Pandas高阶篇七(读取文件数据)
Pandas中的数据加载、存储与解析
1.读取csv文件
导入模块
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
from numpy import nan as NA
import sys用read_csv读取csv文件
pd.read_csv("data/ex1.csv")
打印结果:

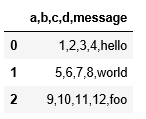
用read_table读取csv文件
pd.read_table("data/ex1.csv")打印结果:
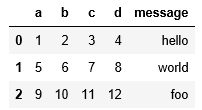
用read_table读取csv文件,指定分隔符
pd.read_table("data/ex1.csv",sep=",")打印结果:
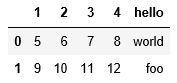
#读取的csv文件没有表头时,默认会把第一行数据分配为表头
pd.read_csv("data/ex2.csv")打印结果:
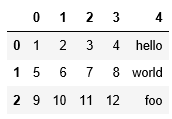
#读取的csv文件没有表头时,默认会分配表头索引
pd.read_csv("data/ex2.csv",header=None)打印结果:
#手动指定标题数据
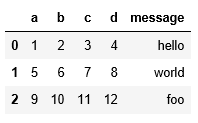
pd.read_csv("data/ex2.csv",names=["a","b","c","d","message"])打印结果:
#为加载的数据指定行索引,用某一列的数据作为行索引
pd.read_csv("data/ex2.csv",names=["a","b","c","d","message"],index_col="message")打印结果:

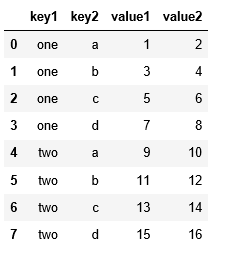
pd.read_csv("data/csv_mindex.csv")打印结果:
#将读取的数据进行层次化索引
pd.read_csv("data/csv_mindex.csv",index_col=["key1","key2"])打印结果:

#将读取的数据进行层次化索引
pd.read_csv("data/csv_mindex.csv",index_col=["key2","key1"])打印结果:

2.读取txt文件
#读取文本文件
open("data/ex3.txt")
list(open("data/ex3.txt"))
#打印结果:
[' A B C\n',
'aaa -0.264438 -1.026059 -0.619500\n',
'bbb 0.927272 0.302904 -0.032399\n',
'ccc -0.264273 -0.386314 -0.217601\n',
'ddd -0.871858 -0.348382 1.100491\n']
pd.read_table("data/ex3.txt",sep="\s+") #多个非空字符
打印结果:
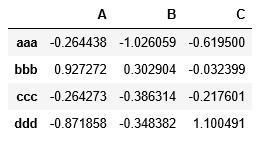
#通过skiprows参数指定跳过行索引
pd.read_csv("data/ex4.csv",skiprows=[0,2,3])打印结果:

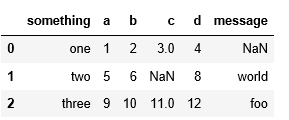
#加载存在NA的数据文件,na_values将空值转换为“NUL”。
pd.read_csv("data/ex5.csv",na_values=['NULL'])打印结果:
sentinels = {"message":["foo","NA"],"something":["two"]}
pd.read_csv("data/ex5.csv",na_values=sentinels) #把sentinels里指定的值替换为NaN打印结果:

3.写入csv文件
#用pandas将数据写入到csv文件中
df = DataFrame(np.random.randn(4,3),columns=["a","b","c"],index=["one","two","three","four"])
df打印结果:

df.to_csv("data/mydata1.csv")
#将数据直接输出到控制台
df.to_csv(sys.stdout,sep="|")
#打印结果:
|a|b|c
one|0.21522295805912317|0.8563225518233668|0.042847270561624705
two|1.1913785656962268|-0.08198281210776473|-0.6992421650032926
three|-0.06422094382860605|-1.0330910597067728|0.7897464201161191
four|-1.38860351562487|-1.1094144133483024|-0.001512810105137558
#将数据写入到csv文件,指定分隔符
df.to_csv("data/mydata2.csv",sep="|")
data = pd.read_csv("data/ex5.csv")
data
打印结果:
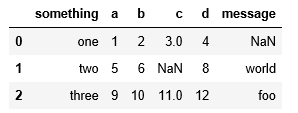
#为数据集中的NaN值做标记
data.to_csv(sys.stdout,na_rep="NULL")
#打印结果:
,something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo
#pandas只写入数据,不写入行和列的索引
data.to_csv(sys.stdout,index=False,header=False)
#打印结果:
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
#通过columns指定需要写入到文件中的列
data.to_csv(sys.stdout,index=False,columns=['a','b','c'])
#打印结果:
a,b,c
1,2,3.0
5,6,
9,10,11.0