L:python的Pandas模块:行、列的插入和删除,索引整理,重复值处理,排序,排名,数据框连接,数据分段,多级索引
数据整理
Pandas提供的数据整理方法
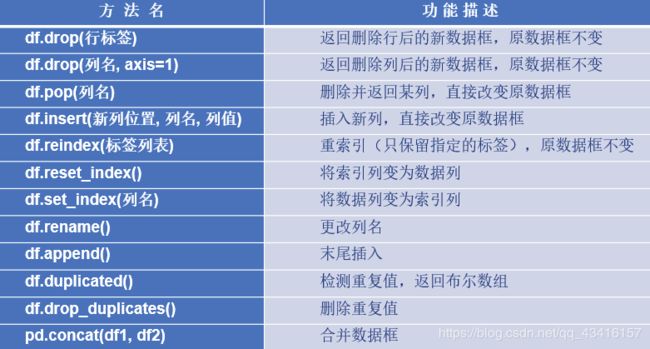
行、列的插入和删除
df = DataFrame({'姓名':['a','b'], '学号':['A1','A2'], '成绩1':[98,90], '成绩2':[87,80]})

行的插入/删除
# 字典参数, 在末尾插入新行,注意ignore_index=True
df = df.append({'姓名':'d','学号':'A4','成绩1':89,'成绩2':78}, ignore_index=True)
DataFrame的很多命令并不直接改变原数据框,而是返回新数据框,这和列表的处理方式不同。
要直接修改原数据框,可将命令写为df=df.append() 的形式。
删除行使用drop()方法。
df.drop(2, inplace=True) # 按索引删除第2行, inplace= True表示就地修改原数据框
列的插入/删除
创建新列最简单的方法是直接给一个新列赋值,新列默认插在最后。
要注意提供的数据个数应等于数据框的行数。
df['性别'] = ['M', 'F'] # 增加"性别"列,给新列赋值即可插入列
# 在第4列插入平均成绩,插入值由成绩1和成绩2计算得到
df.insert(4, '平均成绩', (df.成绩1 + df.成绩2) / 2 )
Out:
姓名 学号 成绩1 成绩2 平均成绩 性别
0 a A1 98 87 92.5 M
1 b A2 90 80 85.0 F
删除列时,可使用如下三种方法。 注意axis=1和inplace参数
df.drop('平均成绩', axis = 1, inplace=True)
df.pop('成绩1')
del df['成绩2']
索引整理
reindex()重建索引
通过reindex()方法重建索引,可实现行列的取舍。重建时保留指定标签的数据,抛弃未指定的标签。
df = pd.read_csv("mobile.csv", encoding='cp936', index_col=0)
df2 = df.reindex(['一月', '二月', '四月'])
上例中新数据框df2只保留了一月和二月的数据,丢弃了三月的数据,
同时建立了一个'四月'新标签,新标签对应的值默认为NaN。
df.reindex(['apple', 'huawei','mi'], axis=1) # axis=1在列上重建索引


rename()重命名
如果已有的列名或行索引不太合适,可使用rename()方法进行调整。
df.rename(columns={'apple':'Apple', 'huawei':'HW'}) # 更改列名
Out:
Apple HW oppo
一月 1100 1250 800
二月 1050 1300 850
三月 1200 1328 750
df.rename(index={'一月':'m1', '二月':'m2', '三月':'m3'}) # 更改索引
Out:
apple huawei oppo
m1 1100 1250 800
m2 1050 1300 850
m3 1200 1328 750
set_index()重新设定索引列
如果想用另一列做索引列,可用set_index()方法变更。
df = DataFrame({'姓名':['a','b'], '学号':['A1','A2'], '成绩1':[98,90], '成绩2':[87,80]})
df3 = df.set_index('学号') # 返回的新数据框将学号列设为索引

df3.reset_index(inplace=True) # 先将原索引列学号恢复为数据列
df3.set_index('姓名', inplace=True) # 再将姓名列设为索引列

重复值处理
数据中含有重复值时,使用下列方法处理。
s = Series(list('abac'))
s.duplicated() # 检测重复值,返回布尔数组,重复值处显示True
s.drop_duplicates() # 删除重复值

df = DataFrame({'c1': ['a', 'a', 'b'], 'c2': ['a', 'b', 'b'], 'c3': ['a', 'b', 'x']}) df.drop_duplicates('c1') # c1列上删除重复值

排序和排名
排序
排序可按索引或数据值。按索引排序使用sort_index()方法,按数据值排序使用sort_values()方法。排序后返回新的有序集,不改变原数据集。
s = Series([2, 5, 1], index=['d', 'a', 'b'])
s.sort_index() # 按索引'a b d'排序,返回新对象,并不改变原对象
s.sort_values() # 按数据值1 2 5排序
s.sort_index(ascending=False) # 按索引逆序排
对数据框排序时,可以设定axis参数以指定按行或按列排序。
np.random.seed(7)
arr = np.array(np.random.randint(1, 100, size=9)).reshape(3, 3)
df = DataFrame(arr.reshape(3, 3), columns=['x','y','z'], index=['a','b','c'])
df.sort_index(axis=1, ascending=False) # 按列名索引降序z y x排列
df.sort_values(by='y') # 按y列的数值排序
df.sort_values(by=['y', 'z']) # 先参照y列,再z列排序
注:无论升序降序,缺失值都排在末尾

排名
排名rank()和排序类似,但会自动生成一个排名号。
s = Series([3, 5, 8, 5], index=list('abcd'))
s.rank() # 排名,默认按数据值升序排名
s.rank(ascending=False) # 降序
s.rank(method='first') # 指定名次号的生成方法为first
索引a的数值最小,排第1。索引b,d的数值相同,
应排在第2、3名,取平均名次(2+3)/2=2.5,
索引c排在第4。method='first',表示排名相同时不计算平均名次,
而是以数据出现的先后顺序排列。

数据框连接
Pandas提供了merge()方法用于连接不同数据框的行,类似于数据库的连接运算( select sno, name from tb1, tb2 where tb1.sno=tb2.sno )。
df1 = DataFrame({'color':['r', 'b', 'w', 'w'], 'c1':range(4)})
df2 = DataFrame({'color':['b', 'w', 'b'], 'c2':range(2, 5)})
pd.merge(df1, df2) # 或写为 pd.merge(df1, df2, on='color')
df1和df2有同名列color,pd.merge()自动将同名列作为连接键,
横向连接两个数据框的color值相等的行。连接时丢弃原数据框的索引。

两个数据框列名不同时,用left_on和right_on参数分别指定。
下例指定c1, c2列为键,表示当df1表的c1列值等于df2表的c2列值时满足连接条件。
pd.merge(df1, df2, left_on='c1', right_on='c2')
因为两个表的color列名相同,所以自动加上后缀_x, _y区分。
pd.merge默认做inner内连接,还可指定left /right/outer 等连接方式,这些连接方式与数据库中的连接规则是类似的。
df2 = DataFrame({'color':['b', 'w', 'g'], 'c2':range(2, 5)})
pd.merge(df1, df2, how='left') # 包含左表所有的行
pd.merge(df1, df2, how='right') # 包含右表所有的行
pd.merge(df1, df2, how='outer') # 包含两表所有的行

与连接有关的另一个方法是pd.concat(),它合并两个数据框。
np.random.seed(7)
df1 = DataFrame(np.random.rand(4).reshape(2, 2), columns=['c1', 'c2'])
df2 = DataFrame(np.random.rand(4).reshape(2, 2), columns=['c1', 'c2'])
pd.concat([df1, df2], ignore_index=True) # 默认沿纵向合并,行数增加
pd.concat([df1, df2], axis=1) # axis=1沿横向合并,列数增加

数据分段
数据分段是将数据按指定的区间归类,以统计每个区间的数据个数。例如将成绩分为优、良、中、不及格区间段。数据分段的方法是pd.cut(),分段前要自定义数据区间段,并设置对应的标识文字。
np.random.seed(7)
score = np.random.randint(30, 100, size=100) # 生成100个随机整数
bins = [0, 59, 70, 85, 100] # 定义区间段
labels = ['不及格', '中', '良', '优'] # 设置各段的标识文字
scut = pd.cut(score, bins, labels=labels) # 将score按bins分段
s = pd.value_counts(scut) # 统计各类别的数据个数
# 划分区间为 (0,59] < (59, 70] < (70,85] <(85,100]

多级索引
Pandas支持一级索引,也支持多级索引(MultiIndex)。
多级索引可以更好地表达数据之间的联系。假定A、B两类产品都有红、绿两种颜色。
x = DataFrame(np.arange(2, 10).reshape(4, 2), index=[list('AABB'), list('rgrg')], columns=['一月','二月']) # 语法1
mindex = pd.Index([('A', 'r'), ('A', 'g'), ('B', 'r'), ('B', 'g')], name=['product', 'color'])
# 创建多级索引数据框 语法2
df = DataFrame(np.arange(2, 10).reshape(4, 2), index=mindex, columns=['一月','二月'])
df有两级索引(0级和1级),索引分别命名为product和color。
df.loc['B'] # 查看B类产品
df.loc[('B', 'r')] # 查看B类中的红色r产品
df.loc[(slice(None), 'r'), :] # 查看所有的红色r产品
df.loc['A'].sum() # A 类每个月数量和
df.loc['A'].sum().sum() # 所有A类数量和
df.loc[(slice(None), 'r'), :].sum().sum() # r 类数量和
df.groupby(level='product').sum()
df.groupby(level='product').sum().sum(axis=1)

多级索引的数据框常使用stack()和unstack()命令进行转换。
df2=df.unstack() # 默认将内层的1级行索引转为列索引
df2.columns
df3=df.stack() # 变为三级(0,1,2)索引了
df3.groupby(level=2).sum()
