读书笔记 --- 数据结构与算法分析C语言描述 --- 12.22 --- Chapter4 树 page70 - 76
4.2 二叉树
二叉树每个结点至多有两个儿子,即可以拥有(0,1,2)个儿子。由此二叉树的平均深度要比N小得多,为O(sqrt(N)),再对于特殊类型的二叉树:二叉查找树(Binary Search Tree)深度平均值为O(log N)。而特殊情况就是二叉树是一棵斜树,为一个特殊的链表,深度可以达到N - 1。
4.2.1 实现
结点的儿子可以用指针指向他们,类似于一个双向链表。
struct DualLinkedList {
elemType elem;
DualLinkedList *pre;
DualLinkedList *next;
}
二叉树的结构,之前已经附过一次代码:
struct TreeNode {
elemType elem;
TreeNode *right;
TreeNode *left;
}
记一个结论:具有N个结点的每一棵二叉树都将需要N + 1个NULL指针。
下面附证明:

下面来探究一下二叉树的具体应用。
4.2.2 表达式树
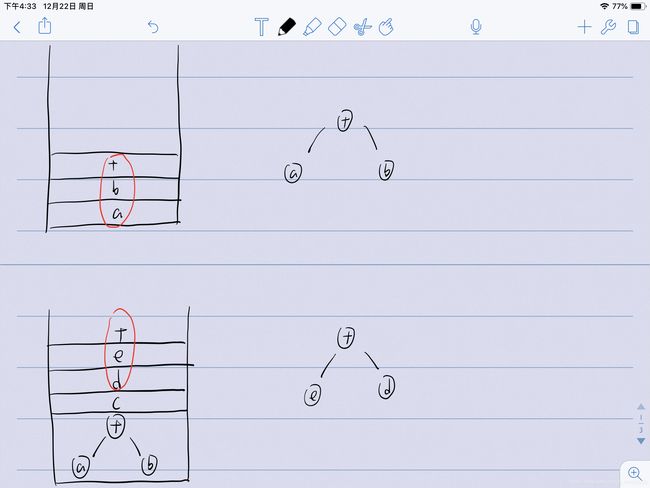
一棵树的叶结点均为操作数(operand),而其余结点均为操作符(operator)。鉴于这里本例子中给出的表达式 (a + (b * c)) + (((d * e) + f ) * g)所有的操作均为二元,所以这棵特定的树正好是二叉树。因此结点含有多于两个儿子或只有一个儿子的情况也是存在的,例如一目运算符(unary minus operator)。

我们日常司空见惯的算术式实质上就是一个中缀表达式(infix expression),这个表达式即是由对表达式树进行中序遍历(inorder traversal)得出的。而我们所得出的前序表达式和后序表达式就不必我多说了吧,对应的就是表达式树前序遍历和后序遍历对应的结果。
前序遍历:+ + a * b c * + * d e f g
后序遍历: a b c * + d e * f + g * + (熟悉嘛?栈里讨论过的逆波兰表达式)
构造一棵表达式树
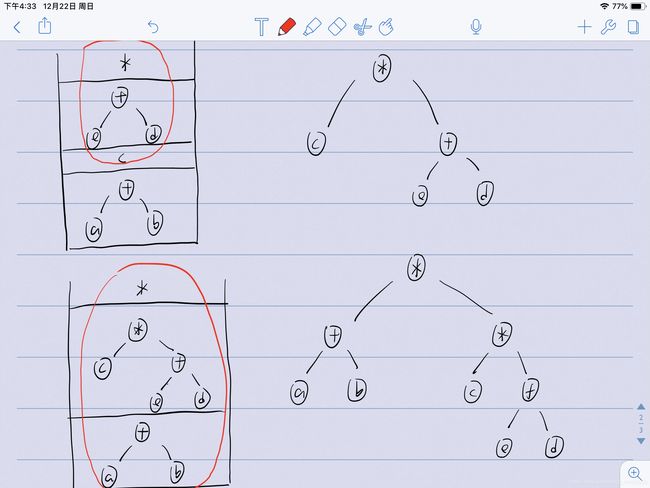
构造一棵表达式树与栈章节所讲的中缀转后缀表达式以及后缀转中缀表达式非常的相似,我们这里的构造也需要借助到栈,下面
是构造过程,首先是a,b两个操作数(operand)入栈,遇到了操作符(operator),进行第一次整合。这里我一个比较新颖的理解是:将这棵构造好的树(constructed tree)放回栈中,对表达式中的operand再进行入栈的操作,遇到operator +进行第二次整合,取的是e,d。同时也将这棵constructed tree放回栈中,此时*入栈,将operand c与刚才第二次整合的树进行第三次整合,又得到一棵constructed tree,最后一个operator *入栈,将两棵constructed tree进行最后一次整合得到最后的结果。不难发现按我这个整合的优先顺序是:
operand + operand (1)
operand + constructed tree (2)
constructed tree + constructed tree(3)
按照之前后缀表达式得出结果的方法,即遇到操作数(operand)就入栈,遇到操作符(operator)便对最上方的两个操作数进行x op y的操作按照这样的优先级对所有元素进行整合。这里也是一样,只是将上方的operand/constructed tree进行了整合,有什么就整合什么。
4.3 查找树ADT — 二叉查找树(Binary Search Tree)
首先二叉查找树的前提是要是一棵二叉树,对于树中所有结点X,他的左子树所有关键字值需要小于X关键字值,右子树所有关键字值需要大于X关键字值。这意味着该树所有的元素可以用某种统一的方式排序。
4.3.1 makeEmpty
首先给出二叉查找树的定义,和二叉树是一模一样的,没有任何区别,只是我们如何去对内部结构进行调整。最开始的这个makeEmpty可以理解为一个初始化操作。
struct BinarySearchTreeNode {
elemType elem;
TreeNode *right;
TreeNode *left;
}
BinarySearchTreeNode* makeEmpty(BinarySearchTreeNode *T) {
if ( T != nullptr ) {
// 我们在这里严格遵循了递归定义建立了一棵空树
makeEmpty(T->left);
makeEmpty(T->right);
free(T);
}
return nullptr;
}
4.3.2 find
找到BST中的目标元素
BinarySearchTreeNode* find(elem X, BinarySearchTreeNode *T) {
if ( T == nullptr )
return nullptr;
// 目标元素比我当前位置元素值还要小,应该继续往左找,因为我需要更小的
if ( X < T->elem )
return find(X, T->left);
// 目标元素比我当前位置元素值还要大,应该继续往右找,因为我需要更大的
else if ( X > T->elem )
return find(X, T->right);
// 匹配到目标元素,返回该结点
else
return T;
}
4.3.3 findMin & findMax
找到BST中的最大 & 最小的元素
书上给出的找最小元素使用了递归,而在找最大元素时使用了非递归。
而在BST中找到最小/最大的元素,找的就是左子树最左边的元素/右子树最右边的元素。
BinarySearchTreeNode* findMin(BinarySearchTreeNode *T) {
if ( T == nullptr )
return nullptr;
// 找到最左边的结点(注意并不是叶子结点)只需要判断T->left是否为空
else if ( T->left == nullptr )
return T;
else
return findMin(T->left);
}
BinarySearchTreeNode* findMax(BinarySearchTreeNode *T) {
// 非递归,迭代找最右边结点,不做过多解释了
if ( T != nullptr )
while ( T->right != nullptr )
T = T->right;
return T;
}
4.3.4 insert
思路就是利用find()进行查找,找到BST中有对应的元素则什么也不用做(或进行一次更新),否则就将元素插入到遍历路径的最后一点上。举个例子来讲吧,你要插入一个元素X,首先你要从根这个"分叉路口"开始走,比根小走左边,比根大走右边…重复这个过程,直到你不再有"分叉路口"可以选择。
BinarySearchTreeNode* insert(elem X, BinarySearchTreeNode *T){
if ( T == nullptr ) {
T = malloc(sizeof(BinarySearchTreeNode));
if ( T == nullptr )
fatalError("Out of Space");
else {
T->elem = X;
T->left = T->right = nullptr;
}
}
else if ( X < T->elem )
T->left = insert(X, T->left);
else if ( X > T->elem )
T->right = insert(X, T->right);
return T;
}
书上给的这段代码还是更侧重于递归的讲解。教材上给的先通过指针定位到search的上一个位置,再通过最后一次与这个位置的元素值的大小进行放在左边还是右边。我把教材上的代码也浓缩一下贴在这里。
bool insertBST(BiTree *T, int key) {
BiTree p, s;
// bool search()定义的就是假设元素并没有找到,就定位到最后的分叉路口的位置p
if ( !searchBST(*T, key, nullptr, &p) ) {
s = malloc(sizeof(BiTNode));
s->data = key;
s->lchild = s->rchild = nullptr;
// p为nullptr的原因是其值比根的值还要大,所以令p成为新的根
if ( !p )
*T = s;
else if ( key < p->data )
p->lchild = s;
else if ( key > p->data )
p->rchild = s;
return true;
}
else
return false;
}
这个新手应该也可以理解,理解难度比前一种递归小很多。