tensorflow实现LinearRegression
撰写时间:2017.5.18
这篇博文记录的是如何使用tensorflow实现LR,其中没有使用tensorflow提供的learn包里面的函数.因为如果使用函数包里面的API,不仅数据格式处理麻烦,而且扩展性不强.所以就自己实现了一下.
运行环境:ubuntu14.04,python2.7,tensorflow0.12
数据集:波士顿房价
loss:平方损失函数
优化方法:梯度下降
下面直接贴代码
1.文件处理的代码
文件处理的能力真的很弱,所以代码写的应该不怎么样,看看就行,只能保证运行
其中利用了sklearn包里面的数据处理函数.
#coding:utf-8
from __future__ import division
import sklearn
import numpy as np
from sklearn.model_selection import train_test_split
def read_data_housing():
# file = open("housing.data.txt",'r');
# for line in file:
# print line;
a = np.loadtxt("housing.data.txt");
data = a[:,0:-1];
target = a[:,-1];
keys = ['data','labels']
train = {}.fromkeys(keys);
test = {}.fromkeys(keys);
train['data'],test['data'],train['labels'],test['labels'] = train_test_split(data,target,
test_size = 0.4,random_state = 0);
return train,test
if __name__=='__main__':
read_housing_data();2.优化
#coding:utf-8
from __future__ import division
import tensorflow as tf
import numpy as np
import argparse
import os
import sys
import read_housing as rh
FLAGS = None
def inference(data):
with tf.name_scope('linearReg'):
weight = tf.Variable(tf.constant(0.1,shape = [FLAGS.dimension,1]),name = 'weights');
bias = tf.Variable(tf.zeros(1),name = 'bias');
logits = tf.matmul(data,weight)+bias;
return logits;
def loss(labels,logits):
loss = tf.sqrt(tf.reduce_mean(tf.square(labels - logits)));
return loss;
def training(loss,learning_rate):
with tf.name_scope('loss'):
tf.summary.scalar('loss_func',loss);
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(loss);
return train_op;
def fill_feed_dict(data_set,data_placeholder,labels_placeholder):
feed_dict = {
data_placeholder:data_set['data'],
labels_placeholder:data_set['labels']
}
return feed_dict;
def train_running():
train_set,test_set=rh.read_data_housing();
FLAGS.dimension = train_set['data'].shape[1];
data = tf.placeholder(tf.float32,shape = [None,FLAGS.dimension]);
labels = tf.placeholder(tf.float32,shape = [None]);
#logits:prefict value.
logits = inference(data);
square_loss = loss(labels,logits);
train_op = training(square_loss,FLAGS.learning_rate);
init = tf.global_variables_initializer();
summary = tf.summary.merge_all();
sess = tf.Session();
summary_writer = tf.summary.FileWriter(FLAGS.logdir,sess.graph);
sess.run(init);
for step in range(1000):
feed_dict = fill_feed_dict(train_set,data,labels);
sess.run(train_op,feed_dict = feed_dict);
if(0==step%100):
print ("square loss %d: %f" %(step,square_loss.eval(session = sess,feed_dict = feed_dict)));
summary_str = sess.run(summary,feed_dict = feed_dict);
summary_writer.add_summary(summary_str,step);
summary_writer.flush();
feed_dict = fill_feed_dict(test_set,data,labels)
print ("square loss : %f" %(square_loss.eval(session = sess,feed_dict = feed_dict)));
def main(_):
if tf.gfile.Exists(FLAGS.logdir):
tf.gfile.DeleteRecursively(FLAGS.logdir);
tf.gfile.MakeDirs(FLAGS.logdir);
train_running();
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--logdir',
type = str,
default = '/tmp/tensorflow/hoston/logs/linear_reg',
help = 'Directory of tensorboard log file'
)
parser.add_argument(
'--learning_rate',
type = float,
default = 1e-6,
help = 'learning rate')
parser.add_argument(
'--dimension',
type = int,
help ='Dimension of samples')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)结果
1.tensorboard的流程图
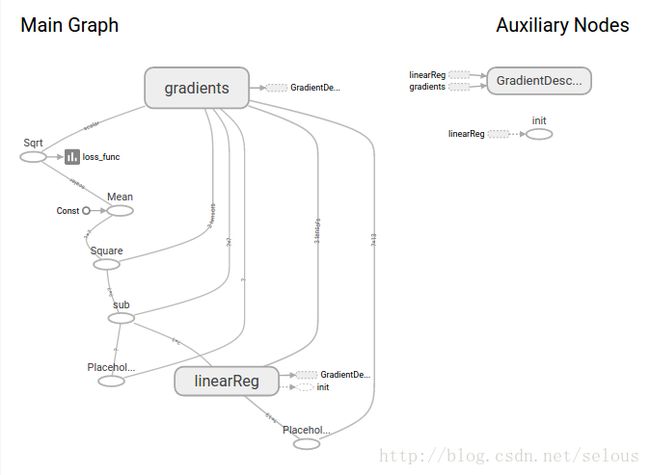
2.tensorboard的loss函数

3.平方损失函数

感觉损失挺高,不知道是我的代码问题,还是模型的泛化能力太弱.
打算试一下特征工程.提取几个主要的特征.或者结合DNN做一下.
还有一个问题就是学习率的问题.不知道这个学习率为什么这么小,设大了误差特别大…