MapReduce作业在YARN的内存分配设置
教程目录
- 0x00 教程内容
- 0x01 内存分配设置
- 1. 目前YARN配置情况
- 2. 配置MapReduce配置文件
- 0x02 校验结果
- 1. 重新执行MapReduce作业
- 2. 查看作业执行情况
- 0xFF 总结
0x00 教程内容
- 内存分配设置
- 校验结果
0x01 内存分配设置
1. 目前YARN配置情况
a. 首先启动HDFS与YARN
start-dfs.sh
start-yarn.sh
b. 打开master的8088端口
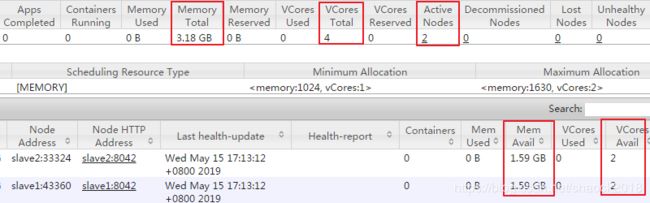
可以看到我们之前的配置,请参考:YARN与MapReduce的配置与使用
YARN总管理内存:3.18GB(两个从节点都是1.59G),
虚拟CPU:4个(我们配置虚拟机的时候配的,每台虚拟机2个CPU),
活的节点:2个(slave1、slave2)
2. 配置MapReduce配置文件
a. 主要配置三个进程:
MRAppMaster
MapTask
ReduceTask
(每个进程3个配置:总内存、堆内存、虚拟CPU)
b. 添加以下配置 mapred-site.xml
cd $HADOOP_HOME/etc/hadoop
vi mapred-site.xml
<property>
<name>yarn.app.mapreduce.am.resource.mbname>
<value>1200value>
<description>表示MRAppMaster需要的总内存大小,默认是1536description>
property>
<property>
<name>yarn.app.mapreduce.am.command-optsname>
<value>-Xmx800mvalue>
<description>表示MRAppMaster需要的堆内存大小,默认是:-Xmx1024mdescription>
property>
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcoresname>
<value>1value>
<description>表示MRAppMaster需要的的虚拟cpu数量,默认是:1description>
property>
<property>
<name>mapreduce.map.memory.mbname>
<value>512value>
<description>表示MapTask需要的总内存大小,默认是1024description>
property>
<property>
<name>mapreduce.map.java.optsname>
<value>-Xmx300mvalue>
<description>表示MapTask需要的堆内存大小,默认是-Xmx200mdescription>
property>
<property>
<name>mapreduce.map.cpu.vcoresname>
<value>1value>
<description>表示MapTask需要的虚拟cpu大小,默认是1description>
property>
<property>
<name>mapreduce.reduce.memory.mbname>
<value>512value>
<description>表示ReduceTask需要的总内存大小,默认是1024description>
property>
<property>
<name>mapreduce.reduce.java.optsname>
<value>-Xmx300mvalue>
<description>表示ReduceTask需要的堆内存大小,默认是-Xmx200mdescription>
property>
<property>
<name>mapreduce.reduce.cpu.vcoresname>
<value>1value>
<description>表示ReduceTask需要的虚拟cpu大小,默认是1description>
property>
c. 同步 mapred-site.xml 到slave1、slave2:
scp mapred-site.xml hadoop-sny@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop
scp mapred-site.xml hadoop-sny@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop
0x02 校验结果
1. 重新执行MapReduce作业
a. 执行作业
hadoop jar ~/jar/hadoop-learning-1.0.jar com.shaonaiyi.hadoop.WordCount hdfs://master:9999/files/put.txt hdfs://master:9999/output/wc/
参考教程:MapReduce入门例子之WordCount单词计数 的0x01 单词计数1. 操作流程
说明:因为MapReduce的配置没有重启的概念,每次执行都会加载,所以不用重启HDFS和YARN
2. 查看作业执行情况
a. 刷新几次YARN的WebUI界面(master:8088)
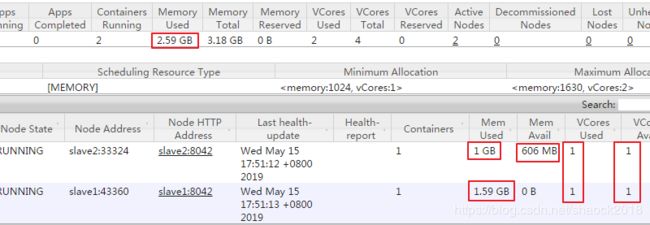

b. 点开作业,可以看到我是写了一个MapTask、三个ReduceTask,作业不同,结果可能不同。
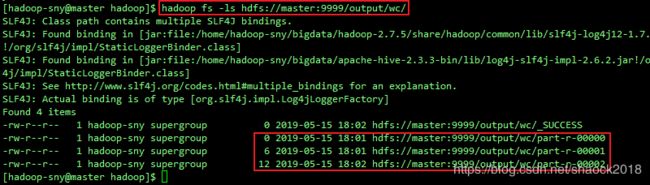
如在执行WordCount作业时,出现虚拟内存不足情况,请调大YARN虚拟内存:
=> 配置 yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>4value>
<description>yarn虚拟内存和物理内存的比率,默认是2.1description>
property>
然后同步到slave1、slave2节点。
0xFF 总结
- 这些配置是比较基础的,也是比较重要的。
- 需要清楚前面我们的教程是怎样配置的,才有利于我们现在为什么是这样的。
- 查看我们之前的配置,请参考教程:YARN与MapReduce的配置与使用
- 此教程的配置是通过配置文件的方式配置的,我们也可以通过代码的方式来制定:
job.getConfiguration().set("yarn.app.mapreduce.am.resource.mb", "512");
job.getConfiguration().set("yarn.app.mapreduce.am.command-opts", "-Xmx250m");
job.getConfiguration().set("yarn.app.mapreduce.am.resource.cpu-vcores", "1");
job.getConfiguration().set("mapreduce.map.memory.mb", "400");
job.getConfiguration().set("mapreduce.map.java.opts", "-Xmx200m");
job.getConfiguration().set("mapreduce.map.cpu.vcores", "1");
job.getConfiguration().set("mapreduce.reduce.memory.mb", "400");
job.getConfiguration().set("mapreduce.reduce.java.opts", "-Xmx200m");
job.getConfiguration().set("mapreduce.reduce.cpu.vcores", "1");
job.getConfiguration().set("mapreduce.job.queuename", "eng");
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
复制粘贴玩转大数据系列专栏已经更新完成,请跳转学习!