以太坊源码分析---go-ethereum之MPT(Merkle-Patricia Trie)
本文微信公众号 月牙寂道长 文章链接为:https://mp.weixin.qq.com/s/vljKF9lI6l_fKu0_Nn0U7g
本文图片可能不太清晰,看清晰版本的,可以看原文链接微信公众号链接。
MPT(Merkle-Patricia Trie)其实就是一个数据结构,在以太坊中用于存储用户账户的状态及其变更、交易信息、交易的收据信息。
要讲MPT,就要讲讲MPT是如何演变来的。
Trie
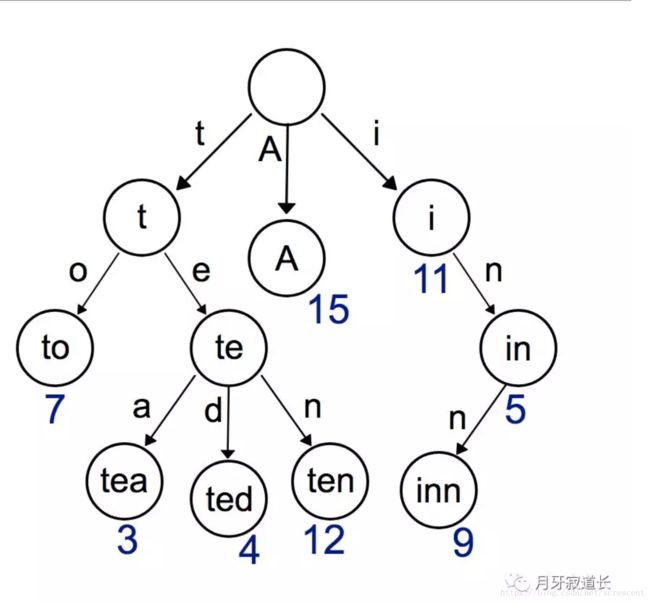
图片来自https://en.wikipedia.org/wiki/Trie
trie树,又称为字典树或者前缀树 (prefix tree)。这个数据结构,以前也有写过库,当然是用在自己的项目中。通过对字符的直接索引,减少字符串比较的动作,从而达到查询效率高。
但其也存在一些问题。
当有一个很长的字符串的时候,这个字符串又和其他字符串没有重叠的话,那那么在trie中,存储和遍历都需要很多的节点,并且会导致trie树不平衡。
Patricia Trie (Radix tree)

图片来自https://en.wikipedia.org/wiki/Radix_tree
Patricia Trie,又被称为 Radix Tree 或紧凑前缀树 (compact prefix tree)。是在trie上优化过来的。主要的优化是,如果存在一个父节点就只有一个子节点,那么会将父节点和子节点合并。这样既可以减少存储空间,也可以提高查找效率。
Merkle tree

图片来自https://en.wikipedia.org/wiki/Merkle_tree
Merkle Tree,也叫哈希树 (hash tree)。叶子节点是数据块的hash值,而非叶节点是其对应子节点串联字符串的hash。
叶子节点,也就是最底层就是data blocks,将分块的数据(图中的L1 L2 L3 L4),分别计算hash。
非叶子节点,hash0-0由 hash(L1)得到,hash0-1由hash(L2)得到,那么hash0 则由hash(hash0-0 hash0-1)得到。由此往上计算,一直到root。
这样做的好处是什么呢?
1、好处就是当整个树中的其中任意一个节点发生变化,整个树都会发生变化。
2、当我要验证某个叶子节点的时候,不需要整个树,只需要与某个叶子节点相关的节点就可以进行验证。减少了下载量和计算量。
Merkle Patricia Trie
那么MPT呢,是以太坊中,自定义的数据结构。综合了Merkle Tree与Patricia Trie两个的特点。
那么看源码先吧。注:代码为github.com/ethereum/go-ethereum/trie,版本为1.0.0
这里为trie的整个mpt代码模块。 顺便说下,以太坊的源码结构,模块化非常好。
首先介绍node概念
github.com/ethereum/go-ethereum/trie/node.go

node interface定义
那么分了几类node
1、fullnode
github.com/ethereum/go-ethereum/trie/fullnode.go

-
trie指向的是root
-
一个容量为17的子节点。其中前16个代表的是0-9a-f的子节点索引,这个和trie树是一样的。第17个则用于保存该fullnode的数据。
-
dirty用于标识trie树是否发生变化。
fullnode用于无法合并的情况下的节点,那么会有完整的子节点索引(0-9a-f)。
2、shortnode
github.com/ethereum/go-ethereum/trie/shortnode.go

-
trie指向的是root
-
key是一个数组,这里的key则是和Patricia Trie中一样,属于合并节点,用于优化存储空间和查询效率。合并原则是当父节点只有一个子节点的时候,将其合并。
-
value指向的是一个节点。
-
dirty用于标识trie树是否有发生变化。
shortnode用于优化合并节点,所以其key是合并结果的key。
fullnode和shortnode为结构性节点,搞清楚这两个节点的区别,就基本上搞定了mpt的数据结构。
那么除了结构性节点,还需要数据节点。
1、valuenode
github.com/ethereum/go-ethereum/trie/valuenode.go

-
trie指向root
-
data为具体的数据
-
dirty用于标识trie树是否有发生变化。
valuenode很简单,只是用于存储value,无其他。
2、hashnode
github.com/ethereum/go-ethereum/trie/hashnode.go

-
key为hashnode保存的要索引的key。一般为这里的key对应的数据保存在数据库中,还未加载。
-
trie指向root
-
dirty用于标识trie树是否有发生变化。
当trie加载的时候,并不需要全部加载,未加载的部分,可以将其用hashnode表达。
valuenode和hashnode为数据节点,只用于存储value。并不参与结构性。
那么从功能上区分结构性节点和数据节点,就是此数据结构的重心。
结构性节点:
fullnode
shortnode
数据性节点
valuenode
hashnode
了解了结构后,那么就需要看流程了。
Trie结构
github.com/ethereum/go-ethereum/trie/trie.go

-
mu为锁
-
root为根node
-
roothash保存root对应的hash
-
cache用于保存node的cache
-
revisions为保存roothash的版本变化
New
创建一个新的Trie。这里的流程是这样的

51:创建一个结构体
52:初始化revisions,用于保存roothash,记录roothash变化
53:将root赋值给roothash(说明参数root是一个hash)
54-56:创建一个cache
58-61:当root为nil的时候,说明创建一个空的Trie。
当root不为nil的时候,说明为加载一个已经存在的Trie。
从最初的流程来看,应该是创建一个空的为最开始的。(这个很关键,是我们跟踪流程的起始)
插入分析
Update

131-132:锁操作
134:key的转换
136-139:当value不为空的时候,说明是要刷新节点或者插入一个新的节点。
创建一个valuenode,并dirty为true。
调用insert。
141:当value为空的时候,说明是要将节点删除,调用了delete。
insert

178-181:当node为nil的时候。
当我们的trie为空的时候,root就是为nil。那么第一次插入的时候,走的就是这个流程。
创建了shortnode。并将其返回了。
在Update函数中,trie的root会被赋值为这个shortnode。
那么第一次的插入就完成了。

再继续插入的话,执行流程就走到这里了。第一次插入的root肯定是一个shortnode。
186-193:对key进行判断,如果key与要插入的node的key是一致的话,只需要构建一个新的shortnode,进行替换即可。
下面的是很重要的插入流程。
196:变量k为插入节点node的node_key(为了区分变量),变量key为要被插入节点的node_key。计算其k和key的重合度。如过重合度相同则直接插入。
200-206:
说明k和key的长度不一样,那么需要将shortnode拆分裂变为两个。
pnode,nnode(这里面还有递归插入后续的动作)
而当前的node则替换成fullnode,并将两个子节点set到这个fullnode下。
208-210:这里判断匹配长度是不是为0,是则,此次递归就完成了。
212:如果递归还没未完成,说明还有遗留的部分key是无法匹配的,那么就创建一个shortnode来包容剩下的。
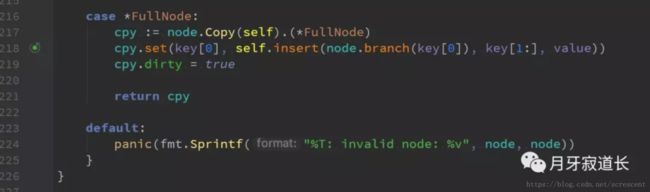
当插入节点处为fullnode的时候,插入就比较简单。
218:直接将其插入到fullnode中。
但也继续递归插入了剩下的部分。
查询分析
Get、GetString
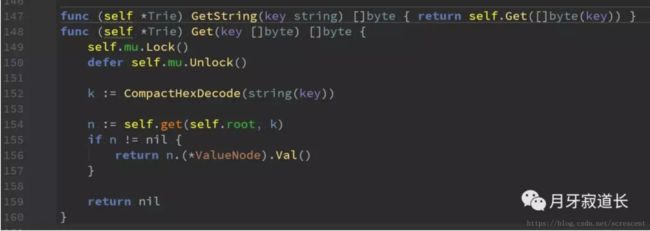
154:主要过程在这里掉用了get,从root节点开始查找

229:为退出的条件,当key被递归查询到为0的时候,则返回当前node。
237开始,根据类型进行不同的查找
239-246:shortnode,不断的进行key匹配查找,递归查询到最后的子节点。
248:递归查下下一个fullnode节点。

这个为fullnode子节点索引查找。
那么最重要的mpt的数据结构的插入和查询就完成了。如果能够把这些弄明白的话,那么就对mpt有了个很深刻的理解了。
本文的重点是对mpt有个简单的讲解。
在Trie源码中,还有cache、encoding、iterator代码,就不一一解释。
cache是一个简答的缓存,里面有封装了有db、map等。
encoding是一个编码的转换
iterator是一个迭代器
龚浩华
月牙寂道长
QQ 29185807
2018年08月31日
如果你觉得本文对你有帮助,可以转到你的朋友圈,让更多人一起学习。
第一时间获取文章,可以关注本人公众号:月牙寂道长,也可以扫码关注
