我们就把 x i x_i xi 归到类别一当中;
如果 g ( x i ) < 0.5 g(x_i) \lt 0.5 g(xi)<0.5我们就把 x i x_i xi 归到类别二当中:
这不我们就将数据分为两类了吗. - 如何从线性回归转到逻辑回归
还记得线性回归的模型吗:
y ^ = θ T X = ( θ 0 + θ 1 + ⋯ + θ m ) \displaystyle \hat{y}=\theta^TX=(\theta_0+\theta_1+\cdots+\theta_m) y^=θTX=(θ0+θ1+⋯+θm)
我们根据上面的模型,传入对应的特征数据那么模型就会给我们计算出一个预测结果 ( y ^ ) (\hat{y}) (y^) 来,我们都知道这个预测值还是一个连续的变量,所以我们不妨将 y ^ \hat{y} y^带入Sigmoid函数中来看,就有了一个新的预测模型:
h θ ( X ) = g ( θ T X ) = 1 1 + e − θ T X \displaystyle h_\theta(X)=g(\theta^TX)=\frac{1}{1+e^{-\theta^TX}} hθ(X)=g(θTX)=1+e−θTX1
很明显 0 < h θ ( X ) < 1 0 \lt h_\theta(X) \lt 1 0<hθ(X)<1,我们再根据 $ h_\theta(X)$ 是否大于 0.5 来判断该样本属于哪一类.
这就是逻辑回归的核心原理 - 求解方法推导
既然原理已经清楚了,现在我们该来谈谈如来进行计算:
我们在回到刚才的公式上来,既然 g ( θ T X ) g(\theta^TX) g(θTX)的取值是0到1之间,不妨我们把它的值看成是概率,那么就有下面的表示:
{ p ( y = 1 ∣ x ; θ ) = h θ ( X ) p ( y = 0 ∣ x ; θ ) = 1 − h θ ( X ) \begin{cases} p(y=1|x;\theta)= h_\theta(X)\\ p(y=0|x;\theta)= 1-h_\theta(X) \end{cases} {p(y=1∣x;θ)=hθ(X)p(y=0∣x;θ)=1−hθ(X)
我们可以将两个式子合并一下,用一个式子来表示:
p ( y ∣ x ; θ ) = ( h θ ( X ) ) y ( 1 − h θ ( X ) ) 1 − y , y ∈ { 0 , 1 } p(y|x;\theta)=(h_\theta(X))^y(1-h_\theta(X))^{1-y}\ ,\ y\in\{0,1\} p(y∣x;θ)=(hθ(X))y(1−hθ(X))1−y , y∈{0,1}
可以看到当y=1时:
p ( y ∣ x ; θ ) = h θ ( X ) p(y|x;\theta)= h_\theta(X) p(y∣x;θ)=hθ(X)
当y=0时:
p ( y ∣ x ; θ ) = 1 − h θ ( X ) p(y|x;\theta)= 1-h_\theta(X) p(y∣x;θ)=1−hθ(X)
有了合并后的公式,我们再来通过训练样本来计算公式的准确度,我们知道上面我们得到的那个式子就是用来计算传入的特征为这个类别y的概率值的.就是下面的这个意思:
我有一行样本数据: x 0 = [ x 01 , x 02 , ⋯ , x 0 n ] , y 0 = 1 x_0=[x_{01},x_{02},\cdots,x_{0n}], y_0=1 x0=[x01,x02,⋯,x0n],y0=1
我们将样本数据传入上面的公式当中就会得到一个概率 p :
这个p值有两层含义,第一层很容易就可以想到就表示此行样本为类别1的概率,
第二层含义就要转一个弯了,p 可以表示为本次预测的与真实值的匹配度,为什么呢?你想,假如 p = 1,你想是不是这个概率表示此次模型预测的结果与样本的真实结果完全匹配;如果 p=0 ,那么就表示此次预测与样本真实值毫不相关.当然举的是两个极端的例子,那么中间的概率自然可以用作预测值和真实值的匹配度嘛.概率越接近 1 表示预测结果与真实值越匹配,概率越接近0就表示预测值与真实值相差越远.
有了第二层含义的基础我们就可以将整个样本计算出来的预测集连乘起来,那么就可以写出下面这个式子:
L ( θ ) = ∏ i = 1 n ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i \displaystyle L(\theta)=\prod_{i=1}^n{(h_\theta(x_i))^{y_i}(1-h_\theta(x_i))^{1-y_i}} L(θ)=i=1∏n(hθ(xi))yi(1−hθ(xi))1−yi
上面这个式子就叫做似然函数,用它的值来表示 θ \theta θ(也就是我们通过训练得出的所有x前面的系数),通过这个 θ \theta θ所构建的这个模型与数据真实模型的相似程度.
因为乘法并不便于后期我们的计算,所以我们要想个法子将它变成加法,没错就是两边同时取对数:
log L ( θ ) = log [ ∏ i = 1 n ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i ] \displaystyle \log{ L(\theta)}=\log{\left[\prod_{i=1}^n{(h_\theta(x_i))^{y_i}(1-h_\theta(x_i))^{1-y_i}}\right]} logL(θ)=log[i=1∏n(hθ(xi))yi(1−hθ(xi))1−yi]
由 log a b c = log a b + log a c \log_a{bc}=\log_ab+\log_ac logabc=logab+logac 性质可得:
log L ( θ ) = ∑ i = 1 n [ log ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i ] \displaystyle \log{ L(\theta)}=\sum_{i=1}^n{\left[\log{(h_\theta(x_i))^{y_i}(1-h_\theta(x_i))^{1-y_i}}\right]} logL(θ)=i=1∑n[log(hθ(xi))yi(1−hθ(xi))1−yi]
再由 log a x = x log a \log{a^x}=x\log{a} logax=xloga性质可得:
l ( θ ) = log L ( θ ) = ∑ i = 1 n [ y i log ( h θ ( x i ) ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ] \displaystyle l(\theta)=\log{ L(\theta)}=\sum_{i=1}^n{\left[y_i\log(h_\theta(x_i))+(1-y_i)\log(1-h_\theta(x_i))\right]} l(θ)=logL(θ)=i=1∑n[yilog(hθ(xi))+(1−yi)log(1−hθ(xi))]
上面这个式子就叫对数似然函数.
现在为了让我们训练出来的 θ \theta θ 值对应的模型与真实模型拟合度最高,所以就需要不断改变 θ \theta θ,然后让 l ( θ ) l(\theta) l(θ) 的值取得最大,当 l ( θ ) l(\theta) l(θ)的值去得最大时,此时的 θ \theta θ 也就是我们训练出的最好的参数组合,根据上面的式子我们发现此时的 l ( θ ) l(\theta) l(θ)还与样本数量n具有有相关型,为了使它脱离与样本数量的关系,我们就对它取一下平均数就好,也就是除以样本数量n.还有我们要使用梯度下降法,但是这里我们是求的最大值,所以我们要将它转换一下,变成求最小值,所以给它前面加上一个负号即可.综上所处我们就可以把公式表示成这样:
J ( θ ) = − 1 n l ( θ ) = − 1 n ∑ i = 1 n [ y i log ( h θ ( x i ) ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ] J(\theta)=-\frac{1}{n}l(\theta)=-\frac{1}{n} \sum_{i=1}^n{\left[y_i\log(h_\theta(x_i))+(1-y_i)\log(1-h_\theta(x_i))\right]} J(θ)=−n1l(θ)=−n1i=1∑n[yilog(hθ(xi))+(1−yi)log(1−hθ(xi))]
好了现在我们就可以根据梯度下降的流程走了:
(1).第一步就是求各个 θ \theta θ分量的偏导作为下降的方向:
δ J ( θ ) δ ( θ j ) = − 1 n δ ( ∑ i = 1 n [ y i log ( h θ ( x i ) ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ] ) δ ( θ j ) \displaystyle \frac{\delta{J(\theta)}}{\delta(\theta_j)}=-\frac{1}{n}\frac{\displaystyle \delta( \sum_{i=1}^n{\left[y_i\log{(h_\theta(x_i))+(1-y_i)\log(1-h_\theta(x_i))}\right]})}{\delta(\theta_j)} δ(θj)δJ(θ)=−n1δ(θj)δ(i=1∑n[yilog(hθ(xi))+(1−yi)log(1−hθ(xi))])
根据 δ ( log x ) δ ( x ) = 1 x \displaystyle \frac{\delta(\log{x})}{\delta(x)}=\frac{1}{x} δ(x)δ(logx)=x1和求导分配率,复合函数求导法则可以得:
= − 1 n ∑ i = 1 n ( y i 1 h θ ( x i ) δ ( h θ ( x i ) ) δ ( θ j ) + ( 1 − y i ) − 1 1 − h θ ( x i ) δ ( h θ ( x i ) ) δ ( θ j ) ) \displaystyle =-\frac{1}{n} \sum_{i=1}^n{\left(y_i\frac{1}{h_\theta(x_i)}\frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}+(1-y_i)\frac{-1}{1-h_\theta(x_i)}\frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}\right)} =−n1i=1∑n(yihθ(xi)1δ(θj)δ(hθ(xi))+(1−yi)1−hθ(xi)−1δ(θj)δ(hθ(xi)))
因为 h θ ( X ) = g ( θ T X ) \displaystyle h_\theta(X)=g(\theta^TX) hθ(X)=g(θTX),那么化简可得:
= − 1 n ∑ i = 1 n ( y i 1 g ( θ T x i ) − ( 1 − y i ) 1 1 − g ( θ T x i ) ) δ ( h θ ( x i ) ) δ ( θ j ) \displaystyle =-\frac{1}{n} \sum_{i=1}^n{\left(y_i\frac{1}{g(\theta^Tx_i)}-(1-y_i)\frac{1}{1-g(\theta^Tx_i)}\right)\frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}} =−n1i=1∑n(yig(θTxi)1−(1−yi)1−g(θTxi)1)δ(θj)δ(hθ(xi))
现在来求 δ ( h θ ( x i ) ) δ ( θ j ) \displaystyle \frac{\delta(h_\theta(x_i))}{\delta(\theta_j)} δ(θj)δ(hθ(xi)),因为 h θ ( x i ) = 1 1 + e − θ T x i \displaystyle h_\theta(x_i)=\frac{1}{1+e^{-\theta^Tx_i}} hθ(xi)=1+e−θTxi1所以求导可得:
δ ( h θ ( x i ) ) δ ( θ j ) = − 1 ( 1 + e − θ T x i ) 2 ( − e − θ T x i ) δ ( θ T x i ) δ ( θ j ) \displaystyle \frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}=\frac{-1}{(1+e^{-\theta^Tx_i})^2}(-e^{-\theta^Tx_i})\frac{\delta(\theta^Tx_i)}{\delta(\theta_j)} δ(θj)δ(hθ(xi))=(1+e−θTxi)2−1(−e−θTxi)δ(θj)δ(θTxi)
化简,在配方可得:
δ ( h θ ( x i ) ) δ ( θ j ) = 1 1 + e − θ T x i 1 + e − θ T x i − 1 1 + e − θ T x i δ ( θ T x i ) δ ( θ j ) \displaystyle \frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}=\frac{1}{1+e^{-\theta^Tx_i}}\frac{1+e^{-\theta^Tx_i}-1}{1+e^{-\theta^Tx_i}}\frac{\delta(\theta^Tx_i)}{\delta(\theta_j)} δ(θj)δ(hθ(xi))=1+e−θTxi11+e−θTxi1+e−θTxi−1δ(θj)δ(θTxi)
约分.合并后可得:
δ ( h θ ( x i ) ) δ ( θ j ) = g ( θ T x i ) ( 1 − g ( θ T x i ) ) δ ( θ T x i ) δ ( θ j ) \displaystyle \frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}=g(\theta^Tx_i)(1-g(\theta^Tx_i))\frac{\delta(\theta^Tx_i)}{\delta(\theta_j)} δ(θj)δ(hθ(xi))=g(θTxi)(1−g(θTxi))δ(θj)δ(θTxi)
现在再把这个结果带入到刚才的表达式当中就有:
δ J ( θ ) δ ( θ j ) = − 1 n ∑ i = 1 n ( y i 1 g ( θ T x i ) − ( 1 − y i ) 1 1 − g ( θ T x i ) ) g ( θ T x i ) ( 1 − g ( θ T x i ) ) δ ( θ T x i ) δ ( θ j ) \displaystyle \frac{\delta{J(\theta)}}{\delta(\theta_j)}=-\frac{1}{n} \sum_{i=1}^n{\left(y_i\frac{1}{g(\theta^Tx_i)}-(1-y_i)\frac{1}{1-g(\theta^Tx_i)}\right)g(\theta^Tx_i)(1-g(\theta^Tx_i))\frac{\delta(\theta^Tx_i)}{\delta(\theta_j)}} δ(θj)δJ(θ)=−n1i=1∑n(yig(θTxi)1−(1−yi)1−g(θTxi)1)g(θTxi)(1−g(θTxi))δ(θj)δ(θTxi)
约分并化简:
δ J ( θ ) δ ( θ j ) = − 1 n ∑ i = 1 n ( y i ( 1 − g ( θ T x i ) ) − ( 1 − y i ) g ( θ T x i ) ) δ ( θ T x i ) δ ( θ j ) \displaystyle \frac{\delta{J(\theta)}}{\delta(\theta_j)}=-\frac{1}{n} \sum_{i=1}^n{\left(y_i(1-g(\theta^Tx_i))-(1-y_i)g(\theta^Tx_i)\right)\frac{\delta(\theta^Tx_i)}{\delta(\theta_j)}} δ(θj)δJ(θ)=−n1i=1∑n(yi(1−g(θTxi))−(1−yi)g(θTxi))δ(θj)δ(θTxi)
计算 δ ( θ T x i ) δ ( θ j ) \displaystyle \frac{\delta(\theta^Tx_i)}{\delta(\theta_j)} δ(θj)δ(θTxi)后得(如不懂为什么变成这样,博主上一期博文中有讲解):
δ J ( θ ) δ ( θ j ) = − 1 n ∑ i = 1 n ( y i ( 1 − g ( θ T x i ) ) − ( 1 − y i ) g ( θ T x i ) ) x i j \displaystyle \frac{\delta{J(\theta)}}{\delta(\theta_j)}=-\frac{1}{n} \sum_{i=1}^n{\left(y_i(1-g(\theta^Tx_i))-(1-y_i)g(\theta^Tx_i)\right)x_{ij}} δ(θj)δJ(θ)=−n1i=1∑n(yi(1−g(θTxi))−(1−yi)g(θTxi))xij
将括号内的项展开,化简可得:
δ J ( θ ) δ ( θ j ) = − 1 n ∑ i = 1 n ( y i − g ( θ T x i ) ) x i j \displaystyle \frac{\delta{J(\theta)}}{\delta(\theta_j)}=-\frac{1}{n} \sum_{i=1}^n{\left(y_i-g(\theta^Tx_i)\right)x_{ij}} δ(θj)δJ(θ)=−n1i=1∑n(yi−g(θTxi))xij
把最前面的负号提到括号中来:
δ J ( θ ) δ ( θ j ) = 1 n ∑ i = 1 n ( h θ ( x i ) − y i ) x i j \displaystyle \frac{\delta{J(\theta)}}{\delta(\theta_j)}=\frac{1}{n} \sum_{i=1}^n{\left(h_\theta(x_i)-y_i\right)x_{ij}} δ(θj)δJ(θ)=n1i=1∑n(hθ(xi)−yi)xij
现在求导算已经完成了,下面将它带入梯度下降的公式可得:
θ j = θ j − 1 − α 1 n ∑ i = 1 n ( h θ ( x i ) − y i ) x i j \theta_j=\theta_{j-1}-\alpha\frac{1}{n} \sum_{i=1}^n{\left(h_\theta(x_i)-y_i\right)x_{ij}} θj=θj−1−αn1i=1∑n(hθ(xi)−yi)xij
到这里原理推导就完成了,下面看如何使用代码实现
三、算法实现
- 定义一个用于训练模型的类(具体做法都写在注释中了)
class LogisticRegression:
class Model:
"""
desc:训练出的模型
"""
def __init__(self,theta):
"""
desc:根据传入的 θ 构建模型
"""
self.theta = theta
def predict(self,x_test):
"""
desc:根据传入的特征,利用模型预测数据
"""
t = np.dot(x_test, self.theta)
# 得出类别为 1 的概率
result = LogisticRegression.sigmoid(t)
# 将所有数据取整 p > 0.5 return: 1 , p <= 0.5 return: 0
return np.round(result)
def __init__(self,alpha,theta,valve,batch_n=-1,max_iter=10**3):
"""
:param: alpha: 学习率,也称梯度下降中每一步的步长
:param: theta: 初始化的 θ 向量
:param: valve: 阀值,训练过程中,如梯度值的绝对值小于阀值就会跳出训练
:param: batch_n: 取一个整数表示微梯度下降中采用的样本数量,-1表示每次迭代采用全部数据
:param: max_iter: 最大的迭代次数,超过时自动跳出训练
"""
self.alpha = alpha
self.theta = theta
self.valve = valve
self.batch_n = batch_n
self.max_iter = max_iter
def fit(self,x_data,y_data):
"""
:param x_data: 特征值
:param y_data: 标签值
"""
iter_cnt = 0
data_len = x_data.shape[0]
# 验证样参数是否满足要求,并使其满足要求
self.batch_n = data_len if self.batch_n <= 0 or self.batch_n > data_len else self.batch_n
# 开始迭代
while self.__gradient_func(x_data,y_data) and iter_cnt < self.max_iter:
iter_cnt += 1
return self.Model(self.theta)
def __gradient_func(self,x_data,y_data):
"""
:param x_data: 特征值
:param y_data: 标签值
"""
gradient_vector = np.zeros(self.theta.size)
data_len = x_data.shape[0]
fetature_len = self.theta.shape[0]
# 遍历特征维度
for t in range(fetature_len):
j_ = 0
# 遍历样本数据
for i in range(0,data_len,round(data_len/self.batch_n)):
# 计算θx_1 + θx_2 + ... + θx_n 也就是公式中的(θ^TX)
t1 = np.dot(x_data[i], self.theta)
# 计算预测值 h_θ(x_i)
h_theta = LogisticRegression.sigmoid(t1)
# 结果累加起来 (h_θ(x_i) - y_i)x_ij
j_ += (h_theta-y_data[i])*x_data[i][t]
# 除以处理的样本数量,也就是取均值
j_ /= self.batch_n
# 修改梯度下降方向向量中对应的值
gradient_vector[t] = j_
# 更新全局 θ 的值,也就是朝着下山的方向走一步
self.theta = self.theta - self.alpha*gradient_vector
# 输出是否梯度是否达到阀值
return np.abs(gradient_vector.sum()) >= self.valve
@staticmethod
def sigmoid(x):
t = 1 + np.exp(-x)
result = np.divide(1,t)
return result
- 准备数据 (这里使用sklearn中自带的鸢尾花数据集)
from sklearn.datasets import load_iris
iris_data = np.column_stack(load_iris(return_X_y=True))
# 这里我们实现的只是二分类算法,左右只需要类别0和类别1两种即可
iris_data = iris_data[iris_data[:,-1]<2]
# 将数据打乱
np.random.shuffle(iris_data)
# 将数据分成两份
train_data,test_data= np.split(iris_data,2,axis=0)
# 训练数据
train_x = train_data[:,:-1]
train_y = train_data[:,-1]
# 测试数据
test_x = test_data[:,:-1]
test_y = test_data[:,-1]
- 训练模型
l = LogisticRegression(0.04,np.array([1]*train_x.shape[1]),0.0003,batch_n=20,max_iter=1000)
m = l.fit(train_x,train_y)
- 利用测试数据预测结果
m.predict(test_x)
后言:
如果文章对你有帮助不妨动动小手点个赞再走呗 !(*^__^*)!
文章中有什么问题也欢迎指出哟,谢谢!