Java并发系列之Java内存模型
前言
文本已收录至我的GitHub仓库,欢迎Star:https://github.com/bin392328206/six-finger
种一棵树最好的时间是十年前,其次是现在
我知道很多人不玩qq了,但是怀旧一下,欢迎加入六脉神剑Java菜鸟学习群,群聊号码:549684836 鼓励大家在技术的路上写博客
絮叨
昨天把一些底层原理的东西讲了一下,并且昨天也简单的提了一下Java内存模型,今天就让我们好好的啃一下它把,下面是前面的章节链接:
????史上最全的Java并发系列之并发编程的挑战
????史上最全的Java并发系列之Java并发机制的底层实现原理
内存模型基础
并发编程的两个关键问题
线程之间如何通信?命令式编程中线程的通信机制主要是以下两种:
共享内存 的并发模型:通过 读写内存中的公共状态 来进行隐式通信。
消息传递 的并发模型:没有公共状态,只能 通过发送消息来显示的进行通信。
线程之间如何同步?同步是指 程序中用于控制不同线程间操作发生相对顺序 的机制。
共享内存 的并发模型:同步时显示进行的。我们必须显示指定某段代码需要在线程直线互斥执行。
消息传递 的并发模型:由于消息发送必须在消息接收之前,因此同步时隐式的。
Java并发 采用的是 共享内存模型,Java线程之前的通信总是隐式进行的。
Java内存模型的抽象结构
在Java中,所有 实例域、静态域 和 数组元素 都储存在堆内存中,堆内存在线程之前共享。本文用 共享变量 统一描述 实例域、静态域 和 数组元素 。
局部变量 、方法定义参数、异常处理器参数 不会在内存之间共享,他们不会有内存可见性问题,也不受内存模型影响。
Java线程通信由Java内存模型(简称 JMM)控制,JMM 决定一个线程对共享变量的写入何时对另一个线程可见。从抽象角度看,JMM定义了 线程 和 主内存 之间的抽象关系:线程之间的共享变量储存在主内存中,每个线程都有一个私有的本地内存,本地内存储存了 该线程 以读写共享变量的副本。
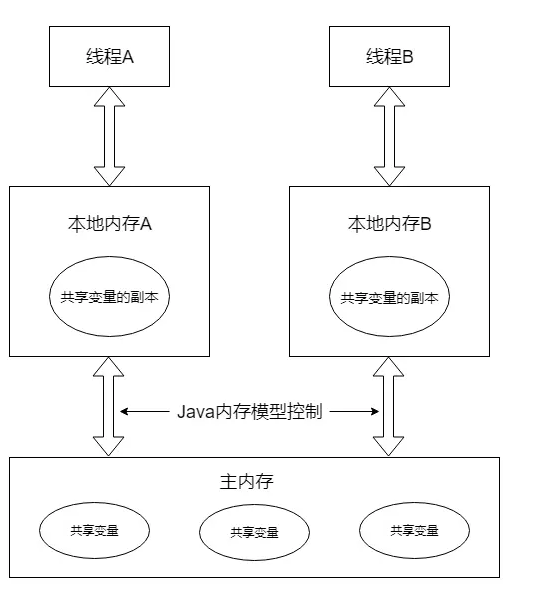 从上图来看,线程A和线程B需要通信的话,需要经历以下步骤:
从上图来看,线程A和线程B需要通信的话,需要经历以下步骤:
线程A 把 本地内存A 中的 共享变量副本 刷新到 主内存 中。
线程B 去读取 主内存 中 线程A 刷新过的 共享变量。
从整体来看,这两个步骤实质上是线程A向线程B发送消息,而通信必须经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来提供内存可见性的保证。
从源代码到指令序列的重排序
执行程序的时候,为了提高性能,编译器 和 处理器 常常会对指令做 重排序。主要有以下三类:
编译器优化的重排序 :编译器在 不改变单线程程序语义 的前提下,可以重新安排语句的执行顺序。
指令级并行的重排序 : 现代处理器采用 并行技术来将多条指令重叠执行,如果不存在数据依赖性,处理器可以改变对应机器指令的执行顺序。
内存系统的重排序 : 由于处理使用缓存和读写缓冲区,这使得加载和存储操作看上去可能乱序执行。
以下描述了源代码到最终执行的指令序列的示意图:
 上图中的 1 属于 编译器重排序,2 和 3 属于 处理器重排序。这些重排序可能会导致多线程程序出现内存可见性问题。
上图中的 1 属于 编译器重排序,2 和 3 属于 处理器重排序。这些重排序可能会导致多线程程序出现内存可见性问题。
对于编译器重排序, JMM的编译器重排序规则 会禁止特定类型的编译器重排序。对于处理器重排序,JMM的处理器重排序规则 会要求编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序。
什么意思呢,给大家解释一下,就是我们有很多关键字的语意可以禁止重排序
内存屏障
由于现代的操作系统都是多处理器.而每一个处理器都有自己的缓存,并且这些缓存并不是实时都与内存发生信息交换.这样就可能出现一个cpu上的缓存数据与另一个cpu上的缓存数据不一致的问题.而这样在多线程开发中,就有可能导致出现一些异常行为. 而操作系统底层为了这些问题,提供了一些内存屏障用以解决这样的问题.目前有4种屏障.
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
java中对内存屏障的使用在一般的代码中不太容易见到.常见的有两种.
通过 Synchronized关键字包住的代码区域,当线程进入到该区域读取变量信息时,保证读到的是最新的值.这是因为在同步区内对变量的写入操作,在离开同步区时就将当前线程内的数据刷新到内存中,而对数据的读取也不能从缓存读取,只能从内存中读取,保证了数据的读有效性.这就是插入了StoreStore屏障
使用了volatile修饰变量,则对变量的写操作,会插入StoreLoad屏障. 其余的操作,则需要通过Unsafe这个类来执行.
happens-before原则介绍
从 JDK5 开始,Java使用新的 JSR-133 内存模型。JSR-133 使用 happens-before 的概念来阐述操作之间的内存可见性。在 JMM 中,如果一个操作执行的结果需要对另一个操作可见,则这两个操作必须要存在happen-before关系 。两个操作之间具有happens-before关系,并不意味着前一个操作必须妖在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前 加深理解
如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前(对程序员来说)
如果两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序是允许的(对编译器和处理器来说)
总结来说,就是这样的一规则,它的规则约束,可以得到下面的结论
一个线程中的每个操作happens-before于该线程中的任意后续操作
对一个锁的解锁,happens-before于随后对这个锁的加锁
对一个volatile域的写,happens-before于任意后续对这个volatile域的读
如果A hapens-before B,且B happens-before C, 那么A happens-before C
如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before 于线程B中的任意操作
如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before 于线程A从ThreadB.join()操作成功返回
对线程interrup()方法的调用, happens-before 于被中断线程的代码检测到中断事件的发生
一个对象的初始化完成(构造函数执行结束)happens-before finalize()方法的开始
happens-before 是 JMM 最核心的概念。
重排序规则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。
volatile的内存语义
理解volatile特性的一个好方法是把对volatile变量的单个读/写,看成是 使用同一个锁 对这些单个读/写操作做了同步。
volatile变量具有下列特性:
可见性:总是能看到(任意线程)对这个volatile变量最后的写入。
原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
volatile写的内存语义:当写一个volatile变量时,JMM 会把该线程对应的本地内存中的共享变量值刷新到主内存。
volatile读的内存语义:当读一个volatile变量时,JMM 会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
它的缺点就是它只能对单个volatile变量的读写具有原子性,二锁是互斥行为,可以确保一个代码区域的执行原子性
锁的内存语义
锁是Java并发编程中最重要的同步机制。锁除了让临界区互斥执行外,还可以让释放锁的线程向获取同一个锁的线程发送消息。
当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中。和 volatile 写 类似。
当线程获取锁时,JMM会把该线程对应的本地内存置为无效。和 volatile 读 类似。
锁释放和锁获取的内存语义总结:
线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出了(线程A对共享变量所做修改的)消息。
线程B获取一个锁,实质上是线程B接收了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息。
线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发送消息。
final域的内存语义
与前面介绍的锁和volatile相比,对final域的读和写更像是普通的变量访问。
对于final域,编译器 和 处理器 要遵守两个 重排序规则。
在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
反正我看得很蒙,不知道啥意思,读者有懂的,可以下面评论,
双重检查锁定与延迟初始化
双重检查锁定 示例代码:
private static Instance instance; //1
public static Instance getInstance() { //2
if (instance == null) { //3
synchronized (Instance.class) { //4
if (instance == null) { //5
instance = new Instance() //6
}
}
}
return instance;
}
存在的问题:在线程执行到第3行if (instance == null),代码读取到instance不为null时,instance引用的对象有可能还没有完成初始化。
基于volatile的解决方案 只需要给变量 instance 添加 volatile 修饰符。
private volatile static Instance instance;
public static Instance getInstance() {
if (instance == null) {
synchronized (Instance.class) {
if (instance == null) {
instance = new Instance();
}
}
}
return instance;
}
为什么可以呢?因为这个对象的修改是对其他线程可见的,所以其他线程的修改肯定是会失败的,等下次去更新的时候,发现已经有了,就直接去拿有的对象了
基于类初始化的解决方案
public static class InstanceFactory {
public static Instance getInstance() {
// 这里将导致InstanceHolder类被初始化
return InstanceHolder.instance;
}
private static class InstanceHolder {
public static Instance instance = new Instance();
}
}
这个就是我们常写的单列模式
各种内存模型之间的关系
JMM 是一个语言级的内存模型。
处理器内存模型 是硬件级的内存模型。
顺序一致性内存模型 是一个理论参考模型。
JMM的内存可见性保证
按程序类型,Java程序的内存可见性保证可以分为下列3类:
单线程程序:不会出现内存可见性问题。JMM为它们提供了最小安全性保障:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0、null、false)。
正确同步的多线程程序:程序的执行将具有顺序一致性。这是JMM关注的重点,JMM通过限制编译器和处理器的重排序来为程序员提供内存可见性保证。
未同步/未正确同步的多线程程序:JMM为它们提供了最小安全性保障:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0、null、false)。
结尾
第三章,介绍了JMM的内存模型,还有就是各种关键字的内存语义,也是讲理论的多,不过大家认真看,把这些抽象的概念具体化,那么等你下次去用的时候,或者面试的时候,就不会那么难了。
因为博主也是一个开发萌新 我也是一边学一边写 我有个目标就是一周 二到三篇 希望能坚持个一年吧 希望各位大佬多提意见,让我多学习,一起进步。
日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是真粉。
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见
六脉神剑 | 文 【原创】如果本篇博客有任何错误,请批评指教,不胜感激 !