YOLOv4论文阅读笔记(一)
YOLOv4论文阅读笔记
- Introduction
- Related work
- Bag of freebies
- Bag of Specials
近日发表的YOLOv4无疑是2020年目前最轰动的重磅炸弹,由Alexey Bochkovskiy等人发表。Alexey曾在YOLO之父 Jeseph Redmon的团队参与过YOLO项目的维护,在Jeseph因为“无法忽视工作带来的负面影响”(确实磕盐使人头秃,CV大神也是人TvT)宣布退出之后,于2020年4月24日在arXiv上发表这篇:YOLOv4: Optimal Speed and Accuracy of Object Detection,本文末尾附上代码和论文,为速度慢的同学谋福利。
想学习YOLOv4的同学应该对前面三代都有一定的认识和了解吧,如果没有的话也没关系,并没有什么太复杂的数学公式什么的,看起来还是很轻松愉快,转入正题,让我们来逐步看看这篇神作都有什么宝藏吧。
Introduction
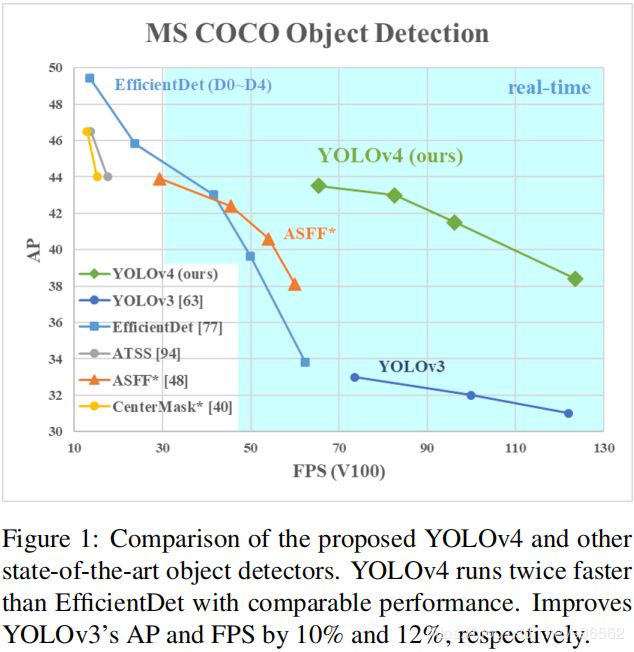
就如YOLOv3一样,这篇论文总结了近两年来常用的目标检测模型架构,及各种数据增强、训练trick等,还是非常全面的。作者也做了极其庞大数量的实验来证明YOLOv4无论在accuracy还是FPS方面都是王者,当然YOLO这种one-stage的mAP还是比不上two-stage的,尤其在cascade瀑布模型将单模型级联可以很大程度对推理结果进行refine之后,单论准确性还是two-stage占优,但是YOLO胜就胜在它快啊!毕竟在自动驾驶时FPS决定一切,总不能识别一帧一秒吧-。-而且考虑到目前很多检测模型需要庞大的GPU算力,不利于普遍性工程应用,作者一再强调YOLOv4只需要单GPU就能得到良好训练,不需要分布式多GPU训练,只需要一块GTX1080Ti或者RTX2080Ti就好啦(话说就这卡苦逼学生党也买不起啊…)。在摘要中提到了一些比较新的trick,如 Weighted-Residual-Connections (WRC),Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT) and Mish-activation,CIoU loss, Mosaic data augmentation等,通过结合一些实现了SOTA的结果:在COCO数据集上使用Tesla V100获得FPS 65的AP 43.5%,分别比YOLOv3提高了12%和10%,已经很强大了,我记得之前casade faster rcnn官方给出的也就百分之50多AP,如下图所示:
总结一下,论文的主要贡献点有三点:
- 构建了一个高效强大的目标检测模型,它可以让人们只使用一块1080Ti或者2080Ti GPU就能训练出一个超级快和准确的目标检测器。(对,作者用了超级——super!)
- 作者通过大量的训练实验证实了Bag-of-Freabies和Bag-of-Specials的影响,对于这两个是什么我们后面再讨论。
- 作者修改了一些SOTA的方法使他们更高效和适用于单GPU训练,包括CBN,PAN,SAM等。
Related work
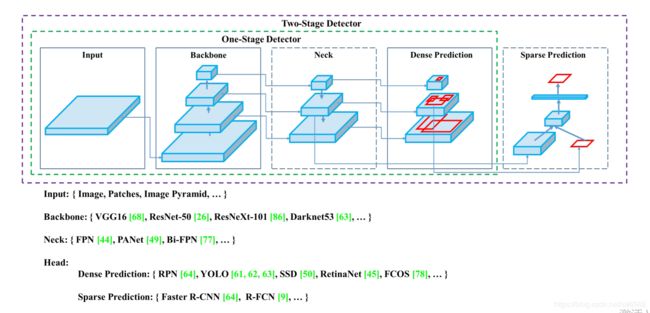
作者首先大体总结了目前最常用的目标检测模型的通用架构,最核心的是需要一个在ImageNet预训练的骨干网络(backbone) 和一个用来预测物体类别和边框的头部检测器(head),最常用的有:
Backbone:
GPU:VGG,ResNet-50,ResNext,DenseNet
CPU:SqueezeNet,MobileNet,ShuffleNet
而对于头部检测器,分为两种:
Two-stage:RCNN系列——fast RCNN,faster RCNN,R-FCN,Libra RCNN
One-stage:YOLO,SSD,RetinaNet
而近年来常常在骨干与头部之间插入一种脖颈结构:
Neck:Feature Pyramid Network (FPN) , Path Aggregation Network (PAN) , BiFPN(见focal loss篇), and NAS-FPN.
大致结构如下图:
这让我想起了一个很好用的github开源项目由open-mmlab开发的mmdetection,对于目前常用的目标检测模型进行模组式应用,所有的部分包括backbone、neck、head都是可选择的,将模型各部分放在一个config.py文件中,包含所有模型所需要的参数,训练方法,在线增强等,简直不要太好用。不过实际效果就不好说了,需要大量实验调参测试。
Bag of freebies
《Bag of Freebies for Training Object Detection Neural Networks》是19年的一篇综述性论文,总结了多种目标检测任务中可以有效提高检准确率的训练技巧,作者在这里提到了两个概念,光度失真(photometric distortions)和几何失真(geometric distortion)是我们常用的两种数据增强技巧,包括:
光度失真:亮度,对比度,色度,饱和度,噪声等
几何失真:随机尺度,裁剪,翻转,旋转等
而这些都是像素级(pixel-wise)的增强方法。但考虑到在很多自然图像的检测中大多存在遮挡现象,因此研究人员采用手动创造遮挡来增强模型的泛化能力,如:
※Random Erasing
论文链接:https://arxiv.xilesou.top/pdf/1708.04896.pdf
论文代码:https://github.com/zhunzhong07/Random-Erasing

※Cutout
论文链接:https://arxiv.xilesou.top/pdf/1708.04552.pdf
代码链接:https://github.com/Dingzixiang/cutout

这种方法就类似于在训练过程中的dropout,drop connection,drop block技巧,同样有着良好的抗过拟合能力,只不过是应用在了输入图像中。同理,将两幅或多幅图像按一定比例融合也可以达到这种目的,且不同类别目标之间具有更强相干性,增强模型学习能力:
※Mixup
论文链接:https://arxiv.org/pdf/1710.09412.pdf
代码链接:https://github.com/facebookresearch/mixup-cifar10

※Cutmix
论文链接:https://arxiv.org/abs/1905.04899?context=cs.CV
代码链接:https://github.com/clovaai/CutMix-PyTorch

Cutmix和mixup主要的区别就是cutmix是在一张图像上随机截取一个矩形区域替换为另一个图像,mixup是直接两幅图像按比例融合。
※OHEM(Online hard example mining)
论文链接:https://arxiv.org/pdf/1604.03540.pdf
代码链接:https://https://github.com/abhi2610/ohem
不过OHEM不适用于YOLO这种具有稠密预测的one-stage检测,多用于faster-rcnn这种two-stage方法。
※Focal Loss
论文链接:https://arxiv.org/abs/1708.02002
代码链接:https://github.com/unsky/focal-loss
![]()
focal loss通过在传统多类别交叉熵损失前添加权重上,平衡样本类别,调整hard和easy example,positive和negative样本对Loss影响的权重,该论文被评为17年最优秀硕士论文。
※标签平滑(Label smoothing)
在类别预测时我们的模型输出的是one-hot向量,预测类别的输出概率较大使其尽量趋向1,而其他的较小尽量趋向0,而我们只关心概率最大的类别,忽视了其他错误类别,有可能会导致在训练集上准确率很高但是在测试集上并不能保证较低的错误分类,因此就有了标签平滑,使标签概率不绝对为1或0,达到平衡的目的,方法如下:

标签平滑前:

标签平滑后:
Loss of BBox
转载自:https://zhuanlan.zhihu.com/p/104236411
传统的方法是使用MSE均方误差进行BBox计算,可以计算中心点或顶点,但MSE忽略了BBox各点间的关系,因此产生:
※IOULoss:
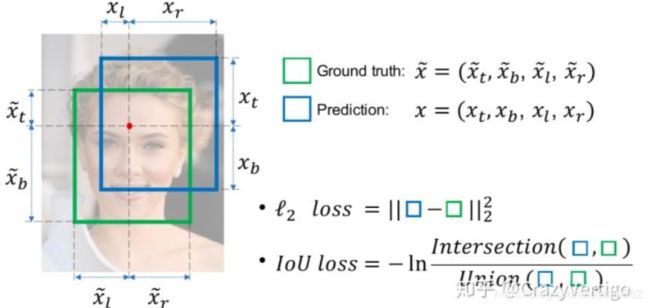

但是IOULoss 有2个缺点:
1.当预测框和目标框不相交时,IoU(A,B)=0时,不能反映A,B距离的远近,此时损失函数不可导,IoU Loss 无法优化两个框不相交的情况。
2.假设预测框和目标框的大小都确定,只要两个框的相交值是确定的,其IoU值是相同时,IoU值不能反映两个框是如何相交的。
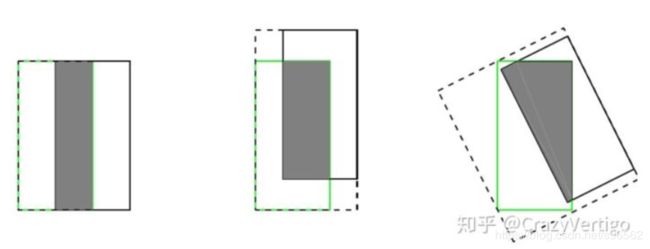
※GIOU Loss:
论文链接:https://arxiv.org/abs/1902.09630
代码链接:https://github.com/generalized-iou/g-darknet
计算方法:


GIOULoss存在不足:
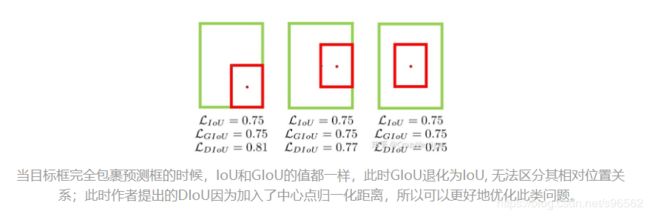
启发点:
基于IoU和GIoU存在的问题,作者提出了两个问题:
第一:直接最小化预测框与目标框之间的归一化距离是否可行,以达到更快的收敛速度。
第二:如何使回归在与目标框有重叠甚至包含时更准确、更快。
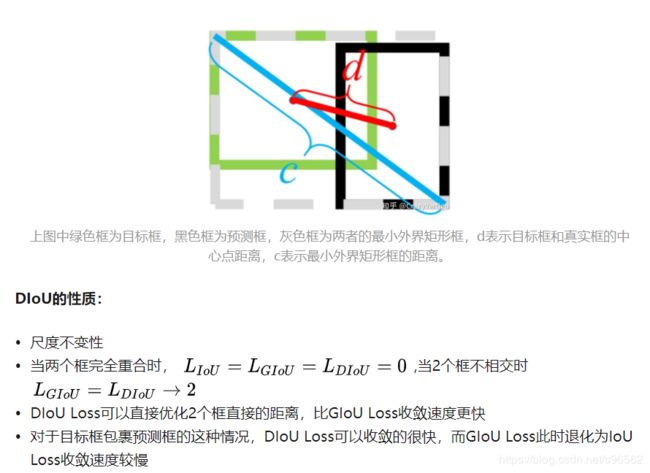
好的目标框回归损失应该考虑三个重要的几何因素:重叠面积,中心点距离,长宽比。基于问题一,作者提出了DIoU Loss,相对于GIoU Loss收敛速度更快,该Loss考虑了重叠面积和中心点距离,但没有考虑到长宽比;针对问题二,作者提出了CIoU Loss,其收敛的精度更高,以上三个因素都考虑到了。
※Distance-IoU Loss
论文链接:https://arxiv.org/pdf/1911.08287.pdf
代码链接:https://github.com/Zzh-tju/DIoU-darknet
计算方法:

※Complete-IoU Loss
CIoU的惩罚项是在DIoU的惩罚项基础上加了一个影响因子,这个因子把预测框长宽比拟合目标框的长宽比考虑进去。
论文链接:https://arxiv.org/pdf/1911.08287.pdf
代码链接:https://github.com/Zzh-tju/DIoU-darknet
计算方法:
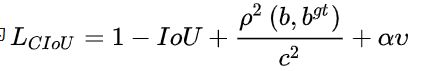
Bag of Specials
那些只增加少量推理代价就可以明显提升目标检测准确率的插件模组或者后处理方法我们称之为“Bag of specials”。大体上说,这些插件是为了在一个模型中用来增强一个确切的属性的,比如增强感受野(receptive field),增加注意力机制(attention mechanism),或是增强特征整合能力(featrue integration capabilitty),而后处理(post-processing)是一种筛选预测结果的方法。
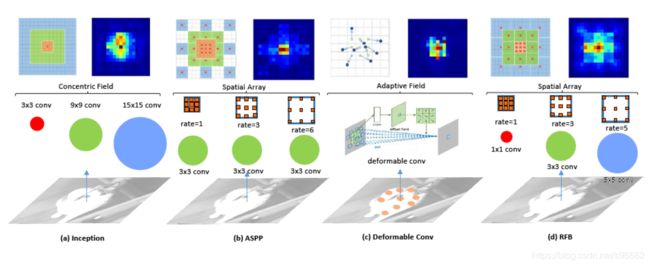
Receptive field:SPP,ASPP,RFB
※SPP(Spatial Pyramid Pooling)
转载自:https://blog.csdn.net/yzf0011/article/details/75212513
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小。然而通常的手法就是裁剪(crop)和拉伸(warp)。这样做总是不好的:图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像。而Kaiming He在这里提出了一个SPP(Spatial Pyramid Pooling)层能很好的解决这样的问题, 但SPP通常连接在最后一层卷基层。

论文链接:https://arxiv.org/abs/1406.4729
代码链接:https://github.com/yhenon/keras-spp
由Kaiming He提出的SPP模组输出一维特征向量,并不适用于全卷积(FCN)网络,因此在YOLOv3中,Redmon和Farhadi通过将核尺寸为kxk,k={1,5,9,13},步长为1的最大池化输出拼接有效提升感受野,增加了SPP模组的YOLOv3-608在MS COCO数据集中提升了2.7%的AP50。
※ASPP(Atrous Spatial Pyramid Pooling)
ASPP是在SPP的基础上使用空洞卷积进一步提高感受野,在Deeplab中被提出,在语义分割领域有着良好表现,使用的是3x3,m空洞比例为k,步长为1的卷积核。这里就不再赘述。
论文链接:https://arxiv.org/pdf/1606.00915.pdf
代码链接:https://github.com/DrSleep/tensorflow-deeplab-resnet
※RFB(Receptive Field Block)
不同于ASPP的是,RFB使用的是kxk,空洞比例为k,步长为1的卷积核。RFB仅仅花费了额外百分之7的推理时间在MS COCO数据集上增加了5.7%的AP50。
论文链接:https://arxiv.org/abs/1711.07767
代码链接:https://github.com/ruinmessi/RFBNet
注意力机制(Attention module)
注意力机制可分为channel-wise和poin-wise attention,最具代表性的是 Squeeze-and-Excitation (SE)和Spatial Attention Module (SAM)。
※Squeeze-and-Excitation (SE)
转载自:https://blog.csdn.net/u014380165/article/details/78006626
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中,作者采用SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
作者在文中将SENet block插入到现有的多种分类网络中,都取得了不错的效果。SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。当然,SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的。

论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
但是SE模组在GPU中常常增加10%的推理时间,所以更适用于移动设备中。
※Spatial Attention Module (SAM)
转载自https://blog.csdn.net/u013738531/article/details/82731257

论文链接:http://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
代码地址:https://github.com/luuuyi/CBAM.PyTorch
SAM只需要额外0.1%的计算,并不影响GPU的推理速度。
Feature integration
特征整合主要是通过skip-connection和hyper-column整合低级物理特征(physical feature)和高级语义特征(semantic feature)。自从FPN后有很多轻量级模组被提出。包括:SFAM,ASFF,BiFPN。
※Adaptively Spatial Feature Fusion(ASFF)

论文链接:https://arxiv.org/pdf/1911.09516.pdf
代码地址:https://github.com/ruinmessi/ASFF
※BiFPN
BiFPN发表于EfficientDet中,

论文链接:https://arxiv.org/abs/1911.09070
代码地址:https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
激活函数(Activation function)
参考:https://blog.csdn.net/clover_my/article/details/90693817
到此YOLOv4的前两部分已经阅读完,总的来说就是各种数据增强,检测方法,模组的总结,接下来我们将重点关注YOLOv4的模型结构及训练方法。
YOLOv4论文及代码:https://pan.baidu.com/s/1pmv8AxlKoXPHu1l0J5W8gg
提取码:5ly2